Snowflake
Obsolescencia de la autenticación básica
En Snowflake, la autenticación básica (nombre de usuario y contraseña) quedará obsoleta por completo en marzo de 2026. Después de esta fecha, las conexiones que utilicen la autenticación básica ya no funcionarán.
Para evitar interrupciones, actualiza tus conexiones a un método de autenticación más seguro (por ejemplo, OAuth, Azure AD o autenticación de par de claves) antes de la fecha límite. Para obtener ayuda, consulta el artículo de la base de conocimientos.
Requisitos de configuración del controlador | Para procesamiento en base de datos y para evitar errores al escribir datos con la herramienta Datos de salida, especifica un almacén (warehouse), un esquema (schema) y una base de datos (database) en el controlador. |
Tipo de soporte | Lectura y escritura; en base de datos. |
Se validó en | Versión de base de datos: 6.8.1 Versión de cliente de ODBC: 3.12.0.1000 64 bits |
Herramientas de Alteryx utilizadas para establecer conexiones
Procesamiento de flujos de trabajo estándares

Procesamiento de flujos de trabajo en base de datos


Herramienta Datos de entrada
Selecciona la herramienta Datos de salida y navega a la ventana Datos de entrada - Configuración. Selecciona el menú desplegable en Conectar un archivo o una base de datos.
Ve a Conexiones de datos > Todas las fuentes de datos > Snowflake > ODBC.
En la ventana emergente Conexión ODBC de Snowflake, ingresa tu Nombre de usuario y Contraseña.
En la ventana Elegir tabla o especificar consulta, selecciona Tablas > tabla > Aceptar.
Modo clásico
Si prefieres trabajar con el Modo clásico, ve a Opciones > Configuración del usuario > Editar la configuración del usuario > y selecciona la casilla de verificación Usar el modo clásico para el menú de opciones de las herramientas Datos de entrada/salida.
Para especificar una consulta, selecciona la pestaña Editor de SQL. Ingresa la consulta en el espacio disponible y selecciona la Consulta de prueba > Aceptar.
Selecciona la herramienta Datos de salida y ve al menú > Opciones.
Selecciona Configuración del usuario > Editar la configuración del usuario > Selecciona la casilla de verificación Usar el modo clásico para el menú de opciones de las herramientas Datos de entrada/salida.
Ve al panel Datos de salida - Configuración > Escribir en archivo o en base de datos y selecciona el ícono del menú desplegable.
Selecciona Otras bases de datos > Selecciona Carga masiva de Snowflake….
También puedes utilizar la herramienta Datos de entrada (modo clásico) para seleccionar los archivos y las fuentes de datos.
Si quieres cambiar al Modo clásico, sustituye la herramienta Datos de salida por una nueva herramienta y selecciona el lienzo, o presiona F5 para actualizar.
Herramienta Datos de salida
Para admitir totalmente la lectura y escritura de tablas y columnas, establece la opción Estilo de SQL de tabla/nombre del campo de Alteryx Designer en Entre comillas. Con esta opción, se selecciona específicamente la tabla en la base de datos y, si seleccionas Ninguno, se generan resultados en mayúsculas.
Revisa los siguientes puntos antes de configurar una conexión masiva de Snowflake:
Solo puedes escribir datos con el cargador masivo de Snowflake.
Después de escribir los datos en la nueva salida, el cargador masivo de Snowflake elimina los datos escritos del depósito S3.
La longitud máxima permitida para los campos de texto es de 16 777 216 bytes.
Para obtener más información, consulta la Documentación de Snowflake.
Nota
A partir de la versión 2023.2, Designer cancela todas las ejecuciones en base de datos no completadas al cancelar el flujo de trabajo localmente. Esto te permite desbloquear tus pipelines de datos. La característica mejora la interacción general de la base de datos.
Configurar una conexión ODBC
En el Administrador de origen de datos ODBC, selecciona el controlador de Snowflake y selecciona Configurar.
Ingresa tu configuración de conexión y las credenciales.
Selecciona Aceptar para guardar la conexión.
Nota
Para admitir totalmente la lectura y escritura de tablas y columnas con camel case, se debe establecer la opción Estilo de SQL de tabla/nombre del campo de Alteryx Designer en Entre comillas.
JWT de Snowflake para la autenticación con par de claves
Con la versión 2024.1, es más fácil que nunca usar la autenticación de archivo de claves (JWT) para Snowflake en Designer con DCM. Simplemente selecciona tu conexión de Snowflake y busca la autenticación de par de claves de la lista de fuentes de datos disponibles.
Para configurar un JWT de Snowflake a través del controlador ODBC:
Crea el token según las instrucciones de Snowflake.
Establece el Autenticador en el DSN de ODBC en SNOWFLAKE_JWT.
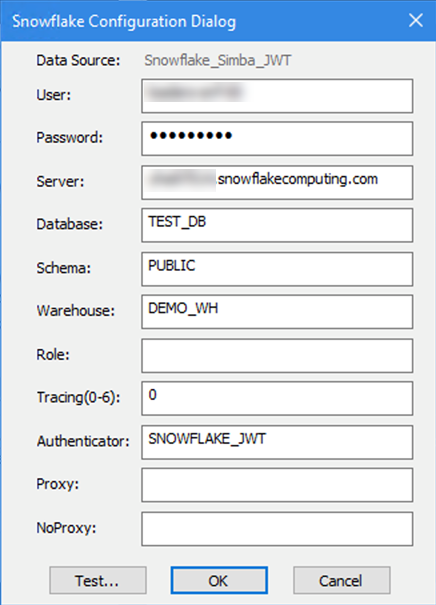
En Alteryx, la cadena de conexión tiene que apuntar a la ubicación del archivo, por ejemplo:
odbc:DSN=Simba_Snowflake_JWT;UID=user;PRIV_KEY_FILE=G:\AlteryxDataConnectorsTeam\OAuth project\PEMkey\rsa_key.p8;PRIV_KEY_FILE_PWD=__EncPwd1__;JWT_TIMEOUT=120Para obtener más instrucciones, consulta la documentación de Snowflake.
Para obtener más información sobre cómo configurar la autenticación de JWT de Snowflake para tu cuenta de Snowflake, consulta la documentación de Snowflake.
Configurar una conexión masiva de Snowflake para escribir datos
La carga masiva se admite para conexiones que utilizan DSN y conexiones sin DSN.
Para configurar el cargador masivo con una cadena de conexión sin DSN, construye la cadena de conexión de forma manual. La cadena tiene que contener los parámetros necesarios para escribir en Snowflake y los necesarios para el entorno de ensayo. Los parámetros necesarios para Snowflake se pueden encontrar en la documentación de Snowflake. Los parámetros necesarios para el entorno de ensayo se pueden encontrar a continuación.
Ejemplo de cadena de conexión:
snowbl:Driver= {SnowflakeDSIIDriver};Server=customerinstance.snowflakecomputing.com;Database=TEST_DB; Warehouse=TEST_WAREHOUSE;schema=PUBLIC;UID=user;PWD=password;Bucket=S3Bucket; Access=IAMAccessKey;Secret=IAMSecretKey;URL=s3.amazonaws.com;Region=us-east-1
Para configurar el cargador masivo con un DSN, usa la interfaz de usuario y sigue los pasos a continuación:
Selecciona la herramienta Datos de salida y ve al panel Datos de salida (1) - Configuración.
En Escribir en archivo o base de datos, selecciona el menú desplegable > Ve a la ventana Conexiones de datos para seleccionar la pestaña Fuentes de datos > Todas las fuentes de datos > Snowflake > Selecciona Masivo.
En la ventana Conexión masiva de Snowflake, selecciona la pestaña Local > Ingresa tus credenciales en los espacios Nombre de usuario (opcional) y Contraseña (opcional) > Selecciona Aceptar para ver la ventana emergente Tabla de salida.
Escribe el nombre de la tabla (u hoja de trabajo) para el archivo de salida especificado, ya sea con el nombre de la tabla o con el formato db.schema.tablename: Esta es tu tabla completamente calificada.
Bajo Opciones en el panel Datos de salida (1) - Configuración, selecciona en el menú desplegable Estilo de SQL de tabla/nombre del campoEntre comillas o Ninguno.
En Tomar nombre de archivo/tabla del campo, decide si quieres seleccionar la casilla de verificación para ver el menú desplegable Anexar sufijo al nombre del archivo o de la tabla. Si seleccionas la casilla de verificación, elige entre las siguientes opciones:
Anexar sufijo al nombre del archivo o de la tabla.
Anteponer el prefijo al nombre del archivo y/o de la tabla.
Cambiar el nombre del archivo/tabla
Cambiar toda la ruta del archivo.
Si seleccionas la casilla de verificación Anexar sufijo al nombre del archivo o de la tabla, en Campo que contiene el nombre del archivo o parte del nombre del archivo, selecciona una de las siguientes opciones:
SEQUENCE_CATALOG
SEQUENCE_SCHEMA
SEQUENCE_NAME
SEQUENCE_OWNER
DATA_TYPE
NUMERIC_PRECISION
NUMERIC_PRECISION_RADIX
NUMERIC_SCALE
START_VALUE
MINIMUM_VALUE
MAXIMUM_VALUE
NEXT_VALUE
INCREMENT
CYCLE_OPTION
CREATED
LAST_ALTERED
COMMENT
Decide si quieres seleccionar la casilla de verificación Conservar campo en la salida para la opción que has seleccionado en el menú desplegable a fin de utilizarla con los datos de la tabla.
Métodos para organizar datos en etapas con una conexión masiva de Snowflake
Configura una conexión masiva de Snowflake para escribir en Amazon S3
En la ventana Datos de salida - Configuración, selecciona Escribir en archivo o base de datos y selecciona Otras bases de datos > Carga masiva de Snowflake para mostrar la ventana Conexión masiva de Snowflake.
Selecciona un Nombre de la fuente de datos o selecciona Administrador de ODBC para crear uno. Para obtener más información, ve a Conexiones de bases de datos ODBC y OLEDB.
Ingresa un Nombre de usuario y una Contraseña, según corresponda.
En Amazon S3, ingresa tu clave de acceso de AWS y tu clave secreta de AWS.
En Cifrado de clave secreta, selecciona una opción de cifrado:
Ocultar: oculta la contraseña mediante un cifrado mínimo.
Cifrar para la maquina: cualquier usuario del equipo tiene acceso completo a la conexión.
Cifrar para el usuario: el usuario que ha iniciado la sesión tiene acceso completo a la conexión en cualquier computadora.
En Punto de conexión, selecciona una de las siguientes opciones:
Default (predeterminado): Amazon determina el punto de conexión según el bucket seleccionado.
Punto de conexión específico: para especificar una región S3 en la que reside el depósito, especifica un punto de conexión personalizado o selecciona uno de los puntos de conexión ingresados anteriormente.
El depósito S3 debe estar en la región S3 especificada. De lo contrario, se muestra un error que explica que el bucket al que estás intentando acceder debe tener el punto de conexión especificado en la dirección. Envía todas las solicitudes futuras a este punto de conexión.
Selecciona Default (predeterminado) para cerrar la ventana de error.
(Opcional) Selecciona Utilizar Signature V4 para la autenticación para aumentar el nivel de seguridad más allá de Signature Version 2 predeterminado. Esta opción se activa automáticamente para las regiones que requieren la versión Signature V4. Las regiones creadas después del 30 de enero de 2014 solo admiten Signature Version 4. Las siguientes regiones requieren autenticación de Signature Version 4:
Región del este de los EE. UU. (Ohio)
Región de Canadá (central)
Región de Asia Pacífico (Mumbai)
Región de Asia Pacífico (Seúl)
Región de la UE (Frankfurt)
Región de la UE (Londres)
Región de China (Beijing)
Selecciona un método de Cifrado en el lado del servidor para subir a un depósito de Amazon S3 cifrado. Consulta la Guía para el desarrollador del servicio de almacenamiento simple de Amazon.
Ninguno (predeterminado): no se utiliza ningún método de cifrado.
SSE-KMS: utiliza la encriptación del servidor con las claves administradas por AWS KMS. También puedes proporcionar un Id. de clave de KMS. Al seleccionar este método, la opción Usar la firma V4 para la autenticación está habilitada de forma predeterminada.
Ingresa el Nombre del bucket del bucket de AWS en el que se almacenan los objetos de datos.
Configura Opciones de formato de archivo adicionales en la ventana Datos de salida - Configuración. Para obtener más información, consulta Opciones de formato de archivo.
Configurar una conexión masiva de Snowflake para escribir en el almacenamiento local
Ahora tienes tres opciones mejoradas para elegir cuando organizas en etapas los datos en tu unidad local.
Selecciona la herramienta Datos de salida y ve al panel Datos de salida (1) - Configuración > En Escribir en archivo o base de datos, ve a la ventana Conexiones de datos y selecciona la pestaña Fuentes de datos> Todas las fuentes de datos > Snowflake > Selecciona Masivo. En la ventana Conexión masiva de Snowflake > Selecciona la pestaña Local >
Etapa de usuario: Etapa interna proporcionada por Snowflake, asociada con el usuario.
Selecciona Usuario > Selecciona Aceptar. En la ventana emergente Tabla de salida, escribe el nombre de la tabla (u hoja de trabajo) para el formato de archivo de salida especificado con el nombre de la tabla o con el formato db.schema.tablename: Esta es tu tabla completamente calificada. Selecciona Guardar. Bajo Opciones en el panel Datos de salida (1) - Configuración, selecciona en el menú desplegable de Estilo de SQL de nombre de tabla/campoEntre comillas o Ninguno.
Etapa de tabla: Etapa interna proporcionada por Snowflake, asociada con la tabla.
Selecciona Etapa de tabla > Selecciona Aceptar. En la ventana emergente Tabla de salida, escribe el nombre de la tabla (u hoja de trabajo) para el formato de archivo de salida especificado con el nombre de la tabla o con el formato db.schema.tablename: Esta es tu tabla completamente calificada. Selecciona Guardar. Bajo Opciones en el panel Datos de salida (1) - Configuración, selecciona en el menú desplegable de Estilo de SQL de nombre de tabla/campoEntre comillas o Ninguno.
Etapa interna nombrada: En la base de datos de Snowflake, crea y ejecuta un comando CREATE STAGE y proporciona el nombre de la etapa a la configuración de la herramienta.
Nota
El tamaño máximo del campo es 16 MB. Si se supera el umbral de tamaño del campo, se producirá un error y no se escribirán los datos.
Tipo de compresión: Las opciones son “Sin compresión” o “Comprimir con GZip”.
Sin compresión: Los archivos se almacenan y se cargan como CSV
Comprimir con GZip: los archivos CSV se comprimen con GZIP
Tamaño del trozo en MB (de 1 a 999): Esta opción te permite seleccionar el tamaño de cada CSV que se organiza localmente.
Nota
El tamaño real del archivo puede variar con respecto al tamaño del trozo seleccionado debido al formato y la compresión subyacentes.
Número de subprocesos (de 1 a 99): esta opción especifica la cantidad de subprocesos que se utilizarán para cargar archivos a Snowflake. El rendimiento puede mejorar en archivos más grandes cuando se aumenta este valor. Si se ingresa 0, se utilizará el valor predeterminado por Snowflake (4).
Desde la etapa, cada copia en la tabla puede contener hasta 1000 archivos. Si hay más de 1000 archivos en la etapa, es posible que veas varias copias en instrucciones. Es un requisito de Snowflake para copiar en instrucciones usando archivos. Para obtener más información, ve al Portal de Snowflake.
Puedes encontrar más información sobre las opciones de tipo de compresión, tamaño de trozos en MB y número de subprocesos en el Portal de Snowflake.