Modify String Values
This section describes techniques to standardize text values in your datasets. You can use the following techniques to address some common issues you might encounter in the standardization of text and other non-numeric values.
Convert Columns to String
For manipulation of individual values, it is often easiest to work with the String data type, which is the most flexible. Depending on your approach, you may choose to convert some of your columns into String type:
Transformation Name |
|
|---|---|
Parameter: Columns | col1,col2, col3 |
Parameter: New type | 'String' |
For more information, Valid Data Type Strings.
Available string functions
You can edit values in a column by applying one of the available string functions. The following transformation can be modified for any of the available string functions:
Transformation Name |
|
|---|---|
Parameter: Columns | myCol |
Parameter: Formula | MyStringFunction($col) |
Tip
The$colvalue allows you to reference the current column, which is particularly useful if your transformation is being applied across multiple columns.
For more information see String Functions.
Example - Clean up Strings
In the following example, you can see that there are minor differences between the String values in each row of the dataset. These differences are captured in the Description column.
Some characters, like tab, cannot be represented in this format.
You can download this dataset: Dataset-ExampleStrings.csv.
String | Description |
|---|---|
My String | Base string: 'My String' |
My String extra | Base string + ' extra' |
| A space in front of base string |
| A space after base string |
MyString | No space between the two words of base string |
My String | Two spaces between the two words of base string |
My String | Base string + a tab character |
| Base string + a return character |
| Base string + a newline character |
When this data is imported, it looks like the following, after minor cleanup:
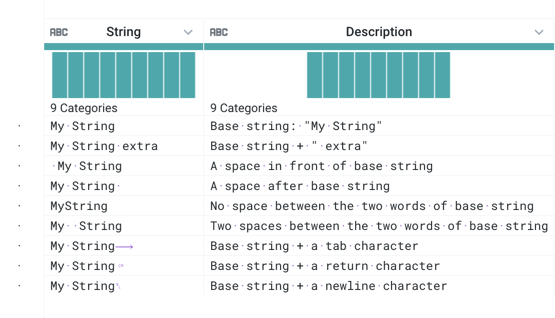
Figure: Example data after import
Notes:
You can see that white space is demarcated in the imported data. In particular, the line item with two spaces between the words is accurately represented in the data grid.
Newlines, carriage returns, tabs, and other non-visible characters are represented with icons.
To normalize these text values, you can use some of the techniques listed on this page to match the problematic string values in this dataset and correct them, as needed. The sections below outline a number of techniques for identifying matches and cleaning up your data.
Trim strings
Note
Before you begin matching data, you should perform a TRIM transform to remove whitespace at the beginning and end of the string, unless the whitespace is significant to the meaning and usage of the string data.
When transforming strings, a key step is to trim off the whitespace at the beginning and ending of the string. For the above dataset, you can use the following command to remove these whitespaces:
Transformation Name |
|
|---|---|
Parameter: Columns | All |
Parameter: Formula | TRIM($col) |
The above transform uses the following special values, which are available for some transforms like set:
Special Value | Description |
|---|---|
* | For the Columns textbox under Advanced, you can use this wildcard to reference all columns in the dataset. Tip You can also select |
$col | When multiple columns are referenced in a transform, this special value allows you to reference the source column in a replacement value. |
The previewed data looks like the following, in which five strings are modified and now match the base string:
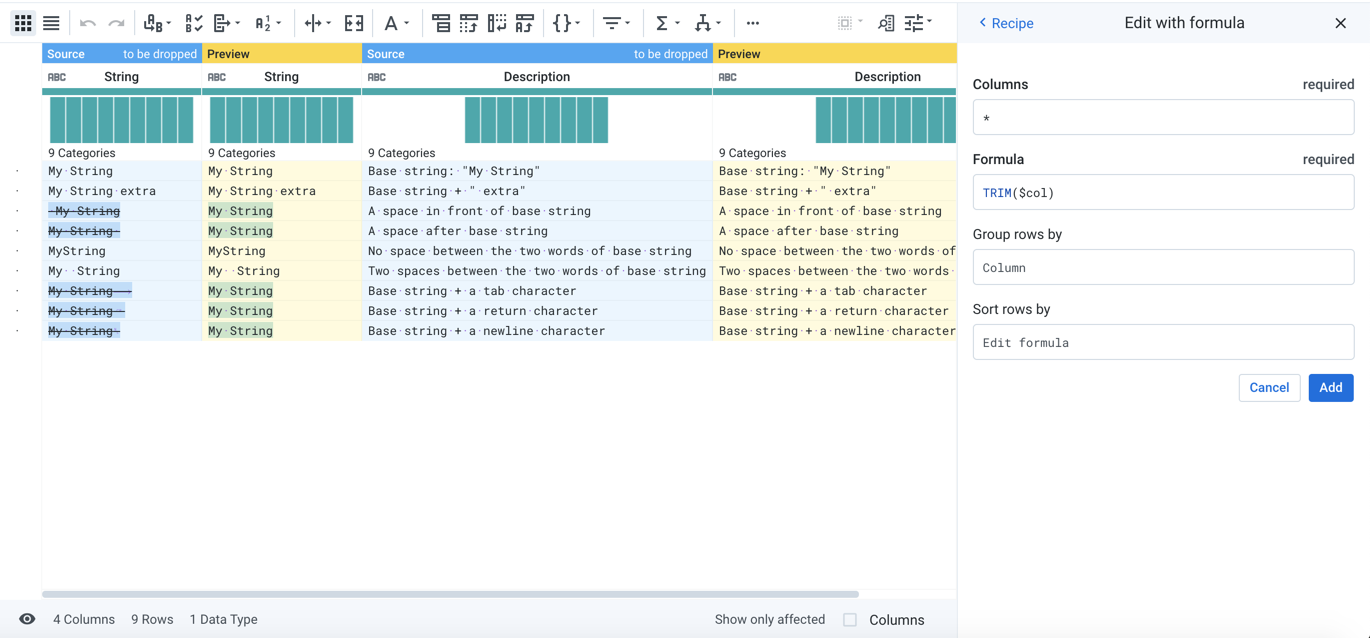
Figure: Trim data to improve matches
Tip
To remove all whitespace, including spaces in between, you can use the REMOVEWHITESPACE function.
Use missing or mismatched value presets
The platform language, Wrangle, provides presets to identify missing or mismatched values in a selection of data.
Tip
In a column's histogram, click the missing or mismatched categories to trigger a set of suggestions.
Missing values preset: The following transform replaces missing URL values with the text string http://www.example.com. The preset ISMISSING([Primary_WebSite_or_URL]) identifies the rows missing data in the specified column:
Transformation Name |
|
|---|---|
Parameter: Columns | Primary_Website_or_URL |
Parameter: Formula | IF(ISMISSING([Primary_Website_or_URL]),'http://www.example.com',$col) |
For more information, see Find Missing Data.
Note
If the data type for the column is URL, then the replacement text string must be a valid URL, or the new data is registered as mismatched with the data type.
Mismatched values preset: This transform converts to 00000 all values in the Zip column that are mismatched against the Zipcode data type. In this case, the preset ISMISMATCHED(Zip, ['Zipcode']) identifies the mismatched values in the column, as compared to the Zipcode data type:
Transformation Name |
|
|---|---|
Parameter: Columns | Zip |
Parameter: Formula | IF(ISMISMATCHED(Zip, ['Zipcode']),'00000',$col) |
For more information, see Find Bad Data.
Remove a specific sub-string
An entry in the example data contains an additional word: My String extra. You can use a simple replace command to remove it:
Transformation Name |
|
|---|---|
Parameter: Column | String |
Parameter: Find | ' extra' |
Parameter: Replace with | '' |
Parameter: Match all occurrences | true |
The global parameter causes the replacement to be applied to all instances found within a cell value. Otherwise, the replacement occurs only on the first instance.
Replace double spaces
There are multiple ways of removing double spaces, or any pattern, from text values. For best results, you should limit this change to individual columns.
Note
For matching string patterns that are short in length, you should be careful to define the scope of match. For example, to remove double spaces from your dataset, you should limit the columns to just the ones containing string values. If you applied the change to all columns in the dataset, meaningful uses of double spacing could be corrupted, such as in JSON data fields.
Transformation Name |
|
|---|---|
Parameter: Column | String |
Parameter: Find | ' ' |
Parameter: Replace with | '' |
Parameter: Match all occurrences | true |
In the above, the Find term contains a string with two spaces in it.
Tip
If you wish to find two or more spaces, you can use the following Wrangle in the Find parameter:
`( )+`
The Replace term contains no spaces.
Break out CamelCase
CamelCase refers to text in which multiple words are joined together by removing the spaces between them. In the example data, the entry MyString is an example of CamelCase.
Note
Regular expressions are very powerful pattern-matching tools. If they are poorly specified in a transform, they can have unexpected results. Please use them with caution.
You can use Wrangle to break up CamelCase entries in a column of values. The following transforms use regular expressions to identify patterns in a set of values:
Transformation Name |
|
|---|---|
Parameter: Column | String |
Parameter: Find | `({alpha})({upper})` |
Parameter: Replace with | '$1 $2' |
Parameter: Match all occurrences | true |
The first transform locates all instances of uppercase letters followed by lower-case letters. Each instance is replaced by a space, followed by the found string ($2). For more information, see Text Matching.
Reduce strings by words
Remove last word:
For example, you need to remove the last word of a string and the space before it. You can use the following replace transform to do that:
Transformation Name |
|
|---|---|
Parameter: Column | String |
Parameter: Find | ` {alpha}+{end}` |
Parameter: Replace with | '' |
Parameter: Match all occurrences | true |
When the above is previewed, however, you might notice that ending punctuation is not captured. For example, periods, exclamation points, and question marks at the end of your values are not captured in the Wrangle . To capture those values, the Find parameter must be expanded:
Transformation Name |
|
|---|---|
Parameter: Column | String |
Parameter: Find | ` {alpha}+({[?.!;\)]}|){end}` |
Parameter: Replace with | '' |
Parameter: Match all occurrences | true |
In the second version, a capture group has been inserted in the middle of the on parameter value, as specified by the contents of the parentheses:
The bracket-colon notation denotes a set of possible individual characters that could appear at this point in the pattern.
Note the backward slash before the right parenthesis in the capture group. This value is used to escape a value, so that this parenthesis is interpreted as another character, instead of the end of the capture group.
The vertical pipe (
|) denotes a logical OR, meaning that the specified individual characters could appear or the value after the vertical pipe.Since the value after the vertical pipe is missing, this capture group finds values with or without punctuation at the end of the line.
A capture group is a method of grouping together sequences of characters as part of a matching pattern and then referencing them programmatically in any replacement value. For more information, see Capture Group References.
Reduce total number of words:
You need to cut each value in a column down to a maximum of two words. You can use the following to identify the first two words using capture groups in a Wrangle and then write that pattern back out, dropping the remainder of the column value:
Transformation Name |
|
|---|---|
Parameter: Column | String |
Parameter: Find | `{start}({alpha}* )({alpha}*) ({any}*{end})` |
Parameter: Replace with | '$1$2' |
Parameter: Match all occurrences | true |
For the Find pattern:
The
startpattern identifies the start of each value in theStringcolumn.The two
alphacapture groups identify the first two words in the string. Note that the space after the second capture group is specified outside of the capture group; if it was part of the capture group, a trailing space is written in the replacement value.The final capture group identifies the remainder of the value in the cell.
anycaptures any single character.The wildcard asterisk captures all values between the
anycharacter and theendof the value.
Other String Cleanup Transformations
Trim whitespace from text
You can trim out whitespace from an individual column via transformation. The TRIM function applied to string values removes the leading and trailing whitespace:
Transformation Name |
|
|---|---|
Parameter: Columns | myCol |
Parameter: Formula | TRIM(myCol) |
To apply this function across all columns in the dataset, you can use the following:
Transformation Name |
|
|---|---|
Parameter: Columns | All |
Parameter: Formula | TRIM($col) |
Notes:
Instead of
Allabove, you can use the asterisk (*) wildcard, which represents all possible value. In this case, both values for Columns matches with all column names in the dataset.You may need to move columns or use range values to apply this transformation to only non-numeric column types.
The
$colentry denotes a reference to the current column. So for any column to which this transformation is applied, the source values are pulled from the column itself and then trimmed.
In some cases, you may wish to remove all spaces, including those in between words or digits, in your strings:
Transformation Name |
|
|---|---|
Parameter: Columns | All |
Parameter: Formula | REMOVEWHITESPACE($col) |
Remove whitespace
If needed, you can remove all whitespace from a column of values.
Note
This transformation differs from the TRIM function, which removes only the whitespace at the beginning and end of the string. This transformation removes all whitespace, including space in the middle of the string.
Tip
For some of the string comparison functions, you may achieve better results by comparing strings without whitespace.
Transformation Name |
|
|---|---|
Parameter: Columns | name |
Parameter: Format | Remove all whitespace |
Remove symbols
The following transformation removes all non-alphanumeric symbols from your string values, including:
Punctuation
Numeric value indicators ($, %, etc.)
Note
Accented characters may not be removed. If this function fails to remove specific symbols, you may need to remove these symbols manually or change the input encoding on the dataset through the Import Data page.
Transformation Name |
|
|---|---|
Parameter: Columns | All |
Parameter: Format | Remove symbols |
Remove accents
The following transformation converts all accented characters (e.g."ä") to unaccented characters (e.g "a").
Transformation Name |
|
|---|---|
Parameter: Columns | All |
Parameter: Format | Remove accents |
Trim quotes
When some files are imported into the application, leading and trailing quotes may remain for some or all columns. You can use the following transformation to remove these quotes from all columns:
Note
Quotes that appear in the middle of the string value are not removed. Single quotes, such as apostrophes, are not removed.
Transformation Name |
|
|---|---|
Parameter: Columns | All |
Parameter: Format | Trim leading and trailing quotes |
Pad Values
Add prefix or suffix to strings
You can add fixed-string prefixes or suffixes to your string values. The following adds -0000 to a text version of the Zipcode column:
Transformation Name |
|
|---|---|
Parameter: Columns | txtZipCode |
Parameter: Format | Add suffix |
Parameter: Text to add | '-0000' |
Standardize String Values
Standardize case
You can use the following steps to set all text values in a column to be the same case.
Lower case:
Transformation Name |
|
|---|---|
Parameter: Columns | myStrings |
Parameter: Formula | LOWER(myStrings) |
Upper case:
Transformation Name |
|
|---|---|
Parameter: Columns | myStrings |
Parameter: Formula | UPPER(myStrings) |
Proper (sentence) case:
Transformation Name |
|
|---|---|
Parameter: Columns | myStrings |
Parameter: Formula | PROPER(myStrings) |
Standardize String Lengths
Pad string values
If you need all of your column values to be of the same length, one technique is to pad each string value at the front sufficiently, such that all string lengths in the column are identical.
This transformation results in adding enough spaces to each row value until the length of each value is 50 characters.
Note
Strings that are longer that the prescribed maximum are unchanged. You can use the LEFT or RIGHT functions to change the size of the oversized ones. See below.
Transformation Name |
|
|---|---|
Parameter: Columns | MyStrings |
Parameter: Format | Pad with leading characters |
Parameter: Character to pad with | ' ' |
Parameter: Length | 50 |
Fixed length strings
You can limit the maximum size of a column or set of columns to a fixed string length. For example:
Transformation Name |
|
|---|---|
Parameter: Columns | col1,col2 |
Parameter: Formula | IF(LENGTH($col)>32,LEFT($col,32),$col) |
In the above, if the length of either column is longer than 32 characters, then the column value is set to the leftmost 32 characters. For shorter strings, the entire string is used.
For more information, see Manage String Lengths.
Manage Sub-Strings
You can use the following functions to locate values within your strings. These functions can be used as part of New Formula or Edit Formula transformations to create or edit column content:
Function Name | Description |
|---|---|
Returns the number of characters in a specified string. String value can be a column reference or string literal. | |
Returns the index value in the input string where a specified matching string is located in provided column, string literal, or function returning a string. Search is conducted left-to-right. | |
Returns the index value in the input string where the last instance of a matching string is located. Search is conducted right-to-left. | |
Matches the leftmost set of characters in a string, as specified by parameter. The string can be specified as a column reference or a string literal. | |
Matches the right set of characters in a string, as specified by parameter. The string can be specified as a column reference or a string literal. | |
Matches some or all of a string, based on the user-defined starting and ending index values within the string. | |
Replaces found string literal or pattern or column with a string, column, or function returning strings. |
Reset Types
After modifying non-text values as strings, remember to convert them back to their original types.