Overview of Job Execution
This section provides an overview of how jobs of various types are initiated, managed, and executed in Designer Cloud. You can also review summaries of the available running environments for your product edition.
Note
During job execution of any kind, Designer Cloud never modifies source data. All transformation is performed on requested elements of the data. If the data needs to be retained for any period of time during use or transformation, it is stored in the browser or in the base storage layer. After the data has been used for the intended purpose, it is removed from temporary storage.
When you build your recipe in the Cloud Portal, you can see in real-time the effects of the transformations that you are creating. When you wish to produce result sets of these transformations, you must run a job, which performs a separate set of execution steps on the data. Job execution is a separate process for the following reasons:
In the Transformer page, you are working with a sample of your data. For larger volumes of data, the entire dataset cannot be represented in the browser effectively. So, to apply your recipe to the entire dataset, a separate set of actions must be performed.
When working with large datasets, you need a running environment on a multi-node cluster that has been designed for parallel processing. Modern running environments are designed to break up data transformation jobs into separate pieces, each of which can be executed on a separate node and then returned to be assembled with the other job parts into the finished result set.
Job execution can occur asynchronously. When you launch a job, a separate lightweight process assembles the necessary pieces for the job to be executed and then distributes these pieces accordingly. You can continue to work in the Transformer page while your results are being prepared with minimal impact on Cloud Portal performance or your user experience.
Other features of job execution:
Change the format of the source to a different format in the output.
Change the location where the results are generated.
Change file-based source data into table-based relational data on the output.
Write multiple versions of the output at the same time.
Jobs can also be scheduled.
Jobs Types
The following types of jobs can be executed as part of normal operations of the product.
Job locations:
A local job is one that is executed on the Trifacta node using services that are hosted on it.
A remote job is executed through services that are not hosted on the Trifacta node.
Transformation job types
Informally, a "job"is considered any action that is performed on a set of data. Commonly, jobs refer to the process of transforming source data into output results. However:
Transformation jobs are composed of a number of sub-jobs, which handle things like ingestion of data, transformation, and writing of results.
In addition to jobs that transform data, there are other types of jobs. Discussed later.
Job groups:
For transformation job types, the following terms apply:
Internal to the product, a job that is executed on one or more recipes in a flow is called a jobGroup.
A jobGroup is composed of one or more of the job types listed below. Internal to the platform, these are called jobs.
The following diagram illustrates how these job types are related.
+ myJob jobGroup + Connect job + Request job + Ingest job + Transform job + Transfer job + Process job
Tip
You can have one or more of each of these job types as part of a single jobGroup.
Connect
A Connect job performs the steps necessary to connection the Cloud Portal to the datastore that contains source data. These jobs use the connection objects that are native to the platform or that you have created to make the connection to your imported datasets.
Note
Depending on the running environment, a Connect job may time out after a period of inactivity or failure to connect, and it may be retried one or more times before the job is marked as failed.
Request
A Request job sends a query or other request to the source datastore for the assets specified in the imported datasets.
Ingest
Requested data is brought from the external source to the execution layer, which is the temporary storage location as defined for the running environment.
Convert
Some formats supported for import are not natively understood by the product. These formats must be converted to a format that the platform can quickly process. This process typically converts binary formats, such as XLS or PDF, into CSV files that are stored temporarily in the base storage layer for purposes of job execution. After the job has succeeded or failed, these converted files are removed.
Transform
After data has been requested and ingested (if needed), a Transform job converts the steps of a recipe into an intermediate scripted format (called CDF). The CDF script is then passed to the appropriate running environment for transformation of the source data. Additional details are provided later.
Prepare
If the specified job is publishing results to a connection other than the base storage layer, the results are initially prepared on the base storage layer, after which they are written to the target datastore.
This job type does not apply when the base storage layer is the final destination for the results.
Transfer
A Transfer job writes the results to the appropriate output location, as specified by the output objects referenced when the job was launched.
Process
When the transfer is complete, a Process job performs final cleanup, including removal of temp files such as intermediate results written to the base storage layer.
Other job types
Profiling
When you execute a transformation job, you can optionally choose to create a visual profile of the results of that job. Visual profiling is a separate job that sometimes takes longer to execute than the job itself, but a visual profile can be useful in highlighting characteristics of your data, including metrics and errors on individual columns.
Visual profiles are available for review in the Job Details page. You can also download PDF or JSON versions of your visual profile.
For more information on visual profiling, see Overview of Visual Profiling.
Sampling
When you are interacting with your source data to transform it through the browser, you are working on a sample of the data. As needed, you can take new samples of the data to provide different perspectives on it. Also, for longer and more complex flows, you should get in the habit of taking periodic samples, which can improve performance in the browser.
Through the Samples panel, you can launch a job to collect a new sample of your data. There are multiple types of sampling, which can be executed using one of the following methods:
Quick scan: These sample types are performed based on a scan a limited number of rows of your data.
These samples are based on the first set of rows that are accessible and are quick to execute. However, they cannot pick up in the sample any rows that are deeper in your datasets. For example, if your source data contains multiple files, quick scan samples might not contain any data from the second or later files.
These samples are executed in Trifacta Photon.
Full scan: A full scan sample is executed across the entire available dataset.
Depending on the size of your dataset, this scanning and sample process can take a while to execute on a large dataset.
These samples are executed on the clustered running environment with which the Cloud Portal is connected.
For more information, see Overview of Sampling.
Basic Process for Transformation Jobs
A transformation job is run based on the outputs that you are trying to generate. For a selected output, the executed job runs the transformations for all of the recipes between the output and all of its imported datasets. For example, generation of a single output could require the transformation of five different recipes that use 13 different imported datasets.
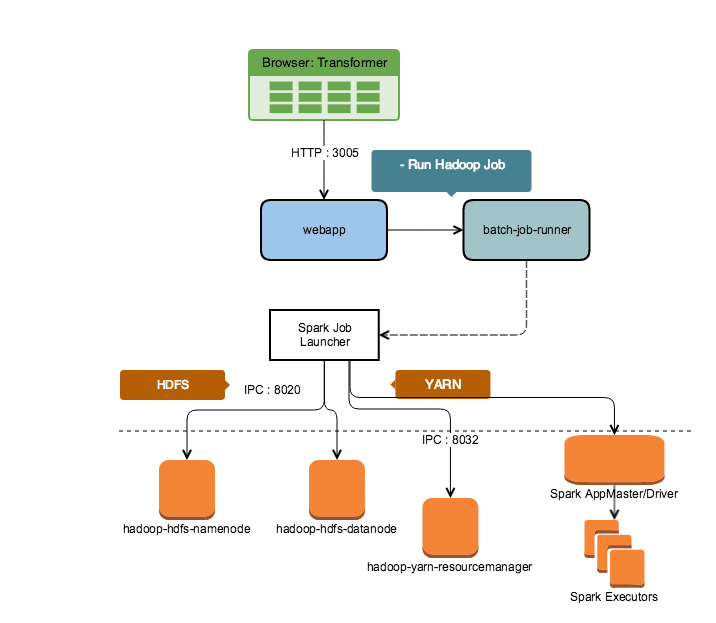
Figure: Flow chart on how a Spark-based job is executed on a Hadoop cluster
Steps:
Job preparation: A jobGroup entry is created in the database, and a job execution graph is created for each job within the jobGroup and submitted to the batch job runner service. This service requests an expanded version of the recipe in CDF format from the Cloud Portal. This and other assets are placed in a queue for processing by the batch job runner.
Job preparation: When resources are available, the job is pulled from the queue and submitted to the resource coordinator of the batch job runner for execution on Trifacta Photon or the remote running environment. The job is placed in another queue for execution on the appropriate running environment.
Job execution: When cluster resources are available, the job definition, CDF script and other resources are submitted to the resource coordinating process for the selected running environment (In the above diagram, this is the Spark Job Launcher, which coordinates with YARN). This process submits parts of the job to separate nodes on the cluster for execution. Periodically, batch job runner polls this process for status. When all nodes of the cluster have completed their execution, the job results are written to the designated location, and batch job runner finishes the job execution by updating the Jobs database.
Job preparation
When you initiate a job through the Cloud Portal, the following steps occur:
A jobGroup is created in the database. It consists of the specification of one or more jobs, as described above.
The recipe whose output is being executed is requested from the Alteryx database. This recipe is expanded from storage format and later is stored temporarily in the database for reference.
The Cloud Portal verifies access to data sources and output locations.
A job execution graph (flow chart) is created for the various jobs required to complete execution of the jobGroup.
This graph includes jobs for ingest, transformation, conversion, and other steps, as described above.
The graph is sent to the batch job runner service in the platform. This service manages the submission, tracking, and completion of all jobs to supported running environments.
Batch job runner requests to the Cloud Portal to return a Common Dataflow Format (CDF) version of the expanded recipe.
CDF is a domain-specific language for data transformation that runs anywhere that supports Python execution.
Wrangle is compiled into CDF format at execution time. This CDF script is delivered to the running environment for execution.
CDF scripts are internal to the platform and are not accessible to users of the platform.
Depending on the running environment, additional modifications to the CDF script may be made before the job is submitted.
The batch job runner places the job in a queue for submission to the running environment.
Job execution
When the job is ready to be pulled from the queue, the following tasks are completed:
The job definition, CDF script, and associated resources are submitted to the resource coordinating process of the running environment.
This coordinator is the batch job runner for local jobs or a dedicated service on remote running environments.
For example, for EMR execution, which is a remote running environment, the job is submitted to the YARN service, which manages the delegation of work tasks to the various nodes in the cluster.
In the resource coordinator, jobs from the product are labeled as
Trifacta TransformerorTrifacta Profiler(for profiling jobs).
Periodically, batch job runner polls the running environment for status on job execution.
This status information is stored and updated in the Jobs database.
The Cloud Portal queries the Jobs database for updated information.
These updates are stored in the Alteryx databases for internal services to access to present updates.
Updates can appear in Flow View page and also in the Jobs and Job Details page, so that you can track progress.
During execution, the resource manager arranges for the delivery of data and CDF script objects to nodes of the cluster.
On these individual nodes, portions of the data are processed through the CDF script.
The results of this processing is messaged back to the resource manager.
When all of the nodes have reported back that the job processing has been completed, results are written to the location or locations as defined in the output object that was selected during job execution.
Batch job runner updates any available job logs as needed based on the results of the job execution. These logs may be available through the Cloud Portal.
Job monitoring
Transformation jobs: After a transformation job has been launched, you can monitor the state of the job as it passes through separate stages in the process.
In Flow View, click the output object. Then, click the Jobs tab. See Flow View Page.
In the Job History page, you can hover over the status of the job to gather more information. See Job History Page.
Additional information may be available in the Job Details page. See Job Details Page.
Sample jobs: In-progress sampling jobs can be tracked through the following locations:
After you have initiated a sample job through the Samples panel, you can track progress there. See Samples Panel.
All of your sample jobs are available through the Cloud Portal. See Sample Jobs Page.
Plan runs: When you have launched jobs as part of a plan run, you can track progress through the Cloud Portal. A plan run may consist of flow-based transformation jobs, as well as other tasks.
See Plan Runs Page.
Job cleanup
After the results have been written, the following tasks are completed:
Applicable job logs are updated and written to the appropriate location.
The expanded recipe stored in the database is removed.
Any temporary files written to the base storage layer are removed.
Scheduled jobs
You can also schedule the execution of jobs within your flows. This process works as follows:
In Flow View, you define the outputs that you wish to deliver when the flow is executed according to a schedule. These outputs are different objects that the outputs you create from your recipes, but you can define them to write to the same locations.
You specify the schedule for when the job is to be executed. Date and time information, as well as frequency of execution, can be defined within the flow.
When the specified time is reached, the job is queued for execution, as described above. For more information, see Overview of Scheduling.
Job Execution Performance
Job execution is a resource-intensive and multi-layered process that transforms data of potentially limitless size. The following factors can affect performance in the Cloud Portal and during job execution:
Long or complex recipes
Consider breaking recipes into smaller steps. You can change recipes together.
Number of columns in your data
The entire width of a dataset must be represented in the sample.
Delete unnecessary columns early in your recipe.
Tip
If your data is sourced in relational systems, you can apply optimizations to your imported datasets to pre-filter out columns in your dataset before they are ingested into the system. See Flow Optimization Settings Dialog.
You can also use custom SQL statements to collect only the columns that are needed from source tables. See Create Dataset with SQL.
Complexity of transformations
Transformations that blend datasets (join and union) or that perform complex transformations on your dataset (aggregate, window, pivot, etc.) can be expensive to process.
If your recipe contains too many of them, it can negatively impact job processing. Consider breaking these across multiple recipes instead.