Opções de formato de arquivo
As opções de configuração variam de acordo com a conexão de banco de dados ou o formato de arquivo que você usa para fazer a entrada ou a saída dos dados. Selecione as opções de formato de arquivo nestas ferramentas: ferramenta Dados de Entrada , ferramenta Dados de Saída , ferramenta Conectar In-DB , ferramenta Entrada do Fluxo de Dados , ferramenta Gravar Dados In-DB .
Opção | Descrição | Formatos de arquivo |
|---|---|---|
Permitir a extração de arquivos com mais de 2 GB | Selecione para permitir que o Alteryx extraia um arquivo superior a 2 GB. Consulte Suporte a arquivos Zip e Suporte a arquivos Gzip . | .zip, *.gz, *.tgz |
Permitir acesso compartilhado para gravação | Selecione para ler um arquivo aberto que possa estar em processo de atualização. Essa opção destina-se à leitura de logs da Web. | |
Agregar à tabela existente | Selecione para adicionar registros a uma tabela existente. | .dbase, .sdf |
Agregar mapa de campos | Selecione para agregar campos e definir como os campos de saída serão mapeados para os campos na tabela OLEDB. | .mdb, .xls, .accdb, ODBC, OLEDB |
Página de código | Selecione uma página de código para converter texto dentro de dados de entrada ou saída. Consulte Páginas de código . | .csv, .dbf, .flat, .json, .mid, .mif, .tab, .shp |
Criar campos Int32 como binários | Selecione para criar todos os campos Int32 como valores binários de 32 bits (4 bytes) no banco de dados em vez do formato de texto padrão de 11 caracteres. Essa opção não é compatível com todos os leitores DBF. | .dbase |
Delimitador | Selecione o delimitador de campo nos dados. Use \0 para ler ou gravar um arquivo de texto sem delimitador. Use 0 caso os dados tenham dois ou mais delimitadores, forçando o Designer a ler os dados como texto simples. Use a ferramenta RegEx no modo "Tokenizar" para separar seus dados. | .csv, .txt |
Arquivo de dados ou descrição | Defina o nome de um arquivo .flat usado como um arquivo de layout. | .flat |
Não mostrar % de conclusão | Selecione para desabilitar o relatório de status de leitura de arquivos em andamento; isso acelera o tempo da leitura. | |
Habilitar compactação (deflate) | Selecione para gravar um arquivo .avro compactado. O algoritmo "deflate" (semelhante ao gzip) é usado e deve ter suporte em outras ferramentas capazes de operar no Avro, como Hive. A compactação aumenta o tempo de saída, porém, com arquivos maiores, reduz o tempo de rede. | .avro |
Habilitar suporte para FileTable do SQL Server | Selecione para gravar um arquivo do Excel em uma tabela de arquivos do Microsoft SQL Server (FileTable). | .xlsx |
Expandir rótulos de valor | Leia e aplique rótulos de valor (chave) aos dados. Essa opção é selecionada por padrão para arquivos SPSS e SAS. Consulte Formatos de arquivo Stat Transfer com suporte . Se esta opção não estiver selecionada, apenas a chave de valor é exibida. | .spss, .sas |
Comprimento do campo | Defina o comprimento máximo do campo nos dados de entrada. | |
Formato de arquivo | Selecione o formato do arquivo de dados. | todos os formatos |
Arquivo no arquivo morto | Altere o arquivo (ou arquivos) para entrada. Consulte Suporte a arquivos Zip . | .zip |
A primeira linha contém dados | Marque essa caixa de seleção caso a primeira linha deva ser tratada como dados, não como cabeçalho. | .xlsx |
A primeira linha contém o nome dos campos | Marque essa caixa de seleção caso a primeira linha deva ser tratada como cabeçalho. | .csv |
Forçar compatibilidade com SQL WChar | Selecione para permitir que colunas do tipo cadeia de caracteres sejam tratadas como SQL_WCHAR, SQL_WVARCHAR ou SQL_WLONGVARCHAR. | .oci, unicode.txt |
Se linhas longas forem permitidas | Use o arquivo .flat selecionado (padrão) ou substitua a configuração. | .flat |
Se linhas curtas forem permitidas | Use o arquivo .flat selecionado (padrão) ou substitua a configuração. | .flat |
Ignorar delimitadores entre | Selecione uma opção: Aspas : ignorar delimitadores entre aspas. Aspas simples : ignorar delimitadores entre aspas simples. Automático : ignorar delimitadores detectados automaticamente. Nenhum : não ignorar delimitadores. | |
Ignorar erros de XML e continuar | Ignore formatação XML incorreta e continue executando o fluxo de trabalho. Consulte Leitura de XML . | .xml |
Estilo de fim de linha | Defina o caractere ou a sequência de caracteres que indica o final de uma linha de texto. | .csv, .flat |
Máx. de registros por arquivo | Defina o número de registros a serem enviados para um único arquivo. Se os dados contiverem mais registros, múltiplos arquivos serão criados e nomeados sequencialmente. | todos os formatos |
Sem índice espacial | Marque essa caixa de seleção para desativar o índice espacial. Só use isso ao gravar arquivos temporários grandes que não serão usados em operações espaciais. Essa opção grava arquivos menores mais rapidamente. | .yxdb |
Gerar todos os campos como cadeias de caracteres | Selecione para converter campos de entrada em dados do tipo cadeia de caracteres; isso ignora erros de conversão se o tipo de dados estiver errado em arquivos .dbf. | .dbf |
Gerar campo com o nome do arquivo | Selecione para acrescentar um campo com o nome ou o caminho do arquivo a cada registro. | |
Opções de saída | Selecione uma opção de saída: Criar nova planilha : cria uma nova planilha, mas não substitui uma já existente. Acrescentar à planilha existente : acrescenta dados a uma planilha existente de modo que a saída contenha os dados novos e os anteriores. Substituir planilha ou intervalo : exclui os dados anteriores da planilha ou do intervalo selecionado e grava os novos dados na planilha ou no intervalo com o nome selecionado. Não use a opção acima caso o arquivo do Excel contenha fórmulas, tabelas, gráficos e imagens, pois esses itens podem ser corrompidos. Substituir arquivo (remover) : exclui o arquivo existente e cria um novo. | .xlsx, .xlsm (por meio do driver .xlsx do Alteryx) |
Opções de saída | Selecione uma opção de saída: Criar nova tabela : cria uma nova tabela, mas não substitui uma já existente. Agregar existente : agrega dados a uma tabela existente de modo que a saída contenha os registros anteriores e os novos. Excluir dados e agregar : exclui todos os registros originais da tabela e acrescenta os dados à tabela existente. Substituir tabela (descartar) : descarta a tabela existente e cria uma nova. | .accdb, .mdb, .tde, .xls, .xlsx (por meio do driver .xlsx herdado), .oci, OLEDB, ODBC |
Opções de saída | Selecione uma opção: Atualizar; gerar aviso em caso de falha : atualiza os registros existentes usando a saída e avisa se um registro não puder ser atualizado. Atualizar; gerar erro em caso de falha : atualiza os registros existentes usando a saída e interrompe o processamento se um registro não puder ser atualizado. Atualizar; inserir se novo : atualiza os registros existentes usando a saída, insere novos registros se eles não estavam na tabela do banco de dados e interrompe o processamento se um registro não puder ser atualizado. O campo de chave primária precisa ser incluído para que a atualização funcione. Se houver múltiplos registros com a mesma chave primária e nenhum outro erro de SQL ocorrer, o novo registro atualizará o registro mais antigo no banco de dados. Use a ferramenta Exclusivo para verificar se há múltiplas chaves primárias antes de gravar no banco de dados. | .oci, OLEDB, ODBC |
Substituir tabela existente | Selecionada por padrão, essa opção substitui um tipo de arquivo existente de mesmo nome. | .mdb* |
Analisar o arquivo selecionado como | Altere o formato com base no qual analisar o arquivo. | .zip |
Analisar valor como cadeia de caracteres | Selecione para analisar os dados de saída como uma cadeia de caracteres. Se essa opção não estiver selecionada, os dados serão analisados com base no seu tipo. | |
Senhas | Selecione como uma senha será exibida na janela de configuração: Ocultar (padrão), Criptografar para máquina , Criptografar para usuário . | |
Instrução SQL* pós-criação | Defina uma instrução SQL a ser executada por meio do driver ODBC/OLEDB depois que a tabela de saída for criada. | .mdb, .mdb*, .oci, .accdb, ODBC, OLEDB |
Instrução SQL* pré-criação | Defina uma instrução SQL a ser executada por meio do driver ODBC/OLEDB antes que a tabela de saída seja criada. | .mdb, .mdb*, .oci, .accdb, ODBC, OLEDB |
Preservar formatação ao substituir (intervalo obrigatório) | Preserve a formatação do Excel do intervalo que você está substituindo. Não use essa opção caso o arquivo do Excel contenha fórmulas, tabelas, gráficos e imagens, pois esses itens podem ser corrompidos. Quando você seleciona essa opção, também é preciso:
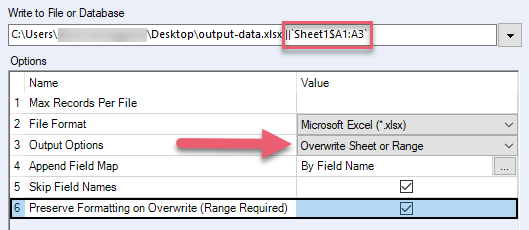 | .xlsx, .xlsm (por meio do driver .xlsx do Alteryx) |
Projeção | Defina o projeto de saída. Por padrão, a projeção está em branco e a saída é feita para WGS 84. Consulte Suporte a projeções . | .mid, .mif, .tab, .shp, .oci, .mdb |
Campos de saída entre aspas | Escolha uma opção referente ao uso de aspas nos nomes dos campos de saída: Automático : insere aspas ao redor de campos que contêm aspas simples ou duplas ou que contêm delimitadores. Sempre : insere aspas ao redor de todos os campos. Nunca : não insere aspas. | |
Ler objetos geográficos como centroides | Para dados com objetos de polígonos, selecione para usar o centroide do polígono como o objeto geográfico. | .mdb*, .tab, .oci, .sdf, .shp, .geo, .kml, .mid, .mif |
Limite de registros | Selecione para limitar os registros lidos dos dados de entrada. Se for 0, todos os registros serão retornados. Se for -1, apenas os metadados serão retornados. | |
Retornar valores filhos | Selecionado por padrão para fazer a saída dos valores filhos do elemento raiz ou de um elemento especificado em Nome do elemento filho XML . Consulte Leitura de XML . | .xml |
Retornar XML externo | Selecione para fazer a saída do formato da tag XML de um elemento especificado em Nome de elemento filho XML . Desmarque para fazer a saída do formato dos filhos do elemento raiz. Consulte Leitura de XML . | .xml |
Retornar elemento raiz | Selecione para fazer a saída do elemento pai que contém todos os outros elementos. Consulte Leitura de XML . | .xml |
Executar pré-SQL na configuração da ferramenta | Selecionada por padrão, essa opção executa instruções pré-SQL quando uma ferramenta é trazida para um fluxo de trabalho. Desmarque a caixa de seleção para executar instruções pré-SQL somente quando o fluxo de trabalho for executado. | |
Salvar fonte e descrição | Selecionada por padrão, essa opção inclui dados de origem e de descrição nas metainformações. Desmarque a opção para excluir dados de origem e de descrição. | |
Procurar nos subdiretórios | Use para trazer múltiplas entradas se os arquivos estiverem em um subdiretório e contiverem a mesma estrutura, nomes de campo, comprimento e tipos de dados. | |
Conjunto de caracteres da sessão | Por padrão, o carregador em massa do Teradata usa a codificação UTF8, que não se ajusta ao conjunto estendido de caracteres latinos que o Teradata usa para caracteres diacríticos. Uma nova opção ("Conjunto de caracteres da sessão") foi adicionada à ferramenta de saída para permitir a alteração do conjunto de caracteres. | ODBC do Teradata |
Tamanho das partes do carregamento em massa (1 MB a 102.400 MB) | O tamanho das partes do carregamento em massa a serem gravadas. A configuração padrão é 128 MB. | |
Ignorar nomes de campos | Quando marcada, essa opção permite gravar dados apenas em uma planilha ou em um intervalo. | .xlsx, .xlsm |
Campo de objeto geográfico | Defina o objeto geográfico a ser incluído na saída. Os arquivos espaciais podem conter apenas um objeto geográfico por registro. O Alteryx não oferece suporte à leitura ou gravação de múltiplos tipos de geometria em um único arquivo. | .mdb*, .tab, .oci, .sdf, .shp, .geo, .kml, .mid, .mif |
Mostrar mensagens de transação | Selecione para exibir, na janela de resultados, uma mensagem para cada transação. Cada mensagem relata a soma dos registros gravados até aquela transação. | |
Iniciar importação de dados na linha | Defina um número de linha no qual iniciar a leitura dos dados. Por padrão, começa na linha 1. | .csv, .xlsx |
Permitir valores nulos | Selecione para fazer a saída de um arquivo .avro com valores nulos. Essa opção de saída cria uniões entre campos com um ramo nulo e um ramo de valor. Se o valor no Alteryx for nulo, a saída usará o ramo nulo; caso contrário, será usado o ramo de valor. Se essa opção não estiver selecionada, todos os campos de saída serão gravados como seus tipos .avro nativos (não-união). Os campos do Alteryx que são nulos serão gravados como seu valor padrão. Use a ferramenta Fórmula para lidar com valores nulos usando valores "conhecidos" para que eles possam ser lidos no Hadoop. | .avro |
Tipo de tabela | Use para selecionar armazenamento de tabelas por linha, por coluna ou o padrão do sistema. Os armazenamentos de tabela representam como os dados são armazenados. O padrão do sistema segue o armazenamento de tabela do banco de dados subjacente. Você notará uma queda no desempenho ao criar uma tabela de armazenamento por coluna em comparação com uma tabela de armazenamento por linha. | ODBC do SAP HANA |
Estilo SQL do nome do campo/tabela | Selecione Entre aspas ou Nenhum . A opção "Entre aspas" usa o identificador de aspas para o tipo de banco de dados. | .oci, OLEDB, OBDC, |
Tabela ou consulta | Se os dados contiverem múltiplas tabelas, defina a tabela a ser inserida ou selecione para criar uma consulta. Consulte Janela "Escolher tabela ou especificar consulta" | |
Obter nome do arquivo de um campo | Selecione uma opção para gravar um arquivo separado para cada valor de um campo específico: Adicionar sufixo ao nome do arquivo/tabela : adiciona o nome do campo selecionado ao final do nome da tabela. Adicionar prefixo ao nome do arquivo/tabela : adiciona o nome do campo selecionado ao início do nome da tabela. Alterar nome do arquivo : altera o nome do arquivo para o nome do campo selecionado. Alterar todo o caminho do arquivo : altera o nome do arquivo para o nome do campo selecionado que contém um caminho completo. | todos os formatos de saída |
Tamanho da transação | Defina o número de registros a serem gravados no banco de dados de uma vez. Os registros são confirmados em lotes menores que 655.360 bytes ou usando tamanho de transação * tamanho do registro. O tamanho do registro é calculado com base nos tamanhos de campo especificados na saída do fluxo de trabalho. Se o tamanho do registro for maior que 655.360 bytes, o tamanho da transação será definido automaticamente como 1. Para atualizações, o tamanho da transação é sempre 1. Por padrão, o tamanho da transação é 0, o que significa todos os registros. Defina os registros para pelo menos 1.000, pois o banco de dados cria um arquivo de log temporário para cada transação, o que pode rapidamente consumir espaço temporário. | .oci, OLEDB, ODBC |
Tratar erros como avisos | Selecione para inserir dados com registros que não estejam em conformidade com a estrutura de dados. Normalmente, os erros fazem com que a entrada falhe; essa opção impede a falha tratando erros como avisos. | |
Cortar espaços em branco | Use o arquivo .flat selecionado (padrão) ou substitua a configuração. | .flat |
Que tipo de fins de linha usar | Use o arquivo .flat selecionado (padrão) ou substitua a configuração. | .flat |
Gravar BOM | Marque essa caixa de seleção para incluir a marca de ordem de byte (BOM) na saída ou desmarque-a para gerar dados sem BOM. | .csv |