
In-Database Overview
In-database processing enables blending and analysis against large sets of data without moving the data out of a database, which can provide significant performance improvements over traditional analysis methods that require data to be moved to a separate environment for processing.
Performing analysis in the database can save processing time. Using Alteryx Designer as the interface, in-database workflows integrate with standard workflows for additional data blending and analysis.
Spatial objects are currently not supported with In-Database tools.
- In-database processing requires 64-bit Alteryx with 64-bit database drivers.
- To run workflows on Alteryx Server, the ODBC driver must be configured as a System DSN. For in-database processing, the Connection Type must be "System" in addition to the ODBC connection being configured as a System DSN.
| In-Database Support | Predictive In-Database Support |
|---|---|
| Amazon Redshift | |
| Apache Spark ODBC | |
| Cloudera Impala | |
| Databricks | |
| EXASOL | |
| Hive | |
| HP Vertica | |
| IBM Netezza | |
| Microsoft Analytics Platform System | |
| Microsoft Azure SQL Database | |
| Microsoft Azure SQL Data Warehouse | |
| Microsoft SQL Server | Yes (2016) |
|
|
|
| Oracle | Yes |
| Pivotal Greenplum | |
| PostgreSQL | |
| SAP Hana | |
| Snowflake | |
| Teradata | Yes |
See Supported Data Sources and File Formats for the full list of data platforms supported by Alteryx.
See Predictive Analytics for more about predictive in-database support.
| Tool Name | Tool Description | |
|---|---|---|
|
|
Browse In-DB Tool | Review your data at any point in an In-DB workflow. Note: Each In-DB Browse triggers a database query and can impact performance. |
|
|
Connect In-DB Tool | Establish a database connection for an In-DB workflow. |
|
|
Data Stream In Tool | Bring data from a standard workflow into an In-DB workflow. |
|
|
Data Stream Out Tool | Stream data from an In-DB workflow to a standard workflow, with an option to sort the records. |
|
|
Dynamic Input In-DB Tool | Take In-DB Connection Name and Query fields from a standard data stream and input them into an In-DB data stream. |
|
|
Dynamic Output In-DB Tool | Output information about the In-DB workflow to a standard workflow for Predictive In-DB. |
|
|
Filter In-DB Tool | Filter In-DB records with a Basic filter or with a Custom expression using the database’s native language (e.g., SQL). |
|
|
Formula In-DB Tool | Create or update fields in an In-DB data stream with an expression using the database’s native language (e.g., SQL). |
|
|
Join In-DB Tool | Combine two In-DB data streams based on common fields by performing an inner or outer join. |
|
|
Macro Input In-DB Tool | Create an In-DB input connection on a macro and populate it with placeholder values. |
|
|
Macro Output In-DB Tool | Create an In-DB output connection on a macro. |
|
|
Sample In-DB Tool | Limit the In-DB data stream to a number or percentage of records. |
|
|
Select In-DB Tool | Select, deselect, reorder, and rename fields in an In-DB workflow. |
|
|
Summarize In-DB Tool | Summarize In-DB data by grouping, summing, counting, counting distinct fields, and more. The output contains only the result of the calculation(s). |
|
|
Transpose In-DB Tool | Pivot the orientation of a data table in an In-DB workflow. It transforms the data so you may view horizontal data fields on a vertical axis. |
|
|
Union In-DB Tool | Combine two or more In-DB data streams with similar structures based on field names or positions. In the output, each column will contain the data from each input. |
|
|
Write Data In-DB Tool | Use an In-DB data stream to create or update a table directly in the database. |
| Tool Name | Tool Description | |
|---|---|---|
|
|
Boosted Model Tool | The Boosted Model tool provides generalized boosted regression models based on the gradient boosting methods of Friedman. |
|
|
Decision Tree Tool | The Decision Tree tool constructs a set of if-then split rules that optimize a criteria to create a model that predicts a target variable using one or more predictor variables. |
|
|
Forest Model Tool | The Forest Model tool creates a model that constructs a set of decision tree models to predict a target variable based on one or more predictor variables. |
|
|
Linear Regression Tool | The Linear Regression tool constructs a linear function to create a model that predicts a target variable based on one or more predictor variables. |
|
|
Logistic Regression Tool | The Logistic Regression tool creates a model that relates a target binary variable (such as yes/no, pass/fail) to one or more predictor variables to obtain the estimated probability for each of two possible responses for the target variable. |
|
|
Score Tool | The Score tool evaluates a model and creates an assessment field, or score, that estimates the accuracy of the values predicted by the model. |
When a predictive tool with in-database support is placed on the canvas with another In-DB tool, the predictive tool automatically changes to the In-DB version. To manually change the version of the tool:
- Right-click the tool.
- Point to Choose Tool Version.
- Click a different version of the tool.
See Predictive Analytics for more about predictive in-database support.
Since in-database workflow processing occurs within the database, the In-Database tools are not compatible with the standard Alteryx tools. Several visual indicators show connection compatibility.

Standard tools use a green arrow anchor to connect to another tool. The connection displays as a single line. |
In-Database tools use a blue square database anchor to connect to another In-Database tool. The connection between two In-Database tools displays as a double line. Due to the nature of in-database processing, connection progress is not displayed. |
To connect standard tools to In-Database tools, use the Dynamic Input and Output tools or the Data Stream tools.
Data is streamed into and out of an in-database workflow using the Data Stream In and Data Stream Out tools, or by connecting directly to a database using the Connect In-DB tool. The Data Stream In and Data Stream Out tools use an In-DB anchor to connect to In-DB tools, and a standard workflow anchor to connect to standard workflow tools.
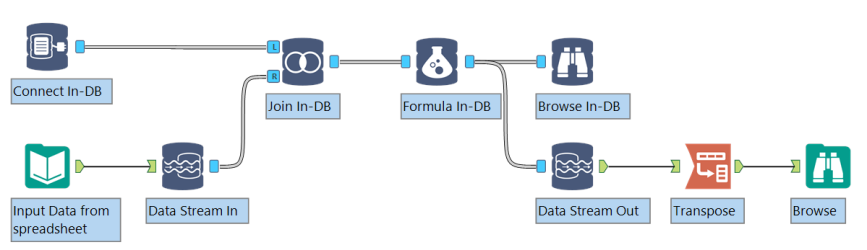
- Define the connection to the database using the Connect In-DB tool, or use the Data Stream In tool to stream data from a standard workflow into a temporary table in the database.
- Connect other In-Database tools to the workflow to process the data.
- Use the Write Data In-DB tool to create or update a table in the database, or use the Data Stream Out tool to stream the In-DB results to a workflow for standard processing.
- Run the workflow to process the data in the data platform. No results are returned to the Alteryx Engine until the complete in-database workflow has been processed.
Workflow processing can take longer when a large amount of data is streamed in and out of a database. In-database processing can be used to speed up a workflow.
For example, in a standard workflow, a large database table is pulled into memory to be joined with a small spreadsheet. The majority of run time is spent streaming in the database records. In an In-Database workflow, the small spreadsheet is streamed into the database, reducing run time substantially.
Read privileges are required to access the underlying database.
Write privileges are required to create a table in the database.
The temporary tables are deleted at the end of the run. If Alteryx crashes while the Data Stream In tool is being run, then the next time that an in-database workflow is run, all temp files created by Alteryx in the database in the previous three days are cleaned out.
To allow visibility of a temporary table across sessions, Alteryx must create a permanent table that is eventually deleted at the end of a workflow. It is necessary to have CREATE permissions to stream in data from a database and write data to a database. The exception is Microsoft SQL Server.
The underlying rules are maintained during the process the same as with the database connections via the standard Input Data and Output Data tools. If there is a database timeout or if there is a limit to the number of queries per day that you can run, it will affect your connection to the database.
A SELECT statement is triggered by the Connect In-DB tool and additional queries are created by downstream tools and nested within this query. The addition of one of the following three tools completes the query and sends it to the underlying database: Write In-DB, Data Stream Out, Browse In-DB.
You can input your own SQL statement in the Query box for the Connect In-DB tool, which also gets embedded within the SELECT statement.
The SQL query for the underlying database is triggered at runtime for each Browse In-DB, Data Stream Out or Write Data In-DB tool.
The Browse Data In-DB tool can be configured to cache the data as a .yxdb file when the workflow is run.
Once the data is cached, if the workflow is re-run and the database connection or query (including the number of records to browse) has not changed, the query will not be re-run. Instead, the data will be pulled from the cache.
An output message indicates whether or not the data was cached. Clicking the link will open the data results as a .yxdb file in a separate window.
The in-database cache is used any time a workflow is re-run without changes to upstream tools. Making a change to any upstream tool will trigger a new query and a new cache will be created.
No, the “Browse first [100] records” option only limits the number of records displayed in the Browse In-DB tool. Other tools in the workflow will process the number of records that pass through at any given point.
The field has CLOB/LOB datatype and will not work with most of the comparison operators in the Filter or Formula tools. The error reflects that no columns are returned, even when the data matches the comparison. This is expected behavior with SQL and Oracle, as they do not support comparisons with LOB data.