Overview of the Type System
This section provides an overview of how data types are managed during import, transformation, and export of data in Designer Cloud.
Terms:
A data type is a definition of a set of values, including:
Possible set of values (e.g. Dates from 1/1/1400 to 12/31/2599)
Meaning of those values (e.g. two-letter codes can represent states of the United States)
Set of operations that can be applied to those values (e.g. functions applicable to integers)
A data format is a representation of the underlying type, which has the same meaning and available operations associated with the data type. For example, the following values are all valid for Datetime data type, but each is represented in a different format:
12/31/2021 31-12-2021 December 31, 2021
Note
Some data types can be explicitly formatted through functions. Other data types support different formats implicitly through the application.
How Data Types Are Used
In the Trifacta Application, data types are used for the following:
Anomaly detection (Is the value valid or invalid?)
Suggestions (What are the available transformation suggestions for this column based on its data type?)
Standardization (How can all of these valid values be standardized for the column's data type?)
Pattern recognition (How to identify different formats in the same column?)
Data Types
Designer Cloud supports the following categories of data types:
Logical data types
A logical data type is a class of values that is understood by native system representations.
Tip
These types are recognized internally by Designer Cloud. Each running environment to which Designer Cloud connections natively supports these logical data types.
These data types have no additional specification requirements:
Data Type | Description |
|---|---|
Any non-null value can be typed as String. A String can be anything. | |
The Integer data type applies to positive and negative numeric values that have no decimal point. | |
Decimal data type applies to floating points up to 15 digits in length.
| |
The Boolean data type expresses true or false values. | |
Designer Cloud supports a variety of Datetime formats, each of which has additional variations to it. | |
An Object data type is a method for encoding key-value pairs. A single field value may contain one or more sets of key-value pairs. | |
An array is a list of values grouped into a single value. An array may be of variable length; in one record the array field may contain two elements, while in the next record, it contains six elements. |
Formatting differences may apply. For example, Designer Cloud may recognize Y and N as Boolean data type, while other systems may not.
Complex data types
A complex data type typically is defined by applying additional restrictions on String data type values to define the class of possible values. For example, Designer Cloud supports a Gender data type, which validates values such as M & F and male and female as Gender data type.
The following are the complex data types supported by Designer Cloud.
Data Type | Description |
|---|---|
This data type is applied to numeric data following the pattern for United States Social Security numbers. | |
This data type is applied to numeric data following common patterns that express telephone numbers and known valid phone numbers in the United States. | |
This data type matches text values that are properly formatted email addresses. | |
Credit card numbers are numeric data that follow the 14-digit or 16-digit patterns for credit cards. | |
This data type matches a variety of text patterns for expressing male/female distinctions. | |
This data type matches five- and nine-digit U.S. zipcode patterns. | |
State data type is applied to data that uses the full names or the two-letter abbreviations for states in the United States. | |
The IP Address data type supports IPv4 address. | |
URL data type is applied to data that follows generalized patterns of URLs. | |
Values of these data types are three-digit numeric values, which correspond to recognized HTTP Status Codes. |
Complex data types are typically defined based on a regular expression applied to String values. For example, the following regex is used to define the accepted values for the Email Address data type:
"regexes": [
"^[a-z0-9.!#$%&'*+/=?^_`{|}~-]+@[a-z0-9.-]+(?:\\.[a-z0-9-]+)*\\.[a-z]{2,}$"
],Logical and complex data types
Data type | Category | Internal data type | Notes |
|---|---|---|---|
logical | String | The default data type. Any non-empty/non-value is valid for String data type. | |
logical | Int | Use NUMFORMAT Function to format these values. Underlying values are not modified. | |
logical | Float | UseNUMFORMAT Functionto format these values. Underlying values are not modified. | |
logical | Bool | ||
logical | Datetime | Use DATEFORMAT Functionto format these values. Underlying values are not modified. | |
logical | Map/Object | ||
logical | Array | ||
complex | String | String data type constrained by a regular expression. | |
complex | String | String data type constrained by a regular expression. | |
complex | String | String data type constrained by a regular expression. | |
complex | String | String data type constrained by a regular expression. | |
complex | String | String data type constrained by a regular expression. | |
complex | String | String data type constrained by a regular expression. | |
complex | String | String data type constrained by a regular expression. | |
complex | String | String data type constrained by a regular expression. | |
complex | String | String data type constrained by a regular expression. | |
complex | String | String data type constrained by a regular expression. |
Types in Source Data
Depending on the source system, imported data may be typed to Alteryx data types according to one of the following methods.
Tip
For each method, Designer Cloud attempts to map the source data to one of the above data types. For schematized sources, however, you may wish to use the original data types in the source. Optionally, you can choose to disable the mapping of source to internal data type. See "Type Inference" below.
Schematized files
Some file formats, such as Avro or Parquet, are stored in a non-readable format. Part of the metadata associated with the file is information identifying the schema of the file. A schema represents the data types and other constraints of individual columns. It can be read independently of the data in the source table.
Schematized tables
For relational sources, schema information is typically stored with the table. This schema information defines data type validation within the datastore and can be read independently from the source table.
Tip
Database schemas can be used to define a class of tables to ensure consistency within a database.
Inferred data types
In most cases, an imported data source is assigned a data type for each column based on a review of a subset of the data. For example, a CSV file contains no information about the data types of individual columns. The data types for each column must be assigned by Designer Cloud. This process is called type inference. For more information, see "Type Inference" below.
Type Inference
By default, the Trifacta Application applies type inference for imported data. The application attempts to infer a column's appropriate data type in the application based on a review of the first lines in the sample.
Tip
In many programming languages, a column must be explicitly "type cast" to a data type as part of a functional operation. Wrangle handles this typecasting for you through the process of type inference.
Note
Mapping source data types to Alteryx data types depends on a sufficient number of values that match the criteria of the internal data type. The mapping of import types to internal data types depends on the data.
Type inference needs a minimum of 25 rows of data in a column to work consistently.
If your dataset has fewer than 20 rows, type inference may not have sufficient data to properly infer the column type.
In some datasets, the first 25 rows may be of a data type that is a subset of the best matching type. For example, if the first 25 rows in the initial same match the Integer data type, the column may be typed as Integer, even if the other 2,000 rows match for the Decimal data type. If the column data type is unmodified:
The data is written out from Designer Cloud as Integer data type. This works for the first 25 rows.
The other 2,000 rows are written out as null values, since they do not match the Integer data type. If the source data used decimal notation (e.g.
3.0in the source), then those values are written out as null values, too.
In this case, it may be easier to disable type inference for this dataset.
Tip
If you are having trouble getting your imported dataset to map to expected data types, you can disable type inference for the individual dataset. For more information, see Import Data Page.
After data is imported, the Trifacta Application provides some mechanisms for applying stronger typecasting to the data. Example:
If all input values are double-quoted, then Designer Cloud evaluates all columns as String type. As a result, type inference cannot be applied.
Since non-String data types cannot be inferred, then the first row cannot be detected as anomalous against the inferred type (String). Column headers cannot be automatically detected from double-quoted source files.
Tip
The default data type is String. If the Trifacta Application is unable to evaluate a column's data type, the type is mapped to String data type. Within the application, you can use functions to remap the data type or to parse values according to a specified type.
For more information, see "Working with Data Types" below.
Disable type inference
For schematized files or tables, the Trifacta Application inference of data type from the source may result in incorrect initial typing of a dataset's columns in the application. As needed, you can disable type inference for the following:
Note
When type inference is disabled for imported datasets, it is not disabled within the Trifacta Application. For more information, see "Type inference in the application" below.
Disable for individual files: In the Import Data page, select the file. In the right-hand column, click Edit Settings. For more information, see File Import Settings.
Disable for individual tables: In the Import Data page, select the table. In the right-hand column, click Edit Settings. For more information, see Relational Table Settings.
Disable for individual connections: In the Connections page, edit the connection. In the Edit Connection window, select
Disabledunder Default Column Data Type Inference. By default, all datasets through this connection have type inference disabled. For more information, see Create Connection Window.
Type inference in the application
Within the Trifacta Application, column data types may be re-inferred based on your activities in the Transformer page:
Note
Disabling type inference does not disable the re-inference of types in the Transformer page.
The following general actions may result in column data types being re-inferred:
After a sample is taken, column data types are inferred based on the first set of rows in the sample.
If a transform or function is provided with a data type that does not match the expected input data type, the values are typecast to the expected output, so you may see changes to the data type of the output to better align with the function.
Multi-dataset operations generally do not cause re-inferring of data types. However, if there is a mismatch of data types between two columns in a union operation, for example, the data type of the first dataset is preferred.
Working with Data Types
After data has been imported, you can remap individual column types through recipe steps. For more information, see Change Column Data Type.
Data types in the grid
When a sample is loaded, the data types and their formats for each column are inferred by default. Data types and formatting information is displayed for each column in the Transformer page.
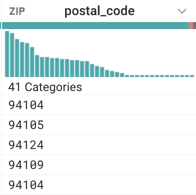 |
Figure: Column header example
At the top of each column, you can review graphical representations of type information:
Data type indicator: To the left of the column name, you can see a graphic of the data type. In the above, the data type is set to Zip code.
Tip
Select the data type indicator to change the column to a different data type. This change is added as a step in your recipe. See "Changing the data type."
Data quality bar: Below the column name, you can see a bar indicating the relative percentage of valid, invalid and empty values in the column, compared to the listed data type.
Green: Valid for the data type
Red: Invalid for the data type
Gray: empty or null
Tip
Select one of the colored bars to be prompted by a set of transformation suggestions that can be applied to the selected set of values.
Column histogram: Below the data quality bar, you can see the distribution of values within the column. The column histogram may represent the data in different ways, depending on the column's data type.
Tip
Click or SHIFT-click values in the histogram to be prompted for transformation suggestions that can be applied to the selected values.
For more information, see Data Grid Panel.
For more information, see Column Menus.
Changing the data type
Change the data type through the data type menu at the top of a column.
Tip
For some types, such as Datetime type, you must select a data format when you are selecting the type. See below.
Note
Changing the data type may not change the underlying logical type. For example, if you change a String column to a Gender column, the underlying data is still stored as String values.
Changing type across multiple columns
To change the data type for multiple columns, you can a transformation similar to the following, which changes the data type from the reqProdId column to the prodC column and all columns in between:
Transformation Name |
|
|---|---|
Parameter: Columns | Range |
Parameter: Column list | reqProdId~prodC |
Parameter: New type | String |
Changing the data format
You can use the following functions to apply formatting on top of a column of a specified data type. For example, depending on your locale, numbers may require different formatting for use of the decimal point and the digit separator.
Note
When you apply a formatting function to a column, the data appears in the specified format in the Trifacta Application, but the underlying data is unmodified. Formatting changes appear as a step in your recipe and are applied to the generated results.
Formatting Function | Applicable Data Type | Description |
|---|---|---|
Integer, Decimal | Formats a numeric set of values according to the specified number formatting. Source values can be a literal numeric value, a function returning a numeric value, or reference to a column containing an Integer or Decimal values. | |
Datetime | Formats a specified Datetime set of values according to the specified date format. Source values can be a reference to a column containing Datetime values. | |
Datetime | Formats a set of Unix timestamps according to a specified date formatting string. |
Type functions
The Trifacta Application provides a set of functions for managing types.
Validation functions
These functions can be used to test for valid or invalid values against a specific data type.
Function | Description |
|---|---|
Tests whether a set of values is valid for a specified data type and is not a null value. | |
Tests whether a set of values is not valid for a specified data type. | |
The | |
The |
Parsing functions
These functions can be used to parse String values against a specific data type.
Function | Description |
|---|---|
Evaluates a String input against the Integer datatype. If the input matches, the function outputs an Integer value. Input can be a literal, a column of values, or a function returning String values. | |
Evaluates a String input against the Decimal datatype. If the input matches, the function outputs a Decimal value. Input can be a literal, a column of values, or a function returning String values. | |
Evaluates a String input against the Boolean datatype. If the input matches, the function outputs a Boolean value. Input can be a literal, a column of values, or a function returning String values. | |
Evaluates an input against the default input formats or (if specified) an array of Datetime format strings in their listed order. If the input matches one of the formats, the function outputs a Datetime value. | |
Evaluates a String input against the Array datatype. If the input matches, the function outputs an Array value. Input can be a literal, a column of values, or a function returning String values. | |
Evaluates a String input against the Object datatype. If the input matches, the function outputs an Object value. Input can be a literal, a column of values, or a function returning String values. | |
Evaluates an input against the String datatype. If the input matches, the function outputs a String value. Input can be a literal, a column of values, or a function returning values. Values can be of any data type. |
Managing null and empty values
These functions allow you to generate or test for missing or null values.
Function | Description |
|---|---|
The | |
The | |
The | |
The | |
The |
Type Conversions on Export
The Trifacta Application attempts to map the data types that you have specified to match data types in the target platform.
Note
Values that do not match the data type of the target system for a column are subject to the method by which the target system handles mismatches. Rows could be dropped. Values can be rendered as null values. You should attempt to verify that all columns have valid values before generating results.
Note
Missing or null values may be treated differently between target systems. Additionally, if these systems feed downstream systems, those systems may have independent rules for managing missing or null values.
Type Conversions
Item | Description |
|---|---|
This section covers data type conversions between the Trifacta Application and the Avro file format. | |
This section covers data type conversions between the Trifacta Application and DB2 databases. | |
This section covers data type conversions between the Trifacta Application and Oracle databases. | |
This section covers data type conversions between the Trifacta Application and MySQL databases. | |
This section covers data type conversions between the Trifacta Application and the Parquet file format. | |
This section covers data type conversions between the Trifacta Application and PostgreSQL databases. | |
This section covers data type conversions between the Trifacta Application and Redshift. | |
This section covers data type conversions between the Trifacta Application and Snowflake databases. | |
This section covers data type conversions between the Trifacta Application and Salesforce. | |
This section covers data type conversions between the Trifacta Application and SQL Server databases. | |
This section covers data type conversions between the Trifacta Application and Teradata databases. | |
This section covers data type conversions between the Trifacta Application and SharePoint. |
For more information, see Type Conversions.