Overview of GCP Integration
This section provides a high-level overview of how Dataprep by Trifacta integrates with the Google Cloud Platform.
Note
Dataprep by Trifacta maintains and updates all components in use with the Google Cloud Platform in accordance with Google policies and deprecation dates. Version deprecation warnings are addressed prior to their posted dates.
Overview
Dataprep by Trifacta is a managed, serverless service embedded in the Google Cloud Platform that allows you to process jobs to transform data volumes of virtually any size.
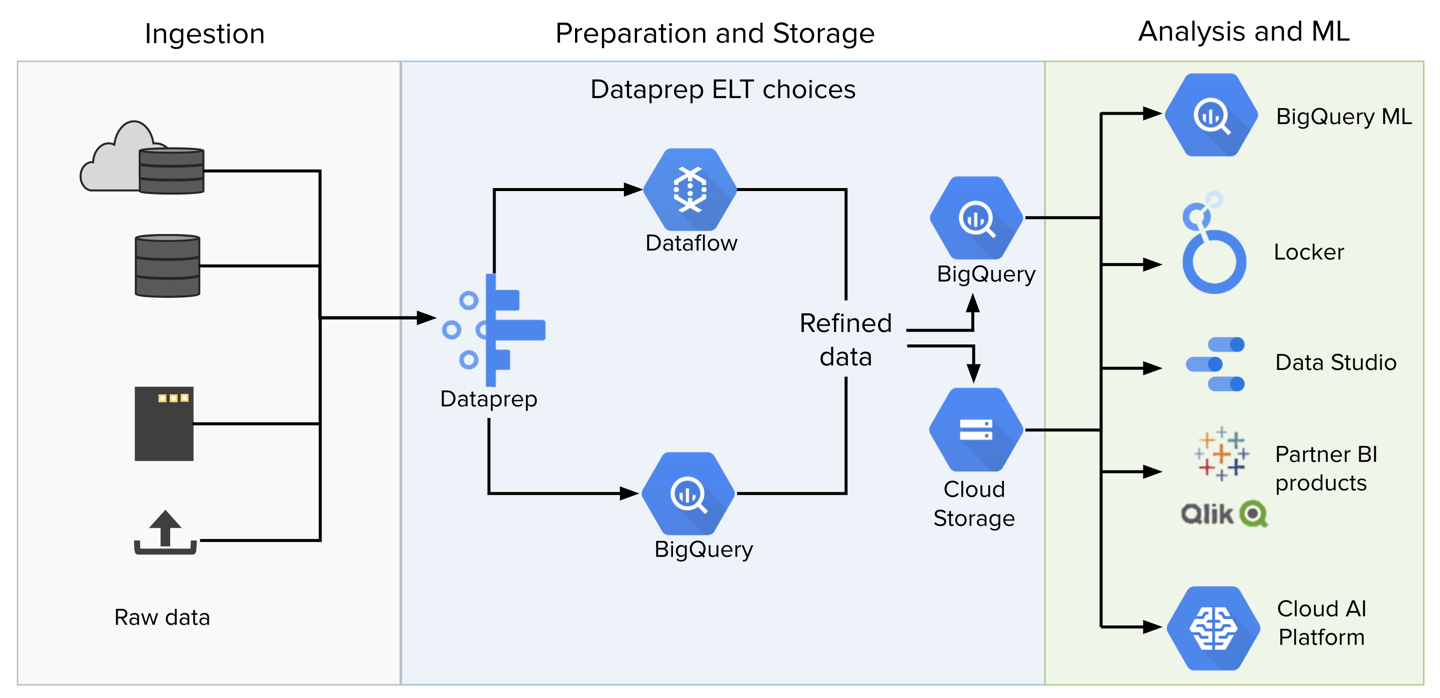
Figure: Dataprep Data Flow Diagram
In the above diagram, you can see how Dataprep by Trifacta fits into a typical data pipeline.
Ingestion: Raw data can be imported from relational sources, datawarehouses, file-based storage, or uploaded from local desktop.
Cloud Storage and BigQuery are native connections of Dataprep by Trifacta. These are discussed below.
Preparation: Imported data is transformed in one of the following transformation engines:
is a Google-hosted service for job execution. Dataprep by Trifacta seamlessly integrates with this running environment.
BigQuery: Jobs that are sourced from data in BigQuery can be executed natively in BigQuery via pushdown capabilities. These jobs run much faster, as the data never leaves its source environment. Output data for these job types is written back to BigQuery.
is an embedded service of the Trifacta node. This environment is best suited for running small jobs that do not require large-scale processing resources.
Storage: When a job is completed, it can be written to one of the following datastores:
: For storing file-based outputs.
BigQuery: For writing table-based outputs.
Dataprep by Trifacta : Supports connections to relational datastores.
Analysis and ML: Dataprep by Trifacta is intended to deliver clean, consistent, and reliable data to downstream systems for analytics, machine-learning, and reporting or visualization.
Projects Overview
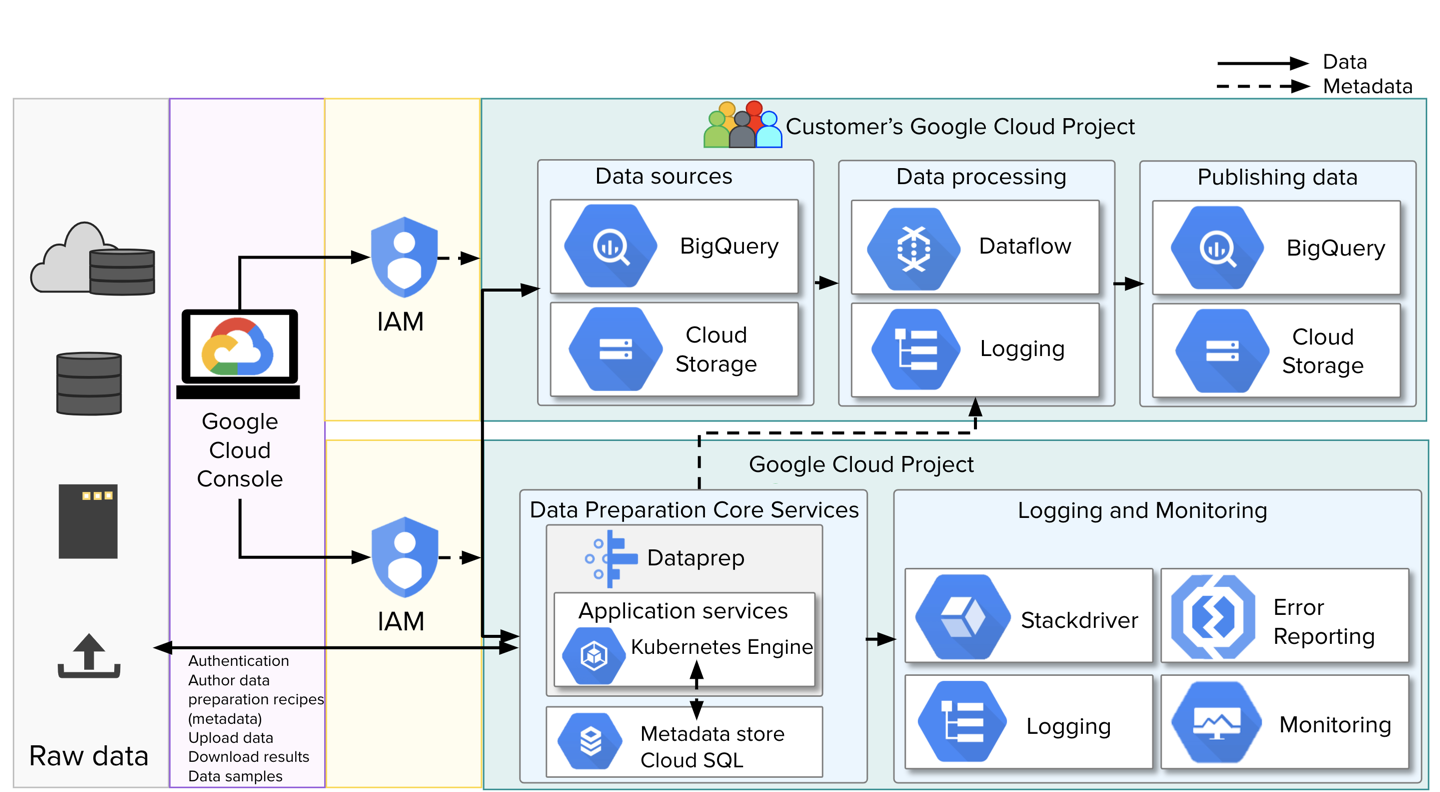
Figure: Projects, services, and IAM roles
The above diagram shows the high-level architecture for Dataprep by Trifacta. In this environment, activities are separated between two projects:
Customer's Google Cloud Project: Data storage and transformation is executed within the customer's project and organization.
Product Google Cloud Project: This project hosts the Dataprep service, which includes application services, metadata database, and other platform services for monitoring, logging, and error reporting.
Note
In the above diagram, you can see the data that is transferred in and out of the Alteryx project is limited to authentication data, recipes (transformation metadata), downloaded job results, and samples of data, which are delivered through the web browser to the user. This data is streamed and stored only in memory.
Note
In this model, data is typically not streamed between the Customer and Alteryx project. Instead, remote procedure calls are executed through Google Services into the customer project, where data access, transformation, and outputs occur.
Both projects are secured using IAM roles.
When Dataprep by Trifacta is enabled for a project, the default IAM role secures access to project data and all services required to execute jobs on Trifacta Photon and Dataflow for BigQuery and Cloud Storage.
The IAM role for the Alteryx project provides access to all services required to use the product.
IAM roles are governed through the Google Cloud Console.
Organizations
In the Google Cloud Platform, the organization is the base node for all user and data objects stored within the platform. Your Google Cloud Platform user account is tied to a root organization node. For more information on organization, see https://cloud.google.com/resource-manager/docs/creating-managing-organization.
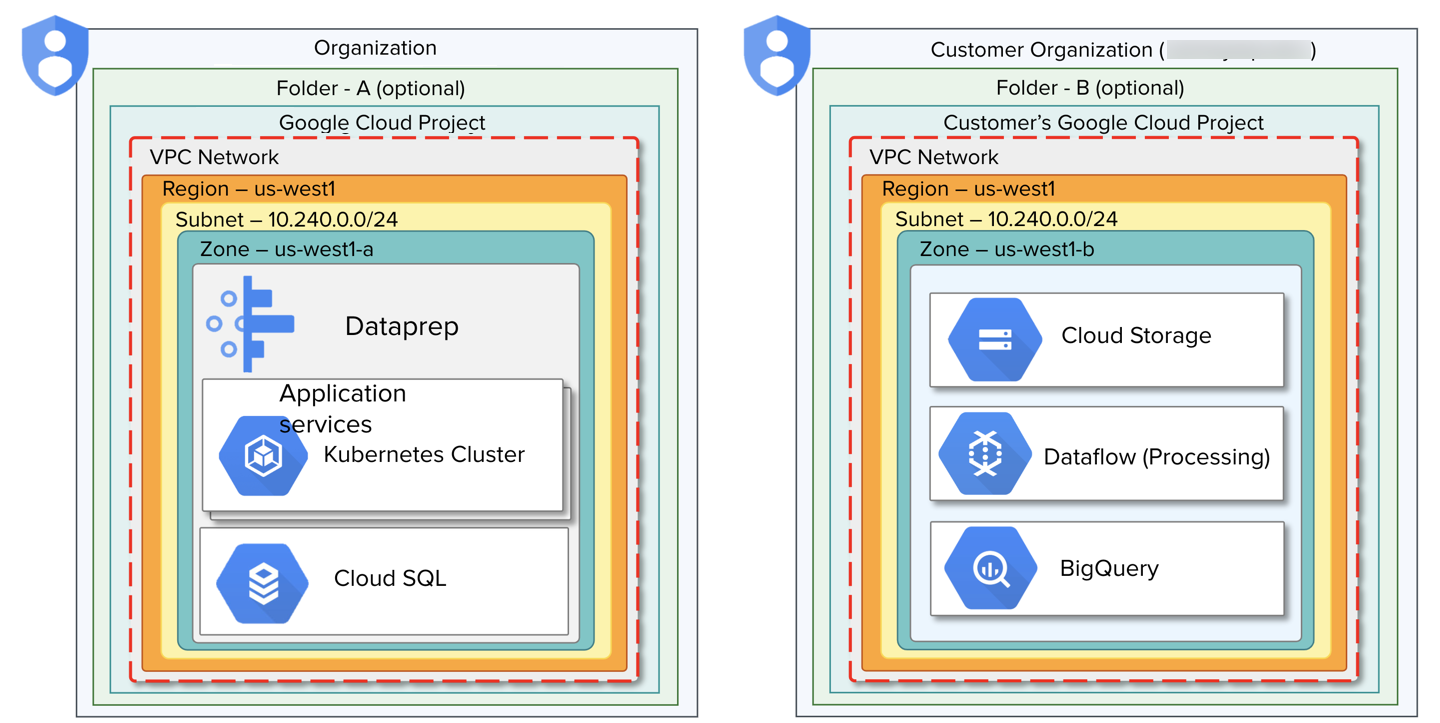
Figure: Two organization objects in the Google Cloud Platform: Product's and Customer's
Dataprep by Trifacta is managed within a dedicated Alteryx organization.
Your enterprise deployment in Google Cloud Platform is managed in another organization.
Hierarchy:
Organization
Folder: A structuring concept within an organization, a folder or set of folders can be used for grouping an organization's resources. For more information on folders, see https://cloud.google.com/resource-manager/docs/creating-managing-folders.
Project: In the Google Cloud Platform, a project is the fundamental structuring managing access to platform services and objects. For more information, see https://cloud.google.com/resource-manager/docs/creating-managing-projects.
VPC Network: A virtual private cloud (VPC) can be used to provide secure access to resources within an organization or project. This secure private cloud spans all supported regions. For more information, see https://cloud.google.com/vpc/docs/how-to.
Region: A region is a geographic region, which is used for scaling resources in a low-latency manner. For more information, see https://cloud.google.com/docs/geography-and-regions.
Subnet: - A VPC network consists of one or more useful IP address ranges. These subnets are not the same thing as a VPC network. See https://cloud.google.com/vpc/docs/subnets.
Zone: Within a region, a zone is considered a single-failure deployment area for Google Cloud Platform resources. For more information, see https://cloud.google.com/docs/geography-and-regions.
Resources: Services and data
Service Accounts and Data Access
Within the Google Cloud Platform, these account types are used by Dataprep by Trifacta.
Account Type | Description |
|---|---|
User Account | A user account is owned and linked to a specific user via a valid email address. For example: A user account can access resources based on the IAM roles associated with the user's account. |
Service Account | A service account is used by an application or a virtual machine instance. For example, a default Service Account is provided to each user of the Trifacta Application, so that the user can run jobs on Dataflow. You cannot log in to a service account using a browser. Service accounts can be impersonated. For example, all users of a project can use the same service account to run jobs on Dataflow. For more information on service accounts, see Google Service Account Management. |
Design Time Data Access
When you are building recipes through the Trifacta Application (design time), access to data is determined based on whether fine-grained access controls is enabled:
Fine-grained access | Access type |
|---|---|
Disabled (default) | Project service account credentials are used. |
Enabled | Each user's credentials are submitted with each request for data. Note Access to platform resources are based on the user's defined identity within the platform. |
Service account access to data at design time
When the product is enabled in a Google Cloud Platform project, a default service account is created, added to the project, and assigned to users of the project.
During signup for Dataprep by Trifacta, this service account is created and owned by the project owner.
The project owner can add more users to the project and then enable them to access Dataprep by Trifacta.
Access to resources is governed by this Project Service account.
Note
does not modify source data. All data is streamed from storage locations, such as Cloud Storage and BigQuery. All data access occurs over HTTPS.
Fine-grained access to data at design time
When fine-grained access controls are enabled, the individual user's credentials are applied to access data during recipe development. This governs the loading of initial samples and the generation of samples from data sources.
Note
Access to platform resources are based on the user's defined identity within the platform. Dataprep by Trifacta has no governance over these permissions.
For more information on the required permissions for the Dataprep Service Agent role, see https://console.cloud.google.com/iam-admin/roles/details/roles%3Cdataprep.serviceAgent.
For more information on fine-grained access controls and access-control lists (ACLs), see https://cloud.google.com/storage/docs/access-control.
Dataflow Access
During job execution on Dataflow, the Trifacta Application job manager submits the job as a set of remote procedure calls (RPCs) to the Dataflow service within the customer project. Dataflow the queries the appropriate repository to stream data in for transformation. For Cloud Storage or BigQuery, these datasets do not leave the customer's project. For more information, see Dataflow Running Environment.
Default service account
Dataflow jobs are submitted using the assigned service account for the submitting user.
By default, this service account is the same for all users of the project.
Access level to the backend repositories is determined based on the permissions included in the service account.
Companion service account
For Enterprise Edition, you can customize service accounts or per-user service accounts for finer-grained control.
BigQuery Access
If a job's source data and target location are both in BigQuery and other conditions apply, job execution may be optionally pushed down to the BigQuery transformation engine for execution as a series of SQL transformations. In this scenario:
Transformation occurs within the BigQuery execution engine and is governed by access permissions on the service account.
Read and write are enabled for BigQuery when using the default service account.
Note
If these conditions are not met, then the job falls back to Dataflow execution.
For more information, see BigQuery Running Environment.
Trifacta Photon Access
is an in-memory execution engine, which is used for two primary purposes:
Execution of small- to medium-sized jobs within the Trifacta node for faster responses.
Transformation of samples in-memory of the desktop client for display in the client browser.
Data access follows a similar model to Dataflow.
All data is streamed at design time and at runtime through the project's service account.
No data is written into the Alteryx organization.
For more information, see Trifacta Photon Running Environment.
IAM Roles
Identity and Access Management (IAM) roles enable administrators to manage access control by defining who (identity) has access (role) to which resources. IAM roles are used to manage:
Access to the Dataprep by Trifacta service
Access to the underlying services used by the product, including:
Dataflow
Cloud Storage
BigQuery
Other Google Cloud Platform services
Note
is designed to natively integrate with Google IAM, which enables the product to respect the access and permissions model defined within your organization.
Users are managed through Google Cloud Platform. In the Console, users are invited to a Dataprep by Trifacta project. By default:
Job execution is managed by the service account for the project.
New users are assigned a pre-defined role, which provides access to resources within the Trifacta Application.
Services on the Google Cloud Platform are governed by IAM roles. In most cases, project admins assign users to an IAM role.
Access model
The model for access management has the following components:
Member: The identity of a member is an email address associated with any of the following:
Google Account for end users
A service account (for apps and virtual machines)
A Google group
A Google Workspace or Cloud Identity domain that can access a resource.
Role: A role is a collection of permissions, which determine the permitted operations on a set of resources. When you grant a role to a member, you grant all permissions contained in the role.
Policy: An IAM policy is a collection of role bindings that bind one or more members to individual roles. To define who (member) has what type of access (role) to a resource:
You create a policy, and attach it to the resource.
Access to a resource is determined by:
A user is assigned one or more IAM roles.
Each IAM role contains a set of permissions, which define the permitted actions on a resource.
A policy is a set of roles binding user to role. A policy is attached to a resource.
Tip
When a user attempts to access a resource, the resource's policy is checked to determine whether the requested action is permitted for the authenticated user.
Default IAM roles
By default, Dataprep by Trifacta users are assigned the following IAM roles:
IAM Role | Description |
|---|---|
Dataprep User role | This IAM role provides access to the Dataprep by Trifacta service. |
Dataprep Service Agent role | This IAM role provides service account access to data sources that are available to the Google Cloud Platform project. In a typical deployment, this service account has access to all data sources within the project, and it is used anytime access to data is required. |
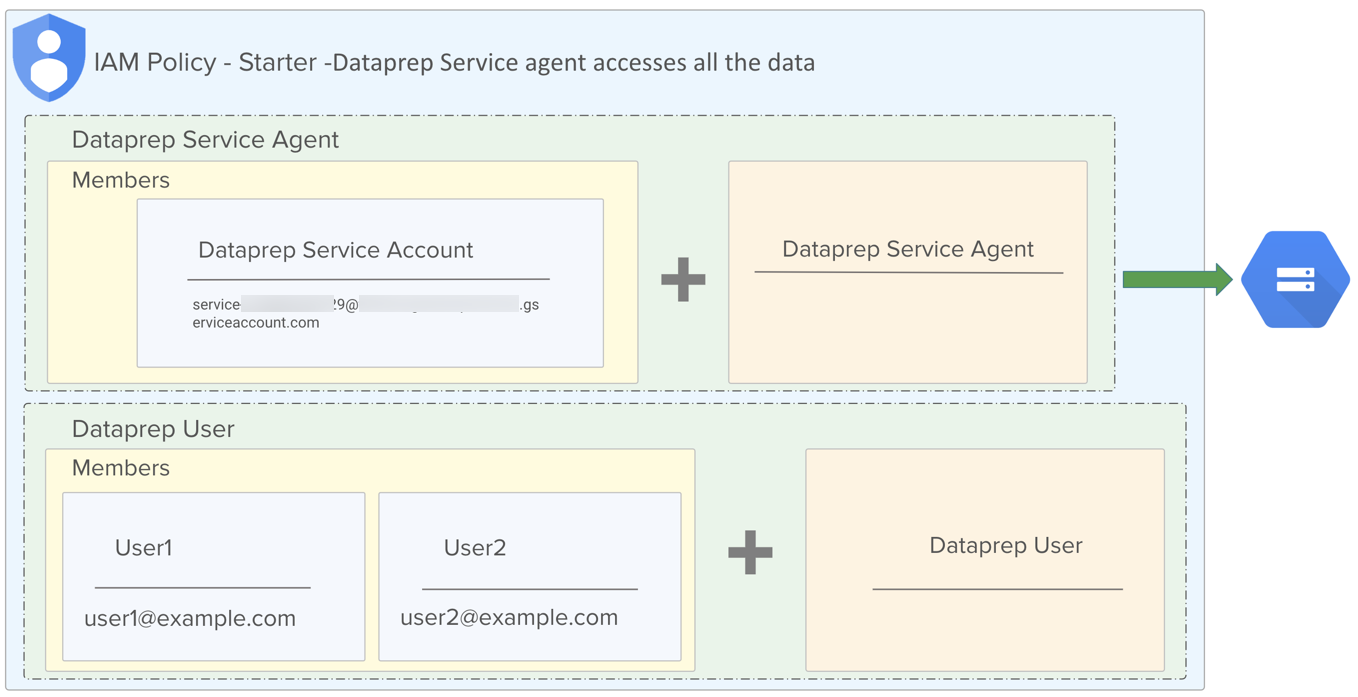
Figure: Default IAM roles
Permissions
Permissions determine the operations that are permitted to be performed on a resource, such as read, write, and delete. Typically, permissions are named in the following format:
<serviceName>.<resource>.<action>
where:
<serviceName>corresponds to the Google Cloud Platform service.<resource>corresponds to the resource within the service that is being accessed.<action>refers to the operation that is being performed (e.g. read, write, delete, and more).
Often, a permission corresponds to a REST API method. A Google Cloud Platform service exposes a set of REST API endpoints and methods, and permissions are used to define access to these endpoint/method combinations.
Tip
Permissions are not granted directly to users. Instead, you specify within an IAM role a set of permissions, which provide access to endpoint methods. Then, the role is granted to a specific user.
For more information on the required permissions, see Required Dataprep User Permissions.
Example role - Dataprep Service Agent
In the diagram, you can see some of the permissions that are granted to users who are assigned the Dataprep Service Agent role, which is a default role assigned to new users of Dataprep by Trifacta.

Figure: Dataprep Service Agent role
Using IAM with Cloud Storage makes it easy to limit a principal's permissions without having to modify each bucket or object permission individually. For example, the storage.objects.create permission allows you to create objects.
This permission is found in roles such as Storage Object Creator, where it is the only permission, and Storage Object Admin, where many permissions are bundled together.
User 1: If you grant the Storage Object Creator role to a member for a specific bucket, they can only create objects in that bucket.
User 2: If you grant another member the Storage Object Admin role for the bucket, they can do additional tasks, such as deleting objects within that bucket.
If these two members are granted these roles and no others, they won't have knowledge of any other buckets in your project.
User 3: If you give a third principal the Storage Object Admin role at the project level they have access to any object in any bucket of your project.
Role inheritance
Roles can be assigned at various levels of the organizational hierarchy.
Note
The total access level is determined by the additive permissions of each role.
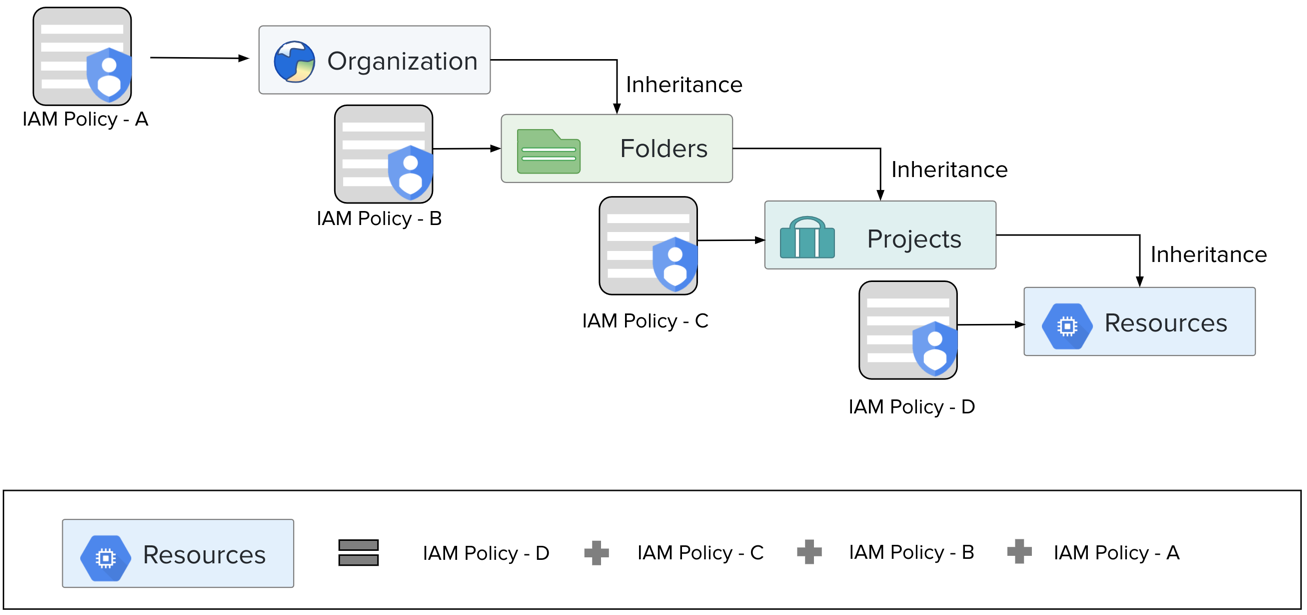
Figure: Role inheritance
Tip
By default, Dataprep by Trifacta IAM roles are assigned at the project level. IAM policies assigned at the individual resource level can override project-level assignments.
Types of IAM roles
These are the general types of IAM roles available in Google Cloud Platform:
IAM role type | Description |
|---|---|
Basic | These IAM roles include the Owner, Editor, and Viewer role. |
Predefined | Predefined roles provide granular access to a specific service or resource. These roles are managed by Google Cloud Platform. |
Custom | Custom roles are defined by an admin to provide granular access to resources based on permissions requirements of the enterprise. |
Customization of IAM roles
If your users require access to a specific Google Cloud Platform resource, you can:
Define an IAM role that contains the requisite policy.
Attach that policy to the resource.
Assign the IAM role to the user, in addition to the user's other roles.
Examples of resources that could require custom IAM roles:
Projects
Compute Engine instances
Cloud Storage buckets
When permissions are granted at the project level, the permissions are then inherited by all resources within that project. For example, to grant access to all Cloud Storage buckets in a project, grant access to the project instead of each individual bucket.
Service Accounts
A service account is a Google Cloud Platform account that is used by an application or service. These accounts are used by a service to perform authorized API calls to other services. Service accounts can be granted IAM roles, allowing them to be managed through the same permissions framework as the rest of your organization.
You cannot log in to a service account.
Service accounts can be impersonated by users and other service accounts.
Service accounts are accessed using key/secret pairs.
For more information, see https://cloud.google.com/iam/docs/service-accounts.
These service account types may be deployed for use with Dataprep by Trifacta. For more information on service accounts, see Google Service Account Management.
Default project service accounts
When Dataprep by Trifacta is enabled in a Google Cloud Platform project, these service accounts are created for use by the product with the platform.
Service Account Name | Owner | Service Account Identifier |
|---|---|---|
Compute Engine | Google, Inc. | <project-number>-compute@developer.gserviceaccount.com |
Dataprep by Trifacta | Alteryx | service-<project-number>@trifacta-gcloud-prod.iam.gserviceaccount.com |
These service accounts have the required permissions for basic access to execute jobs on Dataflow.
Tip
The <project-number> value indicates that the service account is available in an IAM role. Google creates these service accounts in your project to act on behalf of the listed services.
Service agent
A service agent is a Google term for a role containing a set of permissions inside a service account that permit operations in other services.
 |
Figure: Service account and service agent for Dataflow
Default integrations
The default service accounts provide access to the following key resources on the Google Cloud Platform, among others:
Dataflow: for execution of jobs
BigQuery: for writing and writing data and, in some cases, execution of jobs
Cloud Storage: for writing and writing data as the base storage layer.
Companion Service Accounts
Companion Service Accounts can be created and assigned to users to provide finer-grained access controls to resources for execution of Dataflow jobs.
Note
This feature may not be available in all product editions. For more information on available features, see Compare Editions.
Note
If there are changes to the default service accounts, those changes must be applied to any custom service accounts that you have deployed.
Note
Companion service accounts apply only to the execution of jobs on Dataflow. Other types of jobs are not affected by these service accounts.
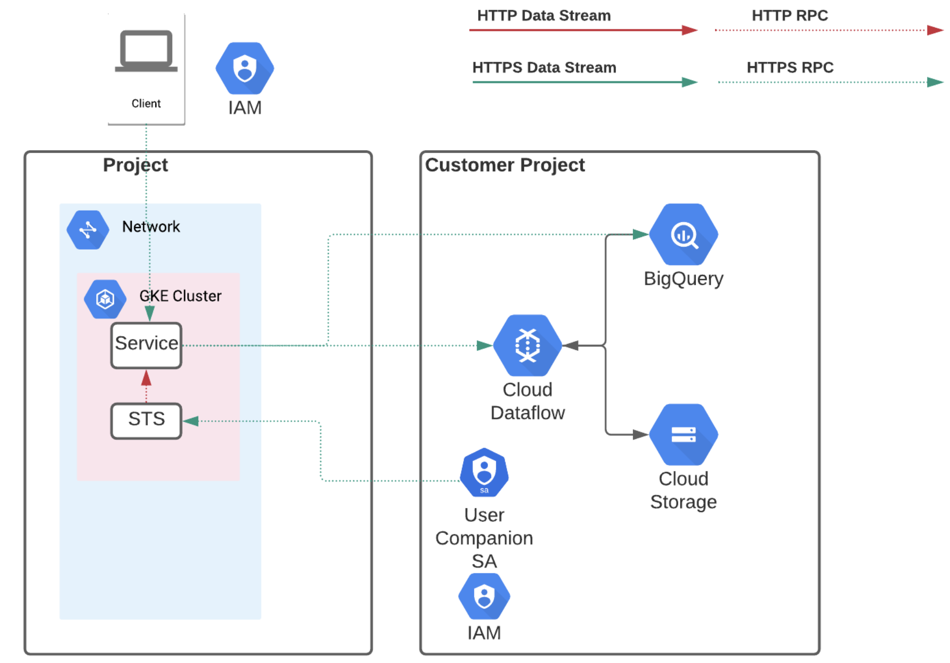
Figure: Companion Service Accounts
A companion service account is created by a Google Cloud Platform admin. Within Dataprep by Trifacta, a workspace admin can assign these accounts to individual users within a project.
For more information on service accounts, see Google Service Account Management.
Virtual Private Cloud
Google Virtual Private Cloud (VPC) provides networking for your resources and services as a virtualized network within Google Cloud Platform. A VPC is:
a globally available resource with a set of regional virtual subnets in discrete data centers connected via wide area network.
a resource that is logically isolated from other VPCs.
Dataprep by Trifacta can be configured to work within the constraints defined by your VPC in either of the following ways.
Shared VPCs
A Shared VPC environment may be particularly useful for a large organization, where IT can centrally manage extra security, common networking, and limiting of assignable addresses.
Tip
Using IAMs, a network administrator can apply granular controls over the services that are permitted to use the shared subnetwork.
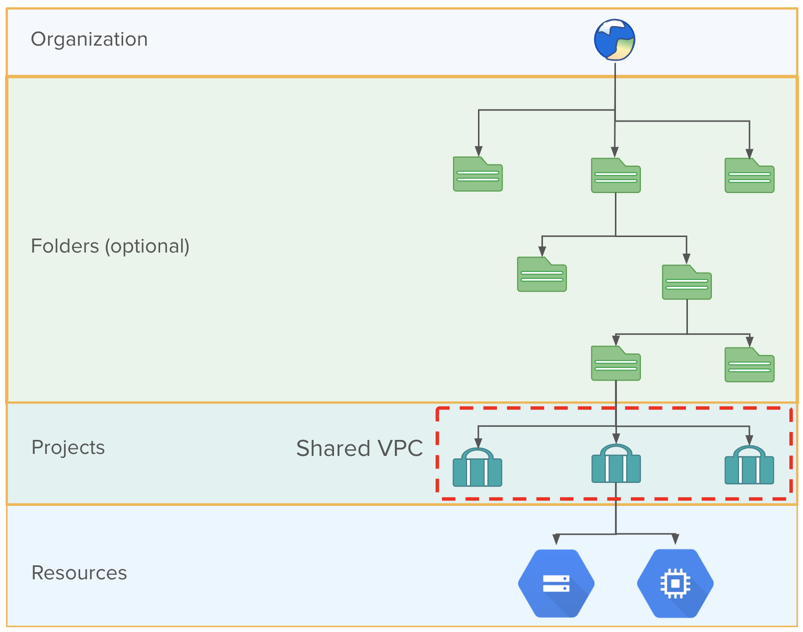
Figure: Shared VPC concept
VPC firewall rules
VPC firewall rules let you allow or deny connections to or from your virtual machine (VM) instances. Enabled VPC firewall rules are always enforced, protecting your instances regardless of their configuration and operating system, even if they have not started up.
Every VPC network functions as a distributed firewall. While firewall rules are defined at the network level, connections are allowed or denied on a per-instance basis. The VPC firewall rules apply to connections between your instances and other networks and between individual instances within the same network.
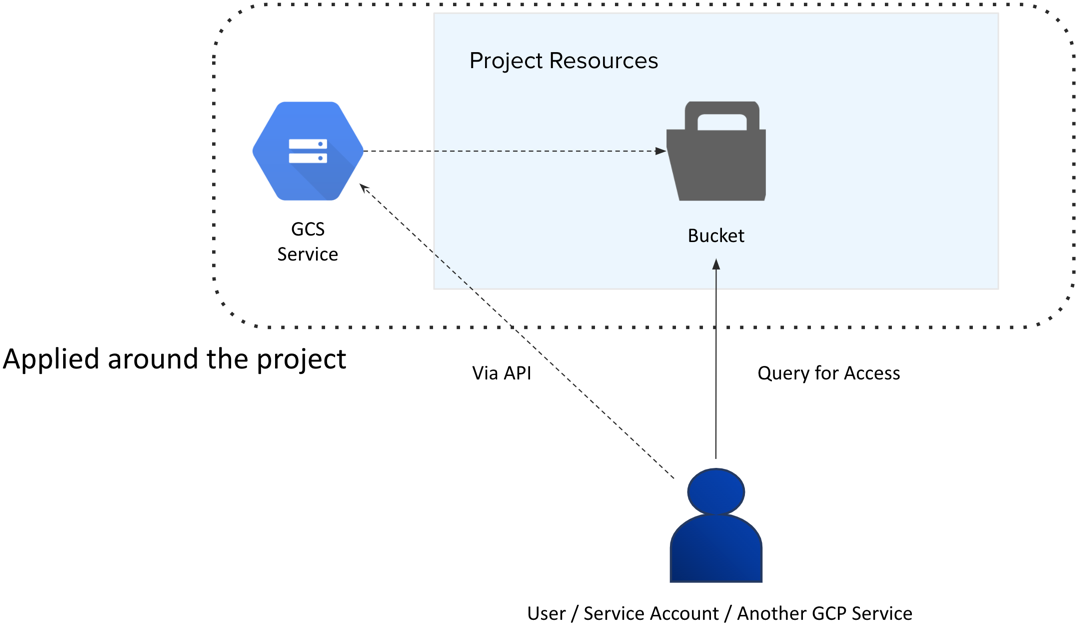
Figure: Shared VPC perimeter
In-VPC execution
Dataprep by Trifacta can be configured to execute a variety of reading and transformation jobs using resources within your VPC.
Note
This feature may not be available in all product editions. For more information on available features, see Compare Editions.
For more information, see Dataprep In-VPC Execution.
Security Features
The following security features can be deployed to Dataprep by Trifacta.
VPC Security Controls
Dataprep by Trifacta can be configured to work within your VPC-SC perimeter.
Note
If you have deployed a VPC-SC perimeter, some aspects of Dataprep by Trifacta may appear to be broken until the perimeter can be properly configured to support the product.
For more information, see Configure VPC-SC Perimeter.
Customer-Managed Encryption Keys
If your enterprise maintains sets of encryption keys, these keys can be deployed for use by the Trifacta Application to access data.
Note
This feature may not be available in all product editions. For more information on available features, see Compare Editions.
For more information, see Dataflow Pipeline State CMEK.