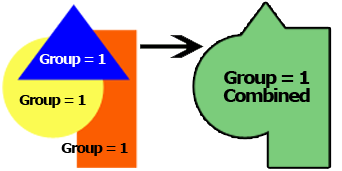
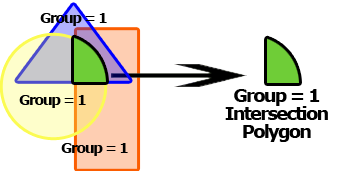
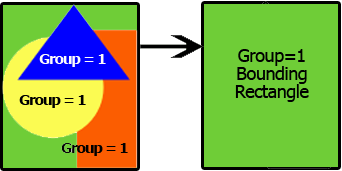
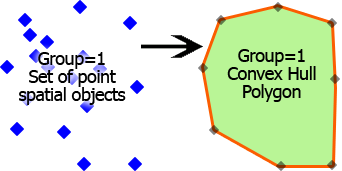
正味現在価値: グループの正味現在価値を計算します。 資金調達が満たされると、現在の金額でキャッシュフローの超過または不足を測定します。
-
NPVプロパティ: 割引率(期間ごと)を%で指定します
日付の入った正味現在価値: 一連の日付のグループに対して正味現在価値を計算します。
-
XNPVのプロパティ: 融資利率を%で指定し、使用可能なフィールドのドロップダウンリストから日付フィールドを選択します。
内部収益率(IRR): グループの内部収益率を計算します。 投資の内部収益率は、投資のコストが投資の利益につながる金利です。 これは、投資から得られるすべての利益は金銭の時間価値に固有であり、投資にはこの金利でゼロの正味現在価値があることを意味します。
内部収益率の日付: 一連の日付のグループの内部収益率を計算します。
-
XIRRのプロパティ: 使用可能なフィールドのドロップダウンリストから「日付」フィールドを選択します。
修正された内部収益率(MIRR): 内部収益率の修正などは、IRRに関するいくつかの問題を解決することを目指しています。 MIRRは、投資の魅力の財務的指標です。
-
MIRRのプロパティ: 財務比率を%で指定し、再投資率を%で指定します。
変更された日付付き内部返還レート(MXIRR): 一連の日付のグループの修正された内部収益率を計算します。
-
MXIRRのプロパティ: 融資利率を%で指定し、再投資立を%で指定し、使用可能なフィールドのドロップダウンリストから「日付」フィールドを選択します。
*財務の定義はWikipediaに由来します: http://en.wikipedia.org