
関数
関数は、式エディタでさまざまな計算や演算を実行する式を作成するために使用されます。 参照: 式エディタ。
関数のタイプ
データのタイプによって、使用できる関数が決まります。 参照: データ型。
条件付き関数は、IF文を使用してデータのテストに基づいてアクションまたは計算を実行します。 条件付き関数を使用して、特定の条件に基づいてデータを強調表示またはフィルタリングするTRUEまたはFALSEの結果を提供します。 条件付き関数は、任意のデータ型で使用できます。
テストを書き込む前に各条件付き関数を考慮してください。 一部の条件付き関数は、特定の使用ケースに適しています。
c の場合、t 他の f ENDIF: 条件し、真の他の偽 ENDIF
[クラス] = = 1 その後、"金" 他の "他の" ENDIF
| クラス | 結果 |
|---|---|
| 1 | 金 |
| 2 | その他 |
| 1 | 金 |
| 3 | その他 |
c の場合、t ELSEIF c2 その後 t2 他の f ENDIF: 条件し、真の ELSEIF condition2 その後 true2 他の偽 ENDIF
複数のELSEIF文を含めることができます。
[クラス] = = 1 その後、"金" ELSEIF [クラス] = = 2 その後、"銀" 他の "他の" ENDIF
| クラス | 結果 |
|---|---|
| 1 | 金 |
| 2 | 銀 |
| 1 | 金 |
| 3 | その他 |
IIF (bool, x, y): ([bool] が true の場合) return (x)、else は (y) を返します。
IIF ([お客様]、[チラシ送信]、[ドキュメントの送信])
[顧客]フィールドの値がTRUEの場合は、Send flyerが返されます。
[顧客]フィールドの値がFALSEの場合は、Send documentationが返されます。
スイッチ (値、デフォルト、Case1、Result1,..., CaseN、ResultN): ケースのリストに対して値を比較し、対応する結果を返します。
スイッチ ([クラス]、ヌル ()、"金"、1、"銀"、2、"ブロンズ"、3、"スズ"、4、"アルミニウム"、5)
| 結果 | クラス |
|---|---|
| 5 | アルミニウム |
| 2 | 銀 |
| 1 | 金 |
| 3 | 青銅 |
| 4 | 錫 |
| 2 | 銀 |
| 1 | 金 |
| Null | その他 |
変換関数は、1つのデータ型または形式を別のデータ型または形式に変換します。 数値を文字列に、または文字列を数値に変換するには、変換関数を使用します。 変換関数は、文字列データ型と数値データ型で使用できます。
BinToInts (秒): バイナリ文字列 s を整数に変換します。 (53ビットに制限されています。)
BinToInts (101010101)の結果 341
CharFromInt (x): 入力番号に一致する Unicode ®文字を返します。
CharFromInt (66) b を返します (U + 0042 ' ラテン大文字 b ')
CharFromInt (169)返品© (U + 00A9 ' 著作権記号 ')
CharFromInt (1071) はЯを返します (U + 042F ' キリル文字の大文字屋 ')
CharFromInt (127944)を返します (U + 1F3C8 ' アメリカンフットボール ')
(U + 1F3C8 ' アメリカンフットボール ')
文字を表すために使用できない整数が null 結果を与える可能性があるため、CharFromInt (0) は [null] (U + 000 ' null ') を返します。
CharFromInt (55300) は、現在文字を表さない整数が通常のフォントでレンダリングされないため、[null] を返します。
CharToInt: 入力 Unicode ®文字に一致する数値を返します。
CharFromInt (b) は66 を返します (U + 0042 ' ラテン大文字 b ')
CharFromInt (©) 169 を返します (U + 00A9 ' 著作権記号 ')
CharFromInt (Я) は1071 を返します (U + 042F ' キリル文字の大文字屋 ')
CharFromInt ()を返します 127944 (U + 1F3C8 ' アメリカンフットボール ')
ConvertFromCodepage: コードページから Unicode にテキストを変換します。 参照: コードページ。
ConvertToCodepage (s, コードページ): Unicode ®エンコーディングのテキストを特定のコードに変換します。 参照: コードページ。
HexToNumber (x):16 進数の文字列を数値に変換します。 (53ビットに制限されています。)
HexToNumber (dd)は、数値221に変換します。
IntToBin (x): x をバイナリ文字列に変換します。
IntToHex (x): x を16進数文字列に変換します。
ToNumber (x, bIgnoreErrors, keepNulls, decimalSeparator): 文字列パラメータを数値に変換します。 ToNumberは、科学的表記倍精度として解釈できる文字列を受け入れます。 デフォルトでは、ピリオドが小数点記号として使用されます。
bIgnoreErrors: 0 または false (既定) レポート変換エラーメッセージ; 1 または true は変換エラーを無視します。
keepNulls: 0 または false (既定値) は、非数値 (null を含む) を0に変換します。1または true は、数値以外の値を null に変換します。
decimalSeparator: "."(既定値) は、ピリオドを小数点区切り記号として指定します。"," は、コンマを小数点区切り記号として指定します。
ToNumber ("878")は、文字列878を数値として返します。
ToNumber ("4.256411411 e9")は、文字列4256411411を数値として返します。
ToNumber ("number"、"false") は変換エラーで0を返します: ToNumber: 数値は変換中に失われた情報です。
ToNumber ("number", 0, 0) は変換エラーで0を返します: ToNumber: 数値は変換中に失われた情報です。
ToNumber ("Number", 1, 0) は、変換エラーなしで0を返します。
ToNumber ("Number", 1, 1) は[Null] を返し、変換エラーは発生しません。
ToNumber ("123456, 789", 1, 1, ",")は、数値として123456.789 を返します。
ToNumber ("123.456, 789", 1, 1, ",")は、数値として123を返します。 (これは、変換が桁区切り記号で停止するためです。これはToNumber関数での入力には有効ではありません。)
ToString (x, numDec, addThousandsSeparator, decimalSeparator): 数値パラメータをnumDec小数点以下の桁数で文字列に変換します。 デフォルトでは、ピリオドが小数点記号として使用されます。
addThousandsSeparator: 0 (既定値) 桁区切り記号なしの数値文字列を書式設定します。 既定では、"," が decimalSeparator に指定されている場合を除き、桁区切り記号はコンマで、その場合はピリオドになります。
decimalSeparator: "."(既定値) は、ピリオドを小数点区切り記号として指定します。"," は、コンマを小数点区切り記号として指定します。
ToString (10, 0)は、文字列として10を返します。
ToString (10.4, 2)は、文字列として10.40 を返します。
ToString (100.4, 2)は100.40 を文字列として返します。
ToString (1000.4, 2, 1)は、文字列として1000.40 を返します。
ToString (123456.789, 3, 1, ",")は、123.456、789を文字列として返します。
ToString (123456.789, 3, 0, ",")は、文字列として123456789を返します。
DateTime 関数は、日付と時刻の値に対してアクションまたは計算を実行します。 datetime 関数を使用して、間隔を追加または減算したり、現在の日付を検索したり、月の最初または最後の日を検索したり、datetime 値のコンポーネントを抽出したり、値を別の形式に変換したりします。
日付サポート
Designer 1400年1月1日より前の日付を処理できません。
AlteryxはISO形式yyyy-mm-dd HH:MM:SSを使用して日付と時刻を表します。 DateTime 値がこの形式でない場合、Alteryx は文字列として読み取ります。 DateTime 形式で使用および操作用の列を変換するには、式エディタで DateTimeParse 関数を使用するか、 日時ツール。
DateTime 関数の中には、日付の形式を設定する必要があるものがあります。 形式文字列は、指定子と区切り文字で構成されます。
指定子は常にパーセント記号(%)で始まり、大文字と小文字が区別されます。 データには少なくとも2桁の数字を含める必要があります 年。
| 指定子 | DateTimeFormatからの出力 | DateTimeParseでサポートされる入力 |
|---|---|---|
| %a | 短縮された曜日名( "Mon") | 所定のテキストが曜日でない場合にのみエラーを生成する曜日の有効な省略形("mon"、"Tues"、"Thur")。 Alteryxは、指定された曜日名が特定の日付に対して有効であることを確認しません。 |
| %A | 完全な曜日名("Monday") | 所定のテキストが曜日でない場合にのみエラーを生成する曜日名または曜日の有効な省略形("mon"、"Tues"、"Thur")。 Alteryxは、指定された曜日名が特定の日付に対して有効であることを確認しません。 |
| %b | 短縮月名("Sep") | 所定のテキストが月の名前でない場合にのみエラーを生成する月名の有効な省略形("Sep"、"SEPT.")。 |
| %B | 完全な月名("September") | 所定のテキストが月の名前でない場合にのみエラーを生成する月名または月名の有効な省略形("Sep"、"SEPT.")。 |
| %c | コンピュータのロケールの日付と時刻 | サポートされていません |
| %C | 世紀番号("20") | サポートされていません |
| %d | 月の日("01") | スペースを無視して1桁または2桁("1" または "01") |
| %D | %m/%d/%yと同等です | サポートされていません |
| %e | 月の日、先頭に0をスペースで置き換えます ("1") | スペースを無視して1桁または2桁("1" または "01") |
| %h | %bと同じです("Sep") | 所定のテキストが月の名前でない場合にのみエラーを生成する月名の有効な省略形("Sep"、"SEPT.")。 |
| %H | 24時間制での時、00~23 | 時は2桁まで、0~23。 % pまたは% p と互換性がありません。 |
| %I
(資本 "目") |
12時間制での時、01~12 | 時は2桁まで、1~12。 % pまたは% p に従う必要があります。 |
| %j | 年の日、001~365(またはうるう年では366) | 年の3桁の日、001~365(またはうるう年では366) |
| %k | 24時間、先頭の0はスペース、" 0" から "23" | 時は2桁まで |
| %l
(小文字の「エル」) |
12時間、先頭の1はスペース、" 0" から "12" | サポートされていません |
| %M | 分、00~59 | 分は2桁まで |
| %m | 月の数、01~12 | 1桁または2桁の月の数、1または01~12 |
| %p | "AM" または "PM" | 大文字と小文字を区別しない( "aM" または "Pm")。 % I (資本 "目"、12時間形式の時間) に従う必要があります |
| %P | "am" または "pm" | 大文字と小文字を区別しない( "aM" または "Pm")。 % I (資本 "目"、12時間形式の時間) に従う必要があります |
| %S | 秒、00~59 | 秒は2桁まで |
| %T | 24時間表記の時刻。 % メートルに相当します: % S | サポートされていません |
| %u | 10進数での曜日、1~7、月曜日は1 | サポートされていません |
| %U | これは、00~53として週の数を週の始まりを日曜日として返します。 | サポートされていません |
| %w | 数での曜日、0~6、月曜日は0 | サポートされていません |
| %W | これは、00~53として週の数を週の始まりを月曜日として返します。 | サポートされていません |
| %x | コンピュータのロケールの日付 | サポートされていません |
| %X | AMまたはPMを含む12時間制での時刻(“11:51:02 AM”) | 時:分:秒 [AM / PM] |
| %y | 年の最後の2桁("16") | 最大4桁が読み取られ、区切り記号または文字列の末尾で停止し、現在の年から66の範囲にマップされます。 (たとえば、2016では、1950 ~ 2049 です)。 |
| %Y | 年のすべての4桁("2016") | 2桁または4桁の数字が読み込まれます。 2桁は現在の年から現在の年を引いた66の範囲にプラス33にマップされます。 (たとえば、2016では、1950 ~ 2049 です)。 |
| %Z | UTC時刻からのオフセット("-600") | サポートされていません |
| %Z | フルタイムゾーン名("Mountain Daylight Time") | サポートされていません |
区切り記号は DateTime 指定子の間に挿入され、書式指定文字列を形成します。
| 区切り文字 | DateTimeFormatからの出力 | DateTimeParseでサポートされる入力* |
|---|---|---|
| / | / | /または - |
| - | - | /または - |
| スペース | スペース | 任意の一連の空白類文字 |
| %n | 改行 | サポートされていません |
| %t | タブ | サポートされていません |
| その他 | コンマ、ピリオド、コロンなどのその他の文字 | コンマ、ピリオド、コロンなどのその他の文字 |
* DateTimeParse は、スラッシュ ( / ) とハイフン ( - ) を同じ意味で受け入れます。 ただし、カンマ、コロン、およびその他の区切り記号はすべて、着信データと厳密に一致する必要があります。
DateTimeAdd (dt, i, u): DateTime 値に特定の間隔を追加します。
dt: 選択された列または引用符の間の指定された datetime 値として表される datetime データ。
i: 加算または減算する時間の正または負の整数。
u: 年、月、日、時、分、または秒の間で指定された DateTime 単位。
DateTimeAdd (DateTimeToday (),-1, "days")は、昨日の日付を返します。
DateTimeAdd (DateTimeFirstOfMonth (), 1, "月")は翌月の最初の値を返します。
DateTimeAdd ("2016-01-30", 1, "month") は、 2016-02-29 を返します (2 月は30を持っていないため、その最後の日は、その年は29です)
DateTimeAdd ("2016-03-30",-1, "month") は、2016-02-29 を返します (2 月は30を持っていないため、その最後の日は、その年は29です)
- 期間内の任意の端数が切り捨てられます。 例えば、"1.5時間" を追加することはできません。 代わりに、"90分" を追加します。
- 単位を追加しても、より小さい単位の値は変更されません。 例えば、時間を追加しても分または秒の値は変更されません。 結果の月にそのような日付がない場合を除いて、月の追加は日付または時刻を変更しません。 その場合はその月の最終日に行きます。
DateTimeDay (dt): DateTime 値の月の日付の数値を返します。
dt: 選択された列または引用符の間の指定された datetime 値として表される datetime データ。
DateTimeDay ("2017-03-24 11:43:23")は24を返します。
DateTimeDiff (dt1、dt2、u): 最初から2番目の引数を減算し、整数の差として返します。 期間は、指定された時間単位で文字列ではなく、数値として返されます。
DateTimeDiff (「2016-02-15 00:00:00」、「2016-01-15 00:00:01」、「月」) は1 を返します (開始と終了は月の同じ曜日なので) 。
DateTimeDiff (「2012-02-29」、「2011-03-01」、「年」)は0を返します (2012-02-29 は2011-03-01 後365日であるにもかかわらず、2月29日は3月1日前なので、「1年」はまだ完了していません)
DateTimeDiff (「2016-02-14」、「2016-01-15」、「月」) は0 を返します (2 月の日は1月の日よりも少ないので) 。
DateTimeDiff (「2016-02-14 23:59:59」、「2016-01-15 00:00:00」、「ヶ月」)は0を返します (必須の日に達するのは1秒の短いものですが) 。
DateTimeDiff (' 2017-02-28 ', ' 2016-02-29 ', ' ヶ月 ') は11 を返します (28 日が2017で2月の最終日であるにもかかわらず、28は29未満)
- 月と年の差については、終了日が開始日に達した時点でのみ1つの月がカウントされ、1日の時刻は無視されます。
- 日、時、分、および秒の精度については、結果は正確に計算され、小数部分は四捨五入されずに切り捨てられます。 従って:
- 精度の名前は、最初の3文字 (' sec ' や ' min ' など) に短縮できます。ケースは鈍感です。
- 時間差を秒単位で保存する場合は注意してください。 Int32は、秒での68年、または分での4082年の差のみを保持できます。 ダブルまたはInt64を使用して、サポートされるすべての日付の間の間隔を保持できます。
DateTimeDiff (' 2016-01-01 00:59:59 ', ' 2016-01-01 00:00:00 ', ' 時間 ')はゼロです。
DateTimeDiff (' 2016-01-01 23:59:59 ', ' 2016-01-01 00:00:00 ', ' Days ')はゼロです。
DateTimeFirstOfMonth (): 月の最初の日を、真夜中に返します。
DateTimeFormat (dt, f): DateTime データを ISO 形式から a に変換します。 別のアプリケーションで使用するための形式。 文字列データ型に出力します。
dt: 選択された列または引用符の間の指定された datetime 値として表される datetime データ。
f: フォーマット文字列で表されるデータを変換する形式。
DateTimeFormat ([DateTime_Out]、"% d-% m-% Y")は、日付の22-04-2008 を返します4月22日 2008 (ISO 形式: 2008-04-22)
DateTimeHour (dt): 時刻の時間部分を DateTime 値で返します。
dt: 選択された列または引用符の間の指定された datetime 値として表される datetime データ。
DateTimeHour ("2017-03-24 11:43:23")は11を返します。
DateTimeHour ("2017-03-24") は、時刻が日付で指定されていない場合、0を返します。
DateTimeLastOfMonth (): 現在の月の最終日を返し、時計を1秒前に設定します (23:59:59)。
Designer 数式が最初に解析された日付と時刻を使用します。 バッチプロセスでは、この時刻は新しいデータセットごとに使用されます。 これにより、処理に時間がかかる場合に一貫性を可能にします。
DateTimeMinutes (dt): 時刻の分の部分を DateTime 値で返します。
dt: 選択された列または引用符の間の指定された datetime 値として表される datetime データ。
DateTimeMinutes ("2017-03-24 11:43:23")は43を返します。
DateTimeMonth (dt): DateTime 値の月の数値を返します。
dt: 選択された列または引用符の間の指定された datetime 値として表される datetime データ。
DateTimeMonth ("2017-03-24 11:43:23")は3を返します。
DateTimeMonth ("11:43:23") は、受信データが無効であるため、[Null] を返します。
DateTimeNow (): 現在のシステムの日付と時刻を返します。
DateTimeParse (dt, f): 指定された形式の日付文字列を標準の ISO 形式の yyyy-mm-dd HH: mm: SS に変換します。
dt: 選択されたフィールドまたは引用符の間の datetime 文字列として表される datetime 文字列データ。 受信データは文字列データ型である必要があり、この形式がfパラメーター に指定した形式に一致する限り、DateTime の任意の形式にすることができます。
f: 変換するデータの形式を、引用符の間の書式文字列で表したものです。
DateTimeParse ("2016/28-03"、"% Y/% d-% m") は2016-03-28 を返します。
DateTimeSeconds (dt): 時刻の秒の部分を DateTime 値で返します。
dt: 選択された列または引用符の間の指定された datetime 値として表される datetime データ。
DateTimeSeconds ("2017-03-24 11:43:23")は23を返します。
DateTimeStart (): 現在のワークフローが実行を開始した日付と時刻を返します。
予想される動作: DateTimeToday データ型
その名前にもかかわらず、DateTimeToday () は時刻値を返しません; むしろ、現在の日付を持つ日付だけを返します。 ToDateTime () 関数で DateTimeToday () 関数をラップして、 時刻を現在の日付の真夜中に設定した DateTime 値を返す ことができます。
ToDateTime (DateTimeToday)DateTimeToLocal (dt): UTC DateTime をローカルシステムタイムゾーンに変換します。
dt: 選択された列または引用符の間の指定された datetime 値として表される datetime データ。
DateTimeToLocal (' 2014-08-01 20:01:25 ')は、ローカルシステムのタイムゾーン (山岳時間) を 2014-08-01 14:01:25 として返します。
DateTimeToUTC (dt): DateTime (ローカルシステムタイムゾーン内) を UTC に変換します。
dt: 選択された列または引用符の間の指定された datetime 値として表される datetime データ。
DateTimeToUTC (DateTimeNow ())は、ワークフローランタイムで世界協定時刻を返します: 2014-08-01 20:01:25 (ローカル山岳時間は 2014-08-01 14:01:25 でした)
DateTimeTrim (dt, t): datetime の不要な部分を削除し、変更された datetime を返します。
dt: 選択された列または引用符の間の指定された datetime 値として表される datetime データ。
t: トリムタイプ。 オプションには以下が含まれます:
- firstofmonth: 月の初めまで整える(これは月と同じです)
- lastofmonth: 月の最後の日の終了1秒前に延長する
- 年: 1月1日の真夜中にトリムします。
- 月: 月の最初の日の真夜中にトリムします
- 日: その日(つまり、真夜中)にトリムします。 これは、日付時刻を0の時刻(日付ではない)の日に変換します。
- 時間: 時にトリムします
- 分: 分にトリムします
DateTime をトリミングしても、戻り値は丸めません。 たとえば、時間 15:59:59 は、時間にトリミング15:00:00 ではなく、16:00:00 になります。
DateTimeTrim ("2016-12-07 16:03:00", "year") 2016-01-01 00:00:00 を返します。
DateTimeYear (dt): DateTime 値の年の数値を返します。
dt: 選択された列または引用符の間の指定された datetime 値として表される datetime データ。
DateTimeYear ("2017-03-24 11:43:23")は2017を返します。
外舘 (x): 文字列、数値、または DateTime を日付に変換します。
ToDateTime (x): 文字列、数値、または日付を DateTime に変換します。
ファイル関数は、ファイルパスを構築し、ファイルが存在するかどうかを確認したり、ファイルパスの一部を抽出したりします。 ファイル関数は、文字列データ型でのみ使用できます。
FileAddPaths (Path1, Path2): 2 つのパスの間に正確に1つの \ (バックスラッシュ) があることを確認して、ファイルパスの部分を二つ追加します。
FileAddPaths ([C:\Temp]、[Data\file.csv]) は、 "C:\Temp\Data\file.csv" を返します
FileExists (Path): ファイルが存在する場合は true を返します。
FileExists (C:\Temp) が「真」を返す
FileExists (C:\Temp\Data\file.csv) が「真」を返す
FileExists (C:\Temp\Data\NoFile.csv) は"False" を返します
FileGetDir (パス): パスのディレクトリ部分を返します。
FileGetDir (C:\Temp\Data\file.csv)がC:\Temp\Data を返す
FileGetDir (C:\Temp\Data)がC:\Temp を返す
FileGetExt (path): を含むパスの拡張子を返します。 。
FileGetExt (C:\Temp\Data\file.csv)が ".csv" を返します。
FileGetExt (C:\Temp\Data)を返します ""
FileGetFileName (path): 拡張子を付けずにパスの名前部分を返します。
FileGetName (C:\Temp\Data\file.csv) は"ファイル" を返します
FileGetName (C:\Temp\Data) が"データ" を返す
ファイナンス関数は、金融アルゴリズムまたは数学的計算を適用します。
FinanceCAGR (BeginningValue、EndingValue、NumYears): 年間成長率: 年率換算での幾何平均成長率
FinanceEffectiveRate (NominalRate、PaymentsPerYear): 実効年間利率: 利率として名目金利からのローンまたは金融商品の金利は、延滞で支払われる年間複利利息
FinanceFV (レート、NumPayments、PaymentAmount、プレースフォルダ、PayAtPeriodBegin): 投資の将来価値: 一定の金利または収益率を想定して、将来の特定の時間における資産の価値。
FinanceFVSchedule (原則、Year1Rate、Year2Rate): 将来価値のスケジュール: 投資に一連の金利を適用した後、最初のプリンシパルの将来の価値。
FinanceIRR (Value1、Value2): 内部利益率: 投資の費用が投資の利点に導く利率。 これは、投資から得られるすべての利益は金銭の時間価値に固有であり、投資にはこの金利でゼロの正味現在価値があることを意味します。
FinanceMIRR (FinanceRate、ReinvestRate、Value1、Value2): 変更された内部収益率: IRR に関するいくつかの問題を解決することを目的とした内部収益率の修正。 MIRRは、投資の魅力の財務的指標です。
FinanceMXIRR (FinanceRate、ReinvestRate、Value1、Date1、Value2、Date2): 日付による投資の内部収益率の変更
FinanceNominalRate (EffectiveRate、PaymentsPerYear): 名目年間利率: 複利の頻度 (月など) が基本時間単位 (通常は年) と同一でない場合、金利は名目と呼ばれます。
FinanceNPER (レート、PaymentAmount、プレースフォルダ、FutureValue、PayAtPeriodBegin): 投資または貸付期間の数
FinanceNPV (利率、Value1、Value2): 投資の正味現在価値: キャッシュフローの超過または不足を、現在の値の条件で、一度融資費用が満たされていることを測定します。
FinancePMT (レート、NumPayments、プレースフォルダ、FutureValue、PayAtPeriodBegin): ローンの支払いを計算します。
FinancePV (レート、NumPayments、PaymentAmount、FutureValue、PayAtPeriodBegin): 投資の現在価値: 将来の支払いの特定の日付または将来の支払いの一連の値は、お金の時間の値を反映するように割引やその他の要因など投資リスク。
FinanceRate (NumPayments、PaymentAmount、プレースフォルダ、FutureValue、PayAtPeriodBegin): 利率 (期間ごと) を返します。
数学関数は数学的計算を実行します。 数学関数は数値データ型でのみ使用できます。
ABS (x): (x) の絶対値を指定します。 0から数値までの距離です。 値は常に正です。
ABS (32) 32 を返します。
ABS (-32) は32 を返します。
数値のアークコサインまたは逆コサインを返します。 アークコサインは、コサインが(x)である角度です。 返される角度は、0(ゼロ)からπの範囲のラジアンで与えられます。 数(x)は-1と1の間でなければなりません。
aco (0.5) は1.047198 を返します。
数値のアークサインまたは逆サインを返します。 アークサインは、サインが(x)である角度です。 返される角度は、-π/2からπ/2の範囲のラジアンで与えられます。
ASIN (0.5) 0.523599 を返します。
数値のアークタンジェントまたは逆タンジェントを返します。 アークタンジェントは、タンジェントが(x)である角度です。 返される角度は、-π/2からπ/2の範囲のラジアンで与えられます。
ATAN(0.8)は0.674741を返します
yとxのアークタンジェントを返します。
ATAN2(4, -3)は2.2143を返します
平均 (20, 30, 55) は、 [(20 + 30 + 55)/3] = 35 から35を返します。
CEIL (x): (x) 以上の最小の整数を返します。 ExcelのRoundUp関数のように機能します。
CEIL (1.1)を返します 2
CEIL (6.54) 7 を返します。
CEIL (-30.42)を返します-30
距離 (from_Lat、from_Lon、to_Lat、to_Lon): (lat1、Lon1) から (lat2、lon2) までの距離を返します。
距離 (42,-90, 43,-80)は、513.473706 マイルの値を返します。
床 (1.1) 1 を返します。
床 (6.54) 6 を返します。
床 (-30.42)を返します-31
LOG (1) は0 を返します。
ログ (14) 2.639057 を返します。
LOG10 (1) は0 を返します。
LOG10 (14) 1.146128 を返します。
中央値 (...): 1 つ以上の (おそらくソートされていない) 値のメジアンを計算します。
中央値 (5, 4, 3, 7, 6) は5 を返します
Mod (n, d): d で割った n の剰余 (整数演算)
剰余演算は、1つの整数 (n) の剰余を除数整数 (d) で割った値を検索します。 (n)が正の場合、結果は正です。 (n)が負の場合、結果は負です。
decimal 値が使用されている場合、decimal は切り捨てられます。 除数が1未満の10進数の場合は、"0 で割った" エラーが発生することがあります。
国防省 (6, 4) 2 を返します
モッズ (6,-4) は2 を返します
国防省 (-6、4)を返します-2
国防省 (-6、-4)を返します-2
MOD (6, 4) は、 [Null] を返します
PI () は3.141593 を返します。
捕虜 (x, e): (x) を返します (e) 力に上げられます
捕虜 (2, 3)は 2 3 に相当し、8を返します 。
RAND ()は0.256 のような乱数を返します。
RandInt (n): 0 から指定されたパラメータまでのランダムな整数を返します。
RandInt (10) 0、1、2、3、4、5、6、7、8、9または10を返します。
RandInt (5000)は、0 ~ 5000 の間のランダムな整数 (741など) を返します。
ラウンド (x, mult): (mult) の最も近い倍数に丸められた (x) を返します。
ラウンド (55.34、2)は56の値を返します。
ラウンド (39.88、10)は40の値を返します。
ラウンド (41.1、10) 40 の値を返します。
ラウンド (1.25, 0.1)は、1.3 の値を返します。
ラウンド (1.227、0.01) 1.23 の値を返します。
SmartRound (x): (x)のサイズに基づいて動的に決定される値の最も近い倍数に丸められた(x) を返します。
SQRT (100)値10を返します。
ビット単位関数は、個々のビットのレベルで1つ以上のビットパターンまたは2進数で動作します。 ビット単位関数を使用して、比較や計算のための値を操作します。 ビット単位関数は数値データ型でのみ使用できます。
BinaryAnd (n, m): n と m のバイナリを返します。 nとmの両方が1の場合は1、それ以外の場合は0になります。 0が false と同一視され、1が true の場合、BinaryAnd 操作は論理 and のように動作します。
BinaryAnd (1, 1)を返します 1
BinaryAnd (1, 0) は0 を返します。
BinaryNot (n): n ではないバイナリを返します。
BinaryNot (6)を返します-7
BinaryNot (2) が-3 を返す
BinaryOr (n, m): バイナリまたは n と m の値を返します。
BinaryOr (6、6) が6 を返す
BinaryOr (6、2) が6 を返す
BinaryXOr (n, m): n と m のバイナリ XOr を返します。
BinaryXOr (6, 6) 0 を返します。
BinaryXOr (6、2) が4 を返す
最小値または最大値関数は、一連の値の最小値と最大値を検出します。 Min/Max関数は数値データ型でのみ使用できます。
バインド (x、min、max): (x < min)="" return="" min;="" else="" if="" (x=""> max) が max を返す場合は、他の x を返します。
バウンド (6, 1, 5) は5 を返す
バウンド (3, 1, 5) は3 を返す
Max (v0、v1,..., vn): リストから最大値を返します。
Max (15180、7、13、45、2、13) は180 を返します。
MaxIDX (v0、v1,..., vn): リストから最大値の0から始まるインデックスを返します。
MaxIDX (15180、7、13、45、2、13) 1 を返します。
Min (v0、v1,..., vn): リストから最小値を返します。
Min (15180、7、13、45、2、13) は2 を返します。
MinIDX (v0、v1,..., vn): リストから最小値の0から始まるインデックスを返します。
MinIDX (15180、7、13、45、2、13) 5 を返します。
演算子は、アクションを表す文字です。 算術演算子を使用して数学的計算を実行するか、ブール演算子を使用してtrue/false値で動作させます。 演算子は、すべてのデータ型で使用できます。
/* コメント */: ブロックコメント: 式に干渉することなく式エディタ (式の行の中) にコメントを追加することができます。
コメント: 単一行コメント: 式を妨げることなく、式エディタにコメントを追加できます。
ブール型および & &: ブール値と: 2 つのブール型を結合するために使用します。 結果もブール値です。 結合された値の両方がtrueである場合、結果はtrueであり、結合された値のいずれかがfalseの場合、結果はfalseです。
ブール型と-キーワード: ブール値と: 2 つのブール型を結合するために使用します。 結果もブール値です。 結合された値の両方がtrueである場合、結果はtrueであり、結合された値のいずれかがfalseの場合、結果はfalseです。
ブールではない!: ブール型ではありません: 1 つの入力を受け入れます。 その入力がTRUEの場合、FALSEを返します。 その入力がFALSEの場合、TRUEを返します。
ブール型ではない-キーワード: ブールではない: 1 つの入力を受け入れます。 その入力がTRUEの場合、FALSEを返します。 その入力がFALSEの場合、TRUEを返します。
ブール型または-キーワード: boolean または: チェックする2つの値のいずれか (または両方) が true の場合、true を返します。
ブール値または | |: Boolean または: チェックする2つの値のいずれか (または両方) が true の場合、true を返します。
値 (...)-キーワード: リスト内のテスト値: 指定された値がサブクエリまたはリスト内の任意の値と一致するかどうかを判断します。
値が not (...)-キーワード: テスト値がリストにありません: 指定された値がサブクエリまたはリストにない値と一致するかどうかを判断します。
空間関数は、空間オブジェクトを構築し、空間データを分析し、空間フィールドからメトリックを返します。 空間関数は空間データ型でのみ使用できます。
空間機能は、オープン GIS コンソーシアム株式会社と一致している。 詳細については、http://portal.opengeospatial.org/files/?artifact_id=829 を参照してください。
式の空間オブジェクトは演算子を使用できます: プラス +;マイナス-;等しい = =;等しくない! =
ST_Area (オブジェクト、単位): 空間オブジェクトの指定された単位の領域を返します。 (数値データ値)
ST_Boundary (オブジェクト): 空間オブジェクトの境界を返します。 (入力ポリゴンの境界を示すポリライン空間オブジェクト)
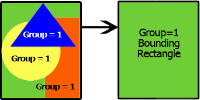
ST_BoundingRectangle (オブジェクト、...): 空間オブジェクトの外接する四角形を返します。 (ポリゴン空間オブジェクト)
ST_Centroid (オブジェクト): 空間オブジェクトの重心を返します。 (ポイント空間オブジェクト)
ST_CentroidX (オブジェクト): 空間オブジェクトの重心の経度を返します (数値データ値)。
ST_CentroidY (オブジェクト): 空間オブジェクトの重心の緯度を返します (数値データ値)
ST_Combine (object1、object2,...): 空間オブジェクトを結合します。 (空間オブジェクト)
ST_Contains (object1、object2): object1 に object2 が含まれている場合は True を返します。 (ブール値)
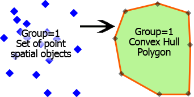
ST_ConvexHull (object1,...): オブジェクトの凸包を返します。 (空間オブジェクト)
ST_CreateLine (point1、ポイント...): 指定されたポイントとラインをシーケンス内で接続して、線分を作成します。 (空間オブジェクト)
ST_CreatePoint (x, y): 指定された経度と緯度の座標を含む空間オブジェクトを返します。 (空間オブジェクト)
ST_CreatePolygon (obj1、obj2...): 指定した点と線分をシーケンスに接続してポリゴンを作成します。 (空間オブジェクト)
ST_Cut (object1、object2): オブジェクト2から object1 を切断した結果を返します。 (空間オブジェクト)
ST_Dimension (オブジェクト): 空間オブジェクトの次元を返します。 空間ディメンジョンは、空間オブジェクトを構成するすべてのポイントを指定するために必要な座標の最小数です。 Point オブジェクトは値0を返し、Line オブジェクトは値1を返し、ポリゴンオブジェクトは値2を返します。 (数値データ値)
ST_Distance (object1、object2、単位): object1 から object2 までの指定された単位の距離を返します。 サポートされている単位はマイル (Mi)、キロメートル (km)、m、フィートです。 (数値データ値)
ST_EndPoint (オブジェクト): 空間オブジェクトの最後の点を返します。 (ポイント空間オブジェクト)
ST_Intersection (object1、object2,...): 指定した空間オブジェクトの交点を返します。 (空間オブジェクト)
ST_Intersects (object1、object2...): 空間オブジェクトが交差する場合は True を返します。 (ブール値)
ST_InverseIntersection (object1、object2...): 指定した空間オブジェクトの逆交点を返します。 (空間オブジェクト)
ST_Length (オブジェクト、単位): 空間オブジェクトの直線の長さを返します。 (数値データ値)
ST_MaxX (オブジェクト): 空間オブジェクトの最大経度を返します。 (数値データ値)
ST_MaxY (オブジェクト): 空間オブジェクトの最大緯度を返します。 (数値データ値)
ST_MinX (オブジェクト): 空間オブジェクトの最小経度を返します。 (数値データ値)
ST_MinY (オブジェクト): 空間オブジェクトの最小緯度を返します。 (数値データ値)
ST_NumParts (オブジェクト): 空間オブジェクト内の部品の数を返します。 (数値データ値)
ST_NumPoints (オブジェクト): 空間オブジェクト内のポイント数を返します。 (数値データ値)
ST_ObjectType (オブジェクト): 空間オブジェクト型を文字列値として返します。 (文字列データ値)
ST_PointN (オブジェクト、n): 空間オブジェクトの n 番目の点を返します。 (ポイント空間オブジェクト)
ST_RandomPoint (オブジェクト): 空間オブジェクト内のランダムな点を返します。 (ポイント空間オブジェクト)
ST_Relate (object1、object2、リレーション): オブジェクトが提供された DE 9IM 関係を満たす場合は True を返します。 (ブール値)
ST_StartPoint (オブジェクト): 空間オブジェクトの最初の点を返します。 (空間オブジェクト)
ST_Touches (object1、object2): オブジェクト1がオブジェクト2に接触した場合に True を返します。 (ブール値)
ST_TouchesOrIntersects (object1、object2): オブジェクト1がオブジェクト2に触れたり、交差している場合に True を返します。 (ブール値)
ST_Within (object1、object2): オブジェクト1がオブジェクト2に含まれている場合は True を返します。 (ブール値)
これらの関数は、さまざまな特殊なアクションを実行し、すべてのデータ型で使用できます。
EscapeXMLMetacharacters (文字列): XML メタキャラクタをエスケープしたバージョンに置き換えます。 エスケープされる5つの文字があります。
| 文字 | エスケープされたバージョン |
|---|---|
| " | " |
| ' | ' |
| < | < |
| > | > |
| & | & |
EscapeXMLMetacharacters ("2 > 1 & 1を返します 2 > 1 と 1 < 2
GetVal (インデックス、v0,... vn): 0 から始まる [index] で指定された値 (v0,..., vn) を返します。
GetEnvironmentVariable (名前): name で指定された環境変数を返します。 環境変数のリストを取得するには、コントロールパネル > システム > 高度なシステム設定 > 環境変数の順に進みます。 システム変数のリストが表示されます。 これからの任意の値を使用できます。
ギャラリーサポート
GetEnvironmentVariableは、Galleryに保存されたアプではサポートされていません。
GetEnvironmentVariable (CommonProgramFiles) は、 c:\\ プログラムの共通ファイルを返します
GetEnvironmentVariable (OS) がWindows_NT を返します。
メッセージ (messageType、message、returnValue): 条件ステートメントと共に使用して、メッセージログにメッセージを出力し、状態が満たされたときに指定された値で列データを更新します。
メッセージタイプとテキストが結果ウィンドウに表示されます。 ロギングが有効な場合、出力ログファイルもこの情報に似ています。 参照: 結果ウィンドウ および CSVファイルを出力する。
messageType: メッセージの種類に対応する番号。
- 1 = メッセージ
- 2 = 警告
- 3 = エラー
- 5 = 変換エラー(フィールド変換エラー)
- 8 = ファイル(入力)
- 9 = ファイル(出力)
メッセージ: 引用符の間の文字列として表されるメッセージのテキスト。
returnValue: 列データに出力する値。 これは数値(例えば、0)、Null、引用符の間のテキスト文字列(例えば、"False")です。
この例では、条件式内でメッセージ関数を使用してフィールド変換エラーメッセージを出力し、所定の日付/時刻値に有効な時刻データが含まれていない場合は列データを "False" の値で更新します。
[時間] = "0" と [分] = "0" の場合、
メッセージ (5、"DateTime では無効な時刻"、"False")
Else
"True"
Endif
RangeMedian (...): 一連の集計範囲から中央値を計算します。 参照: 範囲の平均。
ReadRegistryString (キー、ValueName、設定値 = "): レジストリから取得します。
ReadRegistryString (' HKEY_LOCAL_MACHINE\SOFTWARE\Wow6432Node\SRC\Alteryx '、' InstallDir64 ') は、 c:\\ プログラムの Files\Alteryx\bin を返します
Soundex (文字列): 文字列の Soundex を返します。 Soundexは、文字列の最初の文字に基づいたコードに加えて、以下に基づいた3つの文字を作成します。
| 文字 | Soundex |
|---|---|
| アルファベット以外の文字(数字と句読点) | -1 |
| A e, i, o, u, y, h, w | ない限り無視 文字列の最初の文字 |
| B f、p、v | 1 |
| C g, j, k, q, s, x, z | 2 |
| d と t | 3 |
| l | 4 |
| m と n | 5 |
| R | 6 |
結果のコードが2または3文字長のみの場合、Soundexは0を使用してコードを4文字で記入します。 たとえば、Laurenという名前では、L、r、およびnのみが変換され(Lrn)、結果のSoundexコードはL650になります。結果のコードが4文字長を超える場合、4文字目以降の文字はすべて無視されます。 たとえば、パトリックという名前では、P、t、r、c、および k は変換 (Ptrck) できますが、結果として得られる Soundex コードは、P362 の4文字になります。
Soundex_Digits (文字列): 最初の4桁または Soundex を返します。 文字列に数字(数値)がある場合、最初の4桁が返されます。 数字がない場合、Soundexコードが返されます。
| 文字列 | Soundex_Digits |
|---|---|
| 3825 アイリス | 3825 |
| 55555 メイン | 5555 |
| 14L ブロードウェイ | 14 |
| 商業 ストリート | C562 |
| L ストリート | L236 |
TOPNIDX (N, v0, v1,..., vn): リストの最大値から n 番目の0から始まるインデックスを返します。 N==0の場合、MaxIdx(...) と同じです。
Nは開始点、v0はインデックスフィールド (後続の変数は省略可能) で、vnが目標です。
TOPNIDX (0, [IndexedField], 5)ストリームの上位5つを返します。
UrlEncode (文字列): web 法的 URL として文字列をエンコードします。
C:\temp\Alteryx url エンコードはC を返します:/temp/Alteryx% 2 0 url% 2 0 エンコード
文字列関数は、テキストデータに対して操作を実行します。 文字列関数を使用してデータをクレンジングしたり、データを別の形式または大文字に変換したり、データに関するメトリックを計算したり、他の操作を実行したりできます。 文字列関数は、文字列データ型でのみ使用できます。
(文字列、ターゲット、CaseInsensitive = 1) が含まれています: 文字列内の特定の文字列の出現を検索します。 文字列がパターンと一致する場合はTRUEまたはFALSEを返します。 大文字小文字を区別しないようにデフォルト設定されています。
CONTAINS関数は大文字と小文字を区別しませんが、FINDSTRING関数は大文字と小文字を区別します。
が含まれています (' 123ABC ', ' ABC ') TRUE を返します。
が含まれています (' 123ABC ', ' abc ') TRUE を返します。
が含まれています (' 123ABC '、' abc '、0) はFALSE を返します。
CountWords (文字列): 指定した文字列の単語数を返します。 単語はスペースで区切られた文字で定義されます。
CountWords (「基本的な変数の世帯」) は3 を返す
CountWords (「基本的な変数年齢: 女性 (破裂音) 年齢1」) は5 を返す
DecomposeUnicodeForMatch (文字列): アクセントを削除し、狭に変換しながら複合文字を展開します。 この関数は Unicode ®文字列を受け取ります。 小文字、狭い文字列に変換します。 すべてのアクセントやその他の装飾は削除されます。
この関数はマッチングのみに役立ちます。 正規化された文字列とは見なされません。
DecomposeUnicodeForMatch ("Prénoms フランセ") prenoms フランセを返します。
EndsWith (文字列、ターゲット、CaseInsensitive = 1): 文字列が特定の文字列で終わるかどうかを調べます。 文字列がパターンと一致する場合はTRUEまたはFALSEを返します。 大文字小文字を区別しないようにデフォルト設定されています。
EndsWith (' 123ABC '、' ABC ') はTRUE を返します。
EndsWith (' 123ABC '、' abc ') はTRUE を返します。
EndsWith (' 123ABC ', ' abc ', 0) はFALSE を返します。
EndsWith関数は大文字と小文字を区別しませんが、FindString関数は大文字と小文字を区別します。
FindString (文字列、ターゲット): 別の文字列 (string) 内の特定の文字列 (ターゲット) の出現を検索し、文字列内の出現位置の数値を返します。
文字列のターゲットの最初の出現の0ベースのインデックスを返します。 出現がない場合は-1を返します。
FindString ([Name]、"john") は、文字列に john が含まれている場合は0を返し、文字列がない場合は-1 を返します。
場合 (FINDSTRING ([名前]、"john") = 0) その後、"ジョンスミス" 他の "他の" ENDIFは、文字列が john を含むときに、文字列がないときに他を返すジョンスミスを返します。
GetWord (文字列、n): 文字列内の n 番目 (0 から始まる) の単語を返します。 単語はスペースで区切られた文字の集合として定義されます。 0ベースのインデックスとは、最初の単語が0の位置にあることを意味します。
GetWord (「基本変数の世帯」、0) は「基本」を返す
GetWord (「基本変数世帯」、1) は「変数」を返す
左 (x, len): 文字列 (x) の最初の [len] 文字を返します。 lenが0より小さいかxの長さより大きい場合、xは変更されないままです。
左 ("92688", 3) "926" の値を返します。
長さ (x) : 文字列 (x) の長さを返します。
長さ ("92688")は5の値を返します。
小文字 (x): 文字列から小文字への変換
小文字 ("M1P 1G6") は"M1P 1G6" を返します。
MD5_ASCII (文字列): 文字列の MD5 ハッシュを計算します。 文字列はASCII文字のみであることが予測されています。 Unicode ®文字は有効になっていますか?MD5 ハッシュを計算する前に。
MD5_UNICODE (文字列): 文字列の MD5 ハッシュを計算します。
PadLeft (str, len, char): 指定された文字を左に指定した長さに文字列を埋め込みます。 パディング "char" が2文字以上の長さの場合、最初の文字のみが使用されます。
PadLeft ("M", 4, "x") は"xxxM" を返します
PadRight (str, len, char): 指定された文字を使用して、指定した長さの文字列を右側に埋め込みます。 パディング "char" が2文字以上の長さの場合、最初の文字のみが使用されます。
PadRight ("M", 4, "x") は"Mxxx" を返します
REGEX_CountMatches (文字列、パターン、icase): 文字列内の一致の数をパターンに返します。
icaseはオプションのパラメータです。 指定されると、大文字と小文字は一致する必要があります デフォルトのicase=1は大文字小文字の無視を意味します。 0に設定すると、大文字と小文字が一致する必要があります。
式の作成を簡単にするには、「正規表現の構文をブーストする」ページを参照してください。
REGEX_Match (文字列、パターン、icase): 正規表現の出現を文字列で検索します。
文字列が最初の文字から最後までのパターンと一致するかどうかを示します。 文字列の先頭から必ずしも始まらないものを探すには、パターンを '.*' で始めます。 文字列の最後まで必ずしも行くとは限らないものを探すには、パターンを '.*' で終わらせます。
正規表現を適切に構築する方法の詳細については、「正規表現をブーストする」を参照してください。
icaseは省略可能なパラメータです。 指定されると、大文字と小文字は一致する必要があります デフォルトのicase=1は大文字小文字の無視を意味します。 0に設定すると、大文字と小文字が一致する必要があります。
REGEX_Match (123-45-6789, "\d{3}-\d{2}-\d{4}") -1 を返します (True)
REGEX_Replace (文字列、パターン、置換、icase): 正規表現を使用したテキストの置換を許可し、RegEx 検索パターンと置換文字列から得られた文字列を返します。 最初の一致だけでなく、一致のすべての出現が置き換えられます。
式の作成を簡単にするには、「正規表現の構文をブーストする」ページを参照してください。 置換パラメータは、以下に示すような指定された値、または "$ 1" などのマークされたグループのいずれかです
icaseは省略可能なパラメータです。 指定されると、大文字と小文字は一致する必要があります デフォルトのicase=1は大文字小文字の無視を意味します。 0に設定すると、大文字と小文字が一致する必要があります。
REGEX_Replace (「あなたの社会保障番号を明らかにしてはいけない、123-45-6789」、「\d{3}-\d{2}-\d{4}」、「分類される」)リターンはあなたの社会保障番号を明らかにしない、分類される
REGEX_Replace ("すべてのドメイン名を alteryx@Alteryx.com から変更する"、"@. * \."、"@extendthereach")alteryx@extendthereach.com からすべてのドメイン名を変更します。
置換 (str、ターゲット、置換): 文字列 (ターゲット) の各オカレンスを文字列 (置換) に置き換えた後に文字列 (str) を返します。
交換 ("良い判断は経験から来る"、"経験"、"意識")を返します "良い判断は、意識から来る"
ReplaceChar (x, y, z): 文字 (y) の出現箇所を文字 (z) で置換した後、文字列 (x) を返します。 置換文字(z)が複数の文字を含む文字列である場合、最初の文字のみが使用されます。 (z)が空の場合、(y)の任意の文字と一致する各文字(x)は単に削除されます。
ReplaceChar ("abcdefb"、"b"、"_") は"a_cdef_" を返します
ReplaceChar ("@ a # b% c", "@, #,%", "_") は"_a_b_c" を返します
ReplaceFirst (str、ターゲット、置換): 文字列 (ターゲット) の最初のオカレンスを文字列 (置換) で置換した後、文字列 (str) を返します。
ReplaceFirst ("abcdefb"、"b"、"_") は"a_cdefb" を返します
ReverseString (Str): 文字列内のすべての文字を反転します。
ReverseString ("abcdefb") は"bfedcba" を返します
Right (文字列、len): 文字列の最後の (len) 文字を返します。 lenが0より小さいか文字列の長さより大きい場合、文字列は変更されないままです。
Right ("92688", 3)は値 "688" を返します。
StartsWith (文字列、ターゲット、CaseInsensitive = 1): 文字列が特定の文字列で始まるかどうかを調べます。 文字列がパターンと一致する場合はTRUEまたはFALSEを返します。 大文字小文字を区別しないようにデフォルト設定されています。
StartsWith関数は大文字と小文字を区別しませんが、FindString関数は大文字と小文字を区別します。
StartsWith (' ABC123 '、' ABC ') はTRUE を返します。
StartsWith (' ABC123 '、' abc ') はTRUE を返します。
StartsWith (' ABC123 ', ' abc ', 0) はFALSE を返します。
STRCSPN (x, y): 文字列 (y) にない文字で構成される文字列 (x) の初期セグメントの長さを返します。
STRCSPN ("ボブの Amaco"、"~! @ # $% ^ & * ' ()") は3 を返します。 これは、文字列に句読点がないことを確認するのに便利なテストです。
StripQuotes (x): 一致した一連の引用符またはアポストロフィを文字列の両端から削除します。
StripQuotes ("こんにちは")がハローを返します
StripQuotes (「こんにちは、彼女は言った」)を返します ' こんにちは、' 彼女は言った。
StripQuotes (' "こんにちは、" 彼女は言った。を返します "こんにちは、" 彼女は言った。
STRSPN (x, y): 文字列 [y] の文字で構成される文字列 [x] の初期セグメントの長さを返します。
STRSPN ("3034408896x105"、"0123456789") は10 を返します。 これは、文字列が一連の文字で構成されていることを確認するのに便利なテストです。
サブストリング (x、start、length): (開始) から始まる (x) の部分文字列を返し、指定された場合は (長さ) の後に停止します。
部分文字列 ("949-222-4356", 4, 8) "222-4356" を返します。
部分文字列 ("949-222-4356", 4, 6) "222-43" を返します。
部分文字列 ("949-222-4356", 4) "222-4356" を返します。
タイトル (x) : 文字列をタイトルケースに変換します。
タイトル ("ジョンスミス")を返します "ジョンスミス"
トリム (x, y): 文字列 x の両端から文字列 y の文字を削除します。 Yはオプションで、デフォルトでは空白類をトリミングします。 TRIM関数の例では、指定された文字がトリミングされることに注意してください。 文字の順序は関係ありません。
トリム ("! 指示を参照してください!!!", "!")「指示を参照」を返します。
トリム ("Test123") は"Test123" を返します。
TrimLeft (x, y): 文字列 x の先頭から文字列 y の文字を削除します。 Yはオプションで、デフォルトでは空白類を切り取ります
TrimLeft (「* * 特別招待」、「*」) は「特別招待」を返します。
TrimRight (x, y): 文字列 x の末尾から文字列 y の文字を削除します。 Yはオプションで、デフォルトでは空白類を切り取ります
TrimRight ("ジョンスミス")を返します "ジョンスミス"
TrimRight ("ジョン·スミス * *"、"*") は、 "ジョン·スミス" を返します
トリムする文字の文字列を渡すことがありますが、トリム関数は文字の順序を尊重しません。文字列を "list" として扱います。したがって、リスト内のすべての文字がトリムされます。 文字列を置換する場合は、式で置換関数または正規表現関数を使用します。
文字列をすべて大文字に変換します。
長さと文字列について: 文字列の長さを参照する場合、最初の文字は1としてカウントされます (次の文字列の長さ "record" は 6)。
しかし、文字列内の文字位置を参照するとき、位置は実際には文字間でカウントされます。 最初の文字の位置を0と考えてください。 従って、文字列 "record" 内の文字 "c" の位置は、位置2にあります。
大文字 ("ジョンスミス")を返します "ジョンスミス"
UuidCreate (): 一意の識別子を作成します。
UuidCreate ()は ba131836-1ba3-4d42-8f7e-b81a99c2e838 などの一意の値を返します。
テスト機能は、データの検証テストを実行します。 テスト関数を使用して、値のデータ型を識別したり、値が存在するかどうかを判断したりします。 テスト関数は、すべてのデータ型で使用できます。
CompareDictionary (a, b): 辞書順で2つの文字列を比較します。 <b, 0="" if="" a="=b," 1="" if="" a="">b</b,>の場合は-1 を返します。
CompareDictionary (りんご、バナナ)を返します-1
CompareDictionary (チェリー、バナナ) 1 を返します。
CompareDictionary (バナナ、バナナ) 0 を返します。
CompareDigits (a, b, nNumDigits): 2 つの数値を比較し、指定した桁数と同じかどうかを判断します。 この比較では、差の先頭桁がNumDigits以上の桁AとBの大きい方の先頭桁の右にある場合、数字とレポートAとBの差については同じと判断します。
NumDigits引数はNullであってはならず、1から19の間でなければなりません。そうでない場合は、エラーが発生します。 整数でない場合は、最も近い整数に四捨五入されます。 (NumDigitsは0.5~19.499の間にすることができます)
CompareDigits (12345、12444、3) は、 "True" を返します (差は99で、その先頭の桁は A の先頭桁の右に3つの場所です)
CompareDigits (12345、123445、3) は、 "False" を返します (差が100であるため、その先頭の桁は A の先頭の桁の右にある2つの場所にすぎません)
CompareDigits (12.345、12.347、3)を返します "True" (違いは0.002 であるため、その先頭の桁は、A の先頭の桁の右側に4つの場所です)
CompareDigits (12.345、12.435、3) は、 "True" を返します (差は0.09 で、その先頭の桁は A の先頭桁の右に3つの場所です)
CompareDigits (91234,. 91334, 3) は、 "False" を返します (差が .001 であるため、その先頭の桁は A の先頭の桁の右側にわずか2か所)
CompareEpsilon (a, b, イプシロン): 2 つの浮動小数点数を比較し、その値がイプシロン内にある場合は true を返します。
CompareEpsilon ([123.456789101112]、[123.456789101114]、0.0001) は"True" を返します
CompareEpsilon ([123.456]、[123.456789101112]、0.0001) は"False" を返します
IsEmpty (v): v が NULL または等しいかどうかをテストします。
| 名前 | IsEmpty |
|---|---|
| John | False |
| True | |
| Mary | False |
| [Null] | True |
IsInteger (v) : v に整数に変換できる値が含まれているかどうかをテストします。 そうであれば、Trueを返します。
| 値 | IsInteger |
|---|---|
| 1 | True |
| 1.23 | False |
| B | False |
IsNull (v) : v が NULL かどうかをテストします。
レコードにNULL値を入力するには、関数NULL()を使用します
| 名前 | IsNull |
|---|---|
| John | False |
| [Null] | True |
| Mary | False |
IsNumber (v) : v のフィールド型が数値であるかどうかをテストします。
IsSpatialObj (v): v のフィールド型が空間オブジェクトであるかどうかをテストします。
IsString (v): v のフィールド型が文字列であるかどうかをテストします。