Product Overview
This section provides a short overview of Designer Cloud, its key features, and how they interact with each other.
What is Designer Cloud?
Dataprep by Trifactaenables you to explore, combine, and transform diverse datasets for downstream analysis.
Within an enterprise, data required for key decisions typically resides in various silos. It comes in different formats, featuring different types. It is often inconsistent. It may require refactoring in some form for different audiences. All of this work must be done before you can begin extracting information valuable to the organization.
Data preparation (or data wrangling) has been a constant challenge for decades, and that challenge has only amplified as data volumes have exploded.
Why use Designer Cloud?
Some organizations have pushed these cleansing efforts onto IT, which may take weeks to come up with a custom, scripted solution that requires inevitable back-and-forth between coder and analyst. As formats, feeds, and requirements change, these rigid solutions require frequent updating, which cannot be done by the people who really know the data. Instead of producing insights, analysts are filing requests and waiting for weeks for solutions.
The Alteryx solution delivers the tools to wrangle data to the people who understand the meaning of the data. With Designer Cloud, analysts have the means to apply their expertise to the preparation of the data, in a way that is faster and more productive.
Designer Cloud helps to do the following:
Cut time to prepare actionable data
Avoid IT bottlenecks and reliance on data scientists in data prep
Deliver tools to prepare data to the people who understand the data
Eliminate manual prep work
Surface data quality issues in a way that's easy to fix them
Featuring a leading-edge interface, powerful machine intelligence, and advanced distributed processing, Designer Cloud renders the time-consuming, complex, and error-prone process of preparing datasets of any volume into a point-and-click exercise. What took six weeks in the IT lab can be done in less than two hours at the analyst's desk. Predictive Transformation
Humans are pretty good at identifying singular problems; software is better at solving them at scale. The platform leverages this concept through predictive transformation.
You see an issue in your sampled data. Whether it is part of a value, multiple values in a column, or the entire column itself, you select it. Immediately, the platform surfaces a set of suggestions for you. How would you like to transform this data?
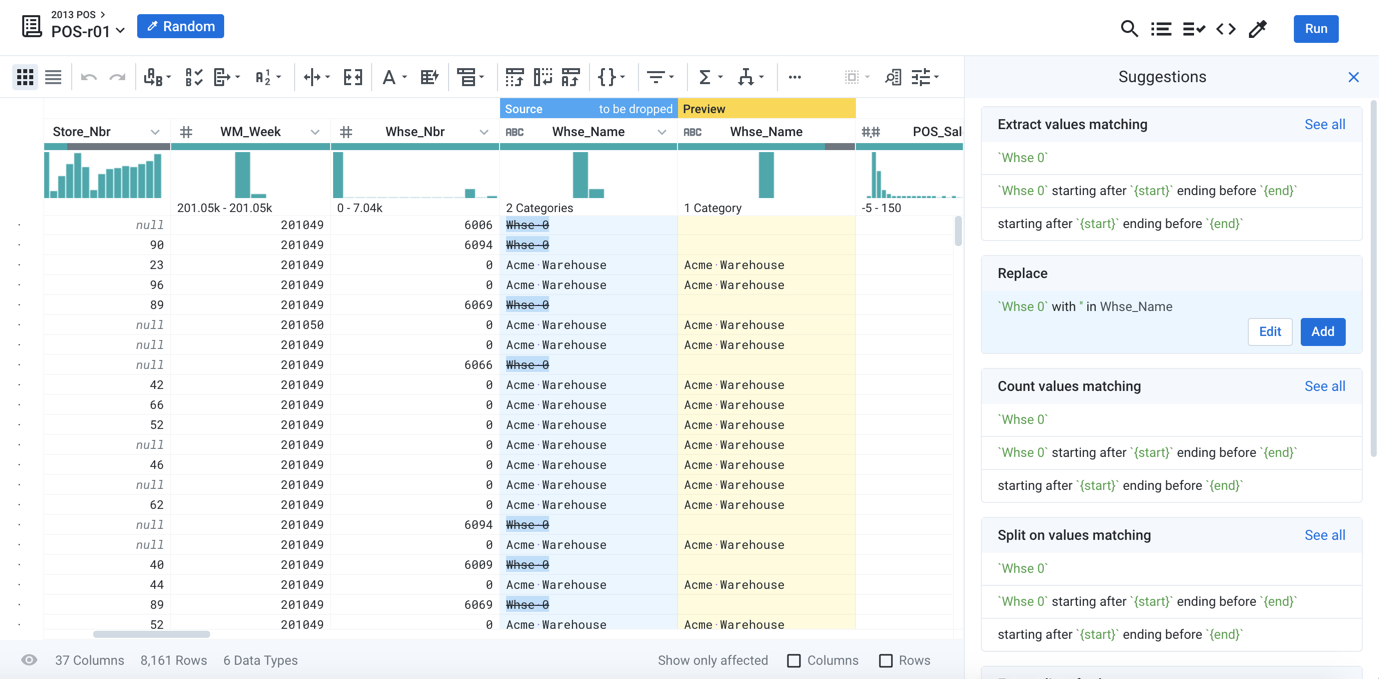
Figure: Select data elements to receive context-specific suggestions on transformations to apply to the element or to patterns that describe it. Preview the results before you add the change.
Through an innovative interface and leading-edge machine-learning techniques, Designer Cloud surfaces potential actions on the data in an intuitive manner for rapid triage. Select something in the data grid, and the platform provides a set of context-specific recommendations of actions to take on the selected data and similar matching items. Click the recommendation, and your data is transformed. Modify the particulars of the transformation to get it right. No coding required.
For more information, see Overview of Predictive Transformation.
Machine Learning
As you make selections, the platform's predictions become smarter and better. What you select today with this dataset informs the platform recommendations for transforming tomorrow's dataset.
Additionally, customers may opt-in to send anonymized usage data, so that the transformations being crafted across thousands of users can influence the machine-learning algorithms deployed in subsequent releases.
How does it work?
The scale and complexity of these transformations can quickly overwhelm even the most powerful of machines. Designer Cloud utilizes a number of techniques to deliver high performance at scale.
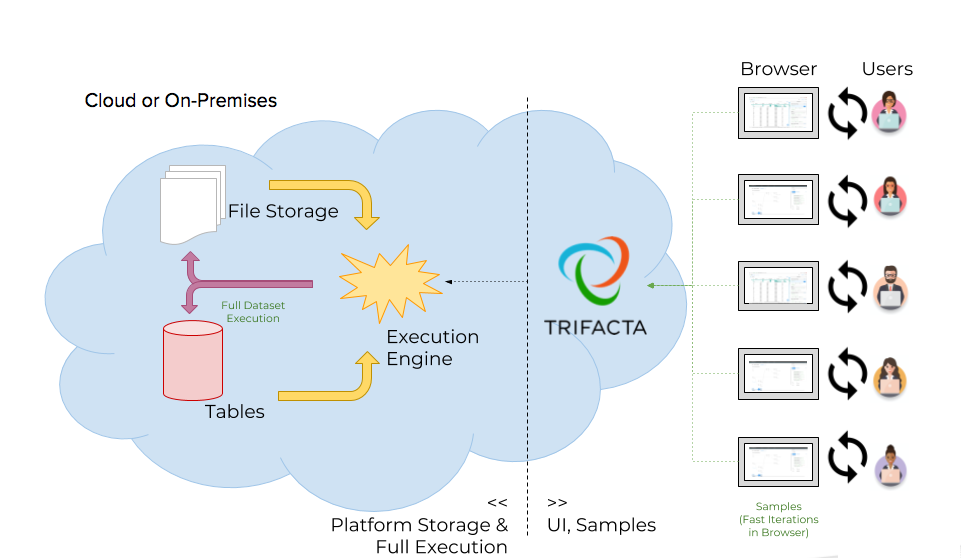
Figure: Platform interactions and data movements
Basic Steps:
Through a standards-compliant web browser, users interact with the platform through the user interface to complete the following tasks:
Create connections to sources of data. Some connections, such as desktop upload, are automatically created for you.
Through those connections, create references to specific datasets (files and tables).
Load samples of data into the user interface.
Build sequences of steps to transform the sampled data through innovative user interface controls.
Execute a job to perform that sequence of steps across the entire dataset, yielding an output dataset delivered to the preferred destination in the proper format.
Note
For large datasets, the transformation work is distributed across the nodes available to the integrated cluster.
As needed, export the results from the platform.
The above steps create a single sequence of steps from a single dataset. Datasets and sequences (recipes) can be combined or chained together to address much more complicated data wrangling requirements.
Connectivity
Note
This feature may not be available in all product editions. For more information on available features, see Compare Editions.
The platform supports creation of connections to the following:
JDBC (relational) connections to a wide variety of database sources
Read/write connectivity to distributed file-based storage
Upload/download
Sampling
For larger datasets, loading all rows can quickly overwhelm the desktop system through which they are being viewed. Even if the local environment can handle the data volume, performing transformations becomes a cumbersome experience. For systems that do not support data sampling, the local desktop effectively becomes the limiting factor, variable as it is, on the size of the dataset.
Designer Cloud overcomes limitations of the local desktop by sampling from datasets. When a dataset is loaded for use for the first time, a sample of the first set of rows is immediately taken. This sample size does not exceed 10 MB.
At any time, you can collect a new sample using one of several statistically useful sampling techniques. Random, filtered, anomaly-based, and stratified sampling are only some of the techniques available for use.
Samples are maintained and can be selected for use again at any time.
For more information, see Overview of Sampling.
Distributed Processing Environments
Designer Cloud includes the Trifacta Photon environment, an embedded running environment that is suitable for sampling and smaller-scale jobs.
For large-scale jobs, Designer Cloud can integrate with a variety of leading-edge running environments. When it is time to execute a job, the platform distributes the workload to the nodes of the cluster's running environment, where the transformations are executed on the segment of source data stored on the node. These transformations occur on in-memory versions of the source data, with the results returned to Designer Cloud for final assembly and export.
Tip
Processing of jobs within the Trifacta Photon running environment or across a distributed processing environment happens asynchronously. So, you kick off your job, resume working, and collect the results when the job is finished.
What do you build in Designer Cloud?
In Designer Cloud, the primary object that you create is the recipe. A recipe is a sequence of transformation steps that you create to transform your source dataset. When you select suggestions, choose options from the handy toolbar, or select values from a data histogram, you begin building new steps in your recipe. After selecting, you can modify them through the Transform Builder, a context panel where your configured transformation can be modified and the changes previewed before saving them.
When you finish your recipe, you run a job to generate results. A job executes your set of recipe steps on the source data, without modifying the source, for delivery to a specified output, which defines location, format, compression and other settings.
Datasets, recipes, and outputs can be grouped together into objects called flows. A flow is a unit of organization in the platform.
Depending on your product, flows can be shared between users, scheduled for automated execution, and exported and imported into the platform. In this manner, you can build and test your recipes, chain together sets of datasets and recipes in a flow, share your work with others, and operationalize your production datasets for automated execution.
What else can you do in Designer Cloud?
In addition to the above, the following key features simplify the data prep process and bring enterprise-grade tools for managing your production wrangling efforts.
Visual Profiling
For individual columns in your dataset, data histograms and data quality information immediately identify potential issues with the column. Select from these color-coded bars, and specific suggestions for transformations are surfaced for you. When you make a selection, you can optionally choose to display only the rows or columns affected by the change.
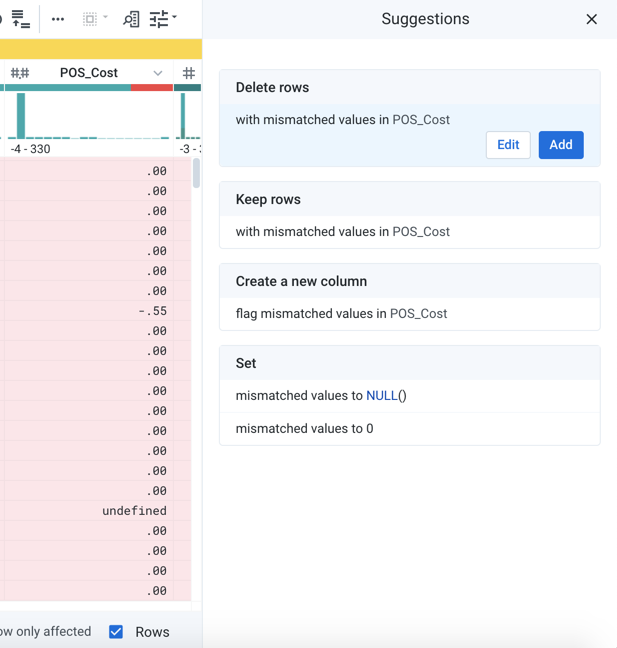
Figure: Click the red bar to select all mismatched values in the column. Show only the affected rows. Review suggestions for how to fix these specific values.
Tip
Dig into the column details to explore distributions of values based on the column's data type.
As part of your transformation job, you can optionally generate a visual profile of your dataset, which allows you to quickly identify areas for additional iteration.
For more information, see Overview of Visual Profiling.
Transform to Target
Since data wrangling targets are often other systems with well-defined input requirements, the structure of the target data is typically known in advance. To assist in your data wrangling efforts, you can import a representation of the target structure into your flow, assign it to a recipe, and then use specific tools to rapidly transform your dataset to this target. Match up fields in your source to the target using name, data type, and position in the schema. Then, pattern-match source data to expectations in the target field to ensure that you are delivering the appropriate data for downstream requirements.
For more information, see Overview of Target Schema Mapping.
Operationalization
After you have finalized development of your flow, you can operationalize its execution. Using a simple interface, you can define when the flow is executed on a periodic basis.
Tip
Datasets can be parameterized. For example, you can store a set of files in a single directory and reference all of them through a single dataset with some parameterized value. When referencing flows are executed, the transformation steps are applied to all source files.
For more information, see Overview of Parameterization.
Automation
Scheduling
You can schedule the execution of your flows through the application. See Overview of Scheduling.
Plans
Note
This feature may not be available in all product editions. For more information on available features, see Compare Editions.
Through the Trifacta Application, you can create plans, which are sequence of flow execution tasks. For more information, see Plans Page.
REST APIs
The platform supports automation through externally available REST APIs.
See API Reference.