
インデータベースの概要
インデータベース内処理により、データをデータベースから移動せずにデータの大きなセットに対して混合と分析が可能になり、処理のために個別環境にデータを移動する必要のある従来の分析メソッドに比べてパフォーマンスが大幅に向上します。
データベースで分析を実行すると、処理時間を節約できます。 Alteryx Designerをインターフェースとして使用することで、インデータベースワークフローは標準的なワークフローと容易に統合され、データ混合と分析を追加で行うことが可能になります。
空間オブジェクトは現在、[インデータベース]ツールではサポートされていません。
- インデータベース処理には、64ビットデータベースドライバを組み込んだ64ビットAlteryxが必要です。
- Alteryx Serverでワークフローを実行するには、ODBCドライバをSystem DSNとして構成する必要があります。 インデータベース処理の場合は、ODBC接続がシステムDSNとして構成されていることに加えて、接続タイプを「システム」にする必要があります。
参照: サポートされたデータソース Alteryx でサポートされているデータプラットフォームの完全なリストについて。
参照: 予測分析 データベース内の予測サポートの詳細については
| ツール名 | ツールの説明 | |
|---|---|---|
|
|
閲覧(In-DB)ツール | In-DBワークフローの任意のポイントでデータを確認します。 注: 各 DB の参照は、データベースクエリをトリガーし、パフォーマンスに影響を与える可能性があります。 |
|
|
接続(In-DB)ツール | In-DBワークフローのデータベース接続を確立します。 |
|
|
データストリームインツール | 標準ワークフローのデータをIn-DBワークフローに取り込みます。 |
|
|
データストリームアウトツール | レコードをソートするオプションで、In-DBワークフローから標準のワークフローにデータをストリームします。 |
|
|
動的入力(In-DB)ツール | In-DBの接続名とクエリフィールドを標準のデータストリームから取り出し、In-DBのデータストリームに入力します。 |
|
|
動的出力(In-DB)ツール | In-DBワークフローに関する情報を予測In-DBの標準ワークフローに出力します。 |
|
|
フィルタ(In-DB)ツール | データベースのネイティブ言語(SQLなど)を使用して、基本フィルタまたはカスタム式を使用してIn-DBレコードをフィルタリングします。 |
|
|
式(In-DB)ツール | データベースのネイティブ言語(SQLなど)を用いた式によってIn-DBデータストリーム内のフィールドを作成または更新します。 |
|
|
ジョイン(In-DB)ツール | 内部または外部結合を実行して、共通フィールドに基づいて2つのIn-DBデータストリームを結合します。 |
|
|
マクロ入力(In-DB)ツール | マクロにIn-DB入力接続を作成し、プレースホルダ値を設定します。 |
|
|
マクロ出力(In-DB)ツール | マクロにIn-DB出力接続を作成します。 |
|
|
サンプル(In-DB)ツール | In-DBデータストリームをレコードの数または割合で制限します。 |
|
|
選択(In-DB)ツール | In-DBワークフローでフィールドの選択、選択解除、並べ替え、名前の変更を行います。 |
|
|
サマライズ(In-DB)ツール | グループ化、集計、カウント、特徴のあるフィールドのカウントなどによるサマライズIn-DBデータ 出力には、計算結果のみが含まれます。 |
|
|
転置(In-DB)ツール | In-DBワークフローでデータテーブルの向きをピボットします。 垂直軸上の水平データフィールドを表示できるようにデータを変換します。 |
|
|
ユニオン(In-DB)ツール | フィールド名または位置に基づいて、類似の構造を持つ2つ以上のIn-DBデータストリームを結合します。 出力には、各列に各入力のデータが格納されます。 |
|
|
書き込みデータ(In-DB)ツール | In-DBデータストリームをデータベース内で直接テーブルを作成または更新する際に使用します。 |
| ツール名 | ツールの説明 | |
|---|---|---|
|
|
ブーストモデルツール | ブーストモデルはフリードマンの勾配ブースティングメソッドに基づいて、一般化されたブースト回帰モデルを作成します。 |
|
|
決定木ツール | [決定木]ツールは一連のif-then分割ルールを組み立ててモデルを作成する基準を最適化し、1つ以上の予測変数を使用してターゲット変数を予測します。 |
|
|
フォレストモデルツール | フォレストモデルツールは1つのモデルを作成し、1つ以上の予測変数に基づいて、ターゲット変数を予測する一連の決定木モデルを構築します。 |
|
|
線形回帰ツール | [線形回帰]ツールは線形機能を組み立ててモデルを作成し、1つ以上の予測変数に基づいてターゲット変数を予測します。 |
|
|
ロジスティック回帰 | [ロジスティック回帰]ツールは、ターゲットバイナリ変数(yes / no、pass / failなど)を1つ以上のプレディクタ変数に関連付けるモデルを作成し、ターゲット変数それぞれに対して2つの可能な応答の推定確率を取得します。 |
|
|
スコアリングツール | [スコアリング]ツールはモデルを評価して予測フィールド、またはスコアリングを作成し、モデルによって予測された値の精度を推定します。 |
インデータベースでサポートされる予測ツールが別のIn-DBツールを使用してキャンバスに配置されると、予測ツールはIn-DBバージョンに自動的に変更されます。 ツールのバージョンを手動で変更するには:
- ツールを右クリックします。
- ポイントしてツールバージョンを選択します。
- ツールの別のバージョンをクリックします。
参照: 予測分析 データベース内の予測サポートの詳細については
インデータベースワークフロー処理はデータベース内で行われるため、[インデータベース]ツールは標準のAlteryxツールと互換性がありません。 いくつかの視覚インジケータは接続互換性を示します。
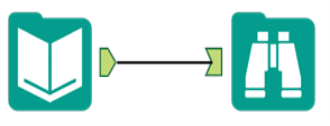
標準的なツールは、緑の矢印のアンカーを使用して別のツールに接続します。 接続は1行として表示されます。 |
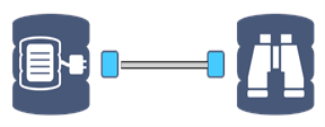
[インデータベース]ツールは、青い四角形のデータベースアンカーを使用して、別の[インデータベース]ツールに接続します。 2つの[インデータベース]ツール間の接続は、二重線として表示されます。 インデータベース処理の性質上、接続の進捗接続進捗状況状況は表示されません。 |
標準のツールを[インデータベース]ツールに接続するには、[動的入出力]ツールまたは[データストリーム]ツールを使用します。
データは[データストリームイン]と[データストリームアウト]ツールを使用して、または[接続(In- DB)]ツールを使用してデータベースに直接接続することで、インデータベースワークフローに流れ込んだり、または流れ出していきます。 [データストリームイン]と[データストリームアウト]ツールはIn-DBアンカーを使用して[In-DB]ツールに接続し、標準のワークフローアンカーを使用して標準のワークフローツールに接続します。
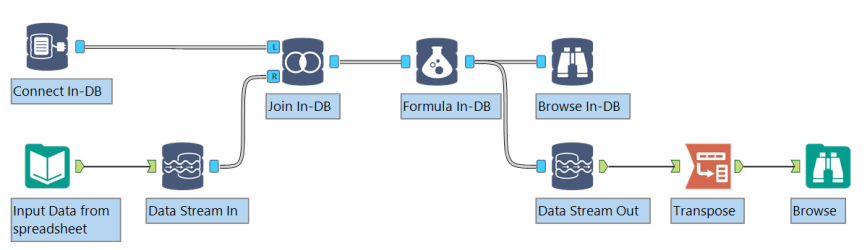
- [接続(In-DB)]ツールを使用してデータベースへの接続を定義するか、または[データストリームイン]ツールを使用して、標準ワークフローからデータをデータベースの一時テーブルにストリーミングします。
- 他の[インデータベース]ツールをワークフローに接続してデータを処理します。
- [書き込みデータ(In-DB)]ツールを使用して、インデータベースのテーブルを作成または更新したり、または[データストリームアウト]ツールを使用してIn-DBの結果を標準処理用のワークフローにストリーミングします。
- ワークフローを実行して、データプラットフォーム内のデータを処理します。 完全なインデータベースワークフローが処理されるまで、結果はAlteryx Engineに返されません。
大量のデータがデータベースの内および外でストリーミングされると、ワークフロー処理に時間がかかることがあります。 インデータベース処理を使用すると、ワークフローを高速化できます。
たとえば、標準のワークフローでは、大きなデータベーステーブルがメモリに引き込まれ、小さなスプレッドシートで結合されます。 実行時間の大部分は、データベースレコードへのにストリーミングに費やされます。 インデータベースワークフローでは、小さなスプレッドシートがデータベースにストリーミングされ、実行時間が大幅に短縮されます。
基本的なデータベースにアクセスするには、読取り権限が必要です。
データベースにテーブルを作成するには、書き込み権限が必要です。
一時テーブルは、実行の終了時に削除されます。 [データストリームイン]ツールの実行中にAlteryxがクラッシュした場合、インデータベースワークフローを次に実行すると、それまでの3日間でデータベース内のAlteryxによって作成されたすべての一時ファイルが消去されます。
セッション間で一時テーブルを見えるようにするには、ワークフローの最後で結局は削除される永久テーブルを作成する必要があります。 データベースからデータにストリーミングし、データベースにデータを書き込むには「作成」権限を持つ必要があります。 例外はMicrosoft SQL Serverです。
基本的なルールは、標準の[入力データ]ツールと[出力データ]ツールを介したデータベース接続と同じように、プロセス中も維持されます。 データベースのタイムアウトがある場合や、実行可能な日ごとのクエリの数に制限がある場合は、データベースへの接続に影響が及びます。
選択ステートメントは[接続(In-DB)]ツールによってトリガーされ、追加のクエリはダウンストリームツールによって作成され、このクエリ内にネストされます。 次の3つのツールのいずれかを追加すると、クエリが完了し、基になるデータベースに送信されます。-db での書き込み、データストリームアウト、ブラウズ-db。
[接続(In-DB)]ツールの[クエリ]ボックスに独自のSQLステートメントを入力し、選択ステートメントに埋め込むこともできます。
基本的なデータベースのSQLクエリは、各閲覧(In-DB)、データストリームアウト、または[書き込みデータ(In-DB)]ツールの実行時にトリガーされます。
[データ閲覧(In DB)]ツールはワークブックの実行時に、.yxdbファイルとしてデータをキャッシュするように構成できます。
データがキャッシュされると、ワークフローが再実行され、データベース接続またはクエリ(閲覧するレコードの数を含む)が変更されていない場合、クエリは再実行されません。 代わりに、データはキャッシュから引き出されされます。
出力メッセージは、データがキャッシュされたかどうかを示します。 このリンクをクリックすると、データ結果が.yxdbファイルとして個別のウィンドウに表示されます。
インデータベースのキャッシュは、アップストリームツールに変更を加えることなくワークフローが再実行されるたびに使用されます。 アップストリームツールを変更すると新しいクエリがトリガーされ、新しいキャッシュが作成されます。
いいえ、[最初の[100]レコードを閲覧する]オプションは、[閲覧(In-DB)]ツールに表示されるレコード数のみを制限します。 ワークフローの他のツールは、任意のポイントで通過するレコードの数を処理します。
フィールドにはCLOB / LOBデータ型があり、フィルタまたは[式]ツールの比較演算子のほとんどでは機能しません。 このエラーは、たとえデータが比較と一致したとしても、列が返されないことを反映しています。 これは、LOBデータとの比較をサポートしていないため、SQLおよびOracleでは予想される行動です。