根据用于输入或输出数据的文件格式或数据库连接,配置选项会有所不同。在以下工具中选择文件格式选项:输入数据工具、输出数据工具、库内连接工具、数据流传入工具、库内写入数据工具。
选项 | 描述 | 文件格式 |
|---|---|---|
允许提取大于 >2 GB 的文件 | .zip、*.gz、*.tgz | |
允许分享写入权限 | 选择此选项以读取可能正在更新的打开文件。此选项用于读取 Web 日志。 | |
附加到现有表格 | 选择此选项以将记录附加到现有表格。 | .dbase、.sdf |
附加字段映射 | 选择此选项以附加字段并设置输出字段如何映射到 OleDB 表格中的字段。 | .mdb、.xls、.accdb、ODBC、OLEDB |
代码页 | 选择用于转换输入或输出数据中的文本的代码页。请参阅代码页。 | .csv、.dbf、.flat、.json、.mid、.mif、.tab、.shp |
将Int32字段创建为二进制字段 | 选择此选项以将所有 Int32 字段创建为数据库中的 32 位(4 字节)二进制值,而不是默认的 11 字符文本格式。并非所有 DBF 读取器都支持此选项。 | .dbase |
分隔符 | 选择数据中的字段分隔符。 使用 \0 读取或写入没有分隔符的文本文件。如果数据包含两个或更多分隔符,请使用 0 强制 Designer 将数据读取为纯文本。 在“令牌化”模式下使用正则表达式工具来解析数据。 | .csv、.txt |
描述或数据文件 | 定义用作布局文件的 .flat 文件的文件名。 | .flat |
不显示完成百分比 (%) | 选择此选项以禁用文件读入进度的状态报告;这将加快读取时间。 | |
启用压缩(Deflate) | 选择此选项以输出经压缩的 .avro 文件。 使用 deflate 算法(类似于 gzip),并且应该得到其他支持 Avro 的工具(例如 Hive)的支持。压缩会增加输出时间,但对于较大的文件,会减少网络时间。 | .avro |
启用 SQL Server FileTables 支持 | 选择此选项以将 Excel 文件写入 Microsoft SQL Server FileTable | .xlsx |
扩展值标签 | 读取值标签(键)并将其应用于数据。对于 SPSS 和 SAS 文件,默认选择此选项。请参阅 Stat Transfer 支持的文件格式。 如果未选择,则仅显示值键。 | .spss、.sas |
字段长度 | 定义输入数据中的最大字段长度。 | |
文件格式 | 选择数据文件格式。 | 所有格式 |
存档的文件 | 更改要输入的文件(或多个文件)。请参阅 Zip 文件支持。 | .zip |
第一行包含数据 | 选择是否应将第一行视为数据而非标题。 | .xlsx |
第一行包含字段名称 | 选择是否应将第一行视为标题。 | .csv |
强制 SQL WChar 支持 | 选择此选项允许将字符列作为 SQL_WCHAR、SQL_WVARCHAR 或 SQL_WLONGVARCHAR 进行处理。 | .oci、unicode.txt |
如果允许长行 | 使用选定的 .flat 文件(默认),或覆盖设置。 | .flat |
如果允许短行 | 使用选定的 .flat 文件(默认),或覆盖设置。 | .flat |
忽略以下分隔符 | 选择一个选项: 引号:忽略引号中的分隔符。 单引号:忽略单引号中的分隔符。 自动:忽略自动检测到的分隔符。 无:不忽略分隔符。 | |
忽略XML错误并继续 | 忽略不正确的 XML 格式并继续运行工作流。请参阅读取 XML。 | .xml |
行末尾样式 | 定义表示文本行末尾的字符或字符序列。 | .csv、.flat |
文件的最大记录数 | 定义要输出到单个文件的记录数。如果数据包含更多记录,则会按顺序创建并命名多个文件。 | 所有格式 |
无空间索引 | 选择以关闭空间索引。 仅当写入不会用于空间运算的大型临时文件时,才使用此选项。此选项可以更快地写入较小的文件。 | .yxdb |
将所有字段输出为字符串 | 选择此选项以将传入字段转换为字符串数据类型;如果 .dbf 文件中的数据类型错误,这将绕过转换错误。 | .dbf |
将文件名输出为字段 | 选择此选项以将具有文件名或文件路径的字段附加到每条记录。 | |
输出选项 | 选择输出选项: 创建新工作表:创建新工作表,但不覆盖现有工作表。 附加到现有工作表:将数据附加到现有工作表,使输出由新数据和以前的数据组成。 覆盖工作表或范围:删除所选工作表或范围中的数据,并将数据写入具有所选名称的工作表或范围。 如果您的 Excel 文件包含公式、表格、图表和图像,请勿使用上述选项,因为这些项目可能会损坏。 覆盖文件(移除):删除现有文件并创建新文件。 | .xlsx、.xlsm(通过 Alteryx .xlsx 驱动程序) |
输出选项 | 选择输出选项: 创建新表格:创建新表格,但不覆盖现有表格。 附加现有:将数据附加到现有表格,使输出由旧记录和新记录组成。 删除数据再附加:删除表格中的所有原始记录,然后将数据附加到现有表格。 覆盖表格 (Drop):删除现有表格并创建新表格。 | .accdb、.mdb、.tde、.xls、.xlsx(通过旧版 .xlsx 驱动程序)、.oci、OLEDB、ODBC |
输出选项 | 选择一个选项: 更新,在失败时发出警告:使用输出来更新现有记录,并在记录无法更新时发出警告。 更新,在失败时出错:使用输出来更新现有记录,如果无法更新记录,则停止处理。 更新,若有新记录则插入:使用输出来更新现有记录,如果新记录不在数据库表格中,则插入新记录;如果无法更新记录,则停止处理。 需要包含主键字段才能成功更新。 如果有多个记录具有相同主键,并且没有发生其他 SQL 错误,则新记录将更新数据库中的旧记录。在写入数据库之前,请使用唯一值工具检查是否有多个主键。 | .oci、OLEDB、ODBC |
覆盖现有表格 | 默认选择此选项覆盖同名的现有文件类型。 | .mdb* |
将所选文件解析为 | 更改解析文件的格式。 | .zip |
将值解析为字符串 | 选择此选项以将输出数据解析为字符串;如果未选择,则根据数据类型解析数据。 | |
密码 | 选择密码在“配置”窗口中的显示方式:隐藏(默认值)、为计算机加密、为用户加密。 | |
后创建 SQL* 语句 | 定义一条 SQL 语句,以便在创建输出表格之后通过 ODBC/OLEDB 驱动程序执行。 | .mdb、.mdb*、.oci、.accdb、ODBC、OLEDB |
预创建 SQL* 语句 | 定义一条 SQL 语句,以便在创建输出表格之前通过 ODBC/OLEDB 驱动程序执行。 | .mdb、.mdb*、.oci、.accdb、ODBC、OLEDB |
覆盖时保留格式(需要提供范围) | 保留您要覆盖的范围的 Excel 格式。 如果您的 Excel 文件包含公式、表格、图表和图像,请勿使用此选项,因为这些项目可能会损坏。 选择此选项时,还必须:
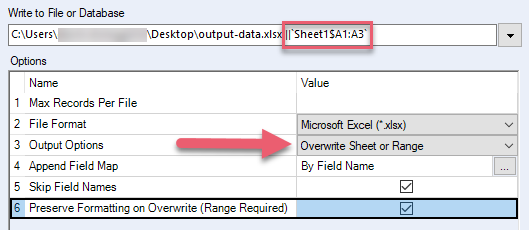 | .xlsx、.xlsm(通过 Alteryx .xlsx 驱动程序) |
投影 | 定义输出投影。默认情况下,投影为空白并输出到 WGS 84。请参阅投影支持。 | .mid、.mif、.tab、.shp、.oci、.mdb |
引用输出字段 | 选择用于引用输出字段的选项: 自动:在具有单引号或双引号的字段以及包含分隔符的字段周围插入引号。 始终:在每个字段周围插入引号。 从不:不插入引号。 | |
将空间对象读取为形心 | 对于含有多边形对象的数据,选择此选项以使用多边形的形心作为空间对象。 | .mdb*、.tab、.oci、.sdf、.shp、.geo、.kml、.mid、.mif |
记录限制 | 选择此选项以限制从输入数据中读取的记录。如果为 0,则返回所有记录。如果为 -1,则仅返回元数据。 | |
返回子值 | 默认选择此选项以输出根元素的子值或指定的 XML 子元素名称。请参阅读取 XML。 | .xml |
返回外部 XML | 选择此选项以输出指定 XML 子元素名称的 XML 标记格式。取消选择此选项以输出根元素的子元素格式。请参阅读取 XML。 | .xml |
返回根元素 | 选择此选项以输出包含所有其他元素的父元素。请参阅读取 XML。 | .xml |
在工具配置上运行 PreSQL | 默认选择此选项以在工具被引入工作流时运行 preSQL 语句。 取消选中此复选框以在执行工作流时运行 preSQL 语句。 | |
保存源和描述 | 默认选择此选项以在元信息中包括源和描述数据。取消选择此选项以排除源和描述数据。 | |
搜索子目录 | 如果数据文件位于子目录中并且包含相同的结构、字段名称、长度和数据类型,则使用此选项来引入多个输入。 | |
批量加载数据块大小(1MB至102400MB) | 要写入的批量加载数据块的大小。默认设置为 128 MB。 | |
跳过字段名称 | 选中此选项后,您只能在一个工作表或一个范围中写入数据。 | .xlsx、.xlsm |
空间对象字段 | 定义要包含在输出中的空间对象。空间文件的每条记录只能包含一个空间对象。 Alteryx 不支持在单个文件中读取或写入多种几何类型。 | .mdb*、.tab、.oci、.sdf、.shp、.geo、.kml、.mid、.mif |
显示事务消息 | 选择此选项以在“结果”窗口中显示每个事务的消息。每条消息都会报告写入该事务的记录总数。 | |
数据导入起始行 | 定义开始读取数据的行号。默认情况下,它从第 1 行开始。 | .csv、.xlsx |
支持Null值 | 选择此选项以输出含有 Null 值的 .avro 文件。 此输出选项将字段与一个 Null 分支和一个值分支合并。如果 Alteryx 值为 Null,则输出将使用 Null 分支;否则,使用值分支。 如果未选择此选项,则所有输出字段都将按其原生 .avro 类型(非合并)写入。Alteryx 字段为 Null 时将被写入其默认值。 使用公式工具通过“已知”值来处理 Null 值,这样这些值就可以在 Hadoop 中读取。 | .avro |
表格类型 | 使用此选项来选择系统默认、列或行表格存储。 表格存储表示数据的存储方式。系统默认使用基础数据库的表格存储。 与创建行存储表相比,创建列存储表格时您会注意到性能有所下降。 | SAP HANA ODBC |
表格/字段名称 SQL 样式 | 选择带引号或无。“带引号”使用数据库类型的带引号的标识符。 | .oci、OLEDB、OBDC、 |
表格或查询 | 如果数据包含多个表格,则定义要输入的表格,或者选择创建查询。请参阅选择表格或指定查询窗口。 | |
从字段获取文件名 | 选择一个选项,为特定字段的每个值写入单独的文件: 作为后缀附加到文件/表格名称:将所选字段名称附加到表格名称的末尾。 作为前缀附加到文件/表格名称:将所选字段名称附加到表格名称的开头。 更改文件名:将文件名更改为所选字段名称。 更改整个文件路径:将文件名更改为包含完整路径的所选字段名称。 | 所有输出格式 |
事务大小 | 定义一次写入数据库的记录数。 记录以小于 655360 字节或事务大小 * 记录大小的批次提交。记录大小是根据工作流输出中指定的字段大小计算的。如果记录大小大于 655360 字节,则事务大小自动设置为 1。对于更新,事务大小始终为 1。 默认情况下,事务大小为 0,表示所有记录。将记录设置为至少 1000 条,因为数据库会为每个事务创建一个临时日志文件,这可能会很快填满临时空间。 | .oci、OLEDB、ODBC |
将错误作为警告处理 | 选择此选项以输入记录不符合数据结构的数据。通常错误会导致输入失败;此选项通过将错误视为警告来防止输入失败。 | |
裁剪空白处 | 使用选定的 .flat 文件(默认),或覆盖设置。 | .flat |
使用何种行尾 | 使用选定的 .flat 文件(默认),或覆盖设置。 | .flat |
写入BOM | 选择此选项以在输出中包括字节顺序标记 (BOM),或取消选择此选项以在输出中不包括字节顺序标记。 | .csv |