En fonction du format de fichier ou de la connexion à la base de données utilisée pour l’entrée ou la sortie de données, les options de configuration varient. Sélectionnez les options de format de fichier dans les outils suivants : Outil Entrée de données , Outil Sortie de données , Outil Connecter en BDD , Outil Entrée du flux de données , Outil Écrire des données en BDD .
Option | Description | Formats de fichiers |
|---|---|---|
Autoriser l'extraction des fichiers >2 Go | Sélectionnez cette option pour autoriser Alteryx à extraire un fichier dont la taille est supérieure à 2 Go. Voir Prise en charge des fichiers Zip et Prise en charge des fichiers Gzip . | .zip, *.gz, *.tgz |
Autoriser l'accès en écriture partagée | Sélectionnez cette option pour lire un fichier ouvert qui peut être en cours de mise à jour. Cette option est destinée à la lecture des journaux Web. | |
Ajouter à une table existante | Sélectionnez cette option pour ajouter des enregistrements à une table existante. | .dbase, .sdf |
Ajouter une affectation des champs | Sélectionnez cette option pour ajouter des champs et définir la façon dont les champs de sortie sont affectés aux champs de la table OleDB. | .mdb, .xls, .accdb, ODBC, OLEDB |
Page de code | Sélectionnez une page de code pour convertir du texte dans les entrées ou les sorties de données. Voir Pages de code . | .csv, .dbf, .flat, .json, .mid, .mif, .tab, .shp |
Créer les champs Int32 au format binaire | Sélectionnez cette option pour créer tous les champs Int32 en tant que valeurs binaires 32 bits (4 octets) dans la base de données, au lieu d'utiliser le format de texte de 11 caractères par défaut. Cette option n’est pas prise en charge par tous les lecteurs DBF. | .dbase |
Délimiteur | Sélectionnez le délimiteur de champs dans les données. Utilisez \0 pour lire ou écrire un fichier texte sans délimiteur. Utilisez 0 si les données comprennent au moins deux délimiteurs pour forcer Designer à lire les données comme s'il s'agissait d'un texte plat. Utilisez l' outil RegEx en mode de marquage avec un jeton pour analyser les données. | .csv, .txt |
Description ou fichier de données | Définissez le nom du fichier .flat utilisé comme fichier de mise en page. | .flat |
Ne pas afficher le % terminé | Sélectionnez cette option pour désactiver le rapport d’état Lecture du fichier en cours ; vous accélérerez ainsi le temps de lecture. | |
Activer la compression (Deflate) | Sélectionnez cette option pour générer en sortie un fichier .avro comprimé. L’algorithme deflate (similaire à gzip) est utilisé et doit être pris en charge par les autres outils compatibles Avro tels que Hive. La compression ralentit la production de sortie, mais avec des fichiers plus volumineux, le temps réseau est réduit. | .avro |
Activer la prise en charge des FileTables SQL Server | Sélectionnez cette option pour écrire un fichier Excel dans un fichier Microsoft SQL Server FileTable | .xlsx |
Développer les étiquettes de valeur | Lisez et appliquez des étiquettes de valeur (clé) aux données. Cette option est sélectionnée par défaut pour les fichiers SPSS et SAS. Voir Formats de fichiers pris en charge par Stat Transfer . Si cette option n’est pas sélectionnée, seule la clé de valeur est affichée. | .spss, .sas |
Longueur du champ | Définissez la longueur de champ maximum des données d’entrée. | |
Format de fichier | Sélectionnez le format de fichier de données. | Tous les formats |
Fichier de l'archive | Modifiez le fichier (ou les fichiers) à entrer. Voir Prise en charge des fichiers Zip . | .zip |
La première ligne contient des données | Sélectionnez cette option si la première ligne doit être traitée comme des données, et pas comme un en-tête. | .xlsx |
La première ligne contient les noms de champs | Sélectionnez cette option si la première ligne doit être traitée comme un en-tête. | .csv |
Forcer la prise en charge SQL WChar | Sélectionnez cette option pour traiter les colonnes de caractères comme un type SQL_WCHAR, SQL_WVARCHAR ou SQL_WLONGVARCHAR. | .oci, unicode.txt |
Si les lignes longues sont autorisées | Utilisez le fichier .flat sélectionné (par défaut) ou remplacez le paramètre. | .flat |
Si les lignes courtes sont autorisées | Utilisez le fichier .flat sélectionné (par défaut) ou remplacez le paramètre. | .flat |
Ignorer les délimiteurs entre | Sélectionnez une option : Guillemets : ignorer les délimiteurs entre guillemets. Guillemets simples : ignorer les délimiteurs entre guillemets simples. Auto : ignorer les délimiteurs détectés automatiquement. Aucun : ne pas ignorer les délimiteurs. | |
Ignorer les erreurs XML et continuer | Ignorez le formatage XML incorrect et continuez à exécuter le le workflow. Voir Lecture d'XML . | .xml |
Style de fin de ligne | Définissez le caractère ou la séquence de caractères indiquant la fin d’une ligne de texte. | .csv, .flat |
Enregistrements max. par fichier | Définissez le nombre d’enregistrements à envoyer dans un seul fichier. Si les données comprennent davantage d’enregistrements, plusieurs fichiers sont créés et nommés dans l’ordre séquentiel. | Tous les formats |
Pas d'index géographique | Sélectionnez cette option pour désactiver l'index géographique. Utilisez cette option uniquement lorsque vous écrivez des fichiers temporaires volumineux qui ne doivent pas être utilisés dans des opérations géographiques. Cette option écrit les fichiers de manière plus rapide tout en diminuant leur taille. | .yxdb |
Générer tous les champs en chaînes | Sélectionnez cette option pour convertir des champs entrants en type de données Chaîne ; elle ignore les erreurs de conversion si le type de données est incorrect dans les fichiers .dbf. | .dbf |
Générer un champ avec le nom du fichier | Sélectionnez cette option pour ajouter un champ contenant le nom de fichier ou le chemin de fichier de chaque enregistrement. | |
Options de sortie | Sélectionnez une option de sortie : Créer une feuille : crée une nouvelle feuille, mais ne remplace pas une feuille existante. Ajouter à la feuille existante : ajoute les données à une feuille existante de sorte que la sortie soit constituée de données antérieures et de nouvelles données. Écraser une feuille ou une plage : supprime les données de la feuille ou de la plage sélectionnée et écrit les données dans la feuille ou la plage du nom sélectionné. N'utilisez pas l'option ci-dessus si votre fichier Excel contient des formules, des tables, des graphiques et des images, car ces éléments peuvent être corrompus. Remplacer le fichier (supprimer) : supprime le fichier existant et en crée un nouveau. | .xlsx, .xlsm (via le pilote .xlsx Alteryx) |
Options de sortie | Sélectionnez une option de sortie : Créer une table : crée une nouvelle table, mais ne remplace pas une table existante. Ajout existant : ajoute les données à une table existante de sorte que la sortie soit constituée d'enregistrements avant et d'enregistrements après. Supprimer les données et ajouter : supprime tous les enregistrements d'origine de la table et ajoute les données à la table existante. Écraser la table (supprimer) : supprime définitivement la table existante et en crée une nouvelle. | .accdb, .mdb, .tde, .xls, .xlsx (via le pilote .xlsx original), .oci, OLEDB, ODBC |
Options de sortie | Sélectionnez une option : Mettre à jour, avertissement en cas d'échec : met à jour les enregistrements existants avec la sortie et signale les enregistrements n'ayant pas pu être mis à jour. Mettre à jour, erreur en cas d'échec : met à jour les enregistrements existants avec la sortie et arrête le traitement si un enregistrement n'a pas pu être mis à jour. Mettre à jour, insérer si nouveau : met à jour les enregistrements existants avec la sortie, insère de nouveaux enregistrements s'ils ne sont pas encore présents dans la table de base de données et arrête le traitement si un enregistrement n'a pas pu être mis à jour. Le champ Clé primaire doit être inclus pour que la mise à jour fonctionne. Si plusieurs enregistrements ayant la même clé primaire sont présents et qu’aucune autre erreur SQL ne se produit, le nouvel enregistrement met à jour l’ancien dans la base de données. Utilisez l' outil Unique pour vérifier plusieurs clés primaires avant l'écriture dans la base de données. | .oci, OLEDB, ODBC |
Remplacer la table existante | Sélectionnée par défaut, cette option écrase un type de fichier existant du même nom. | .mdb* |
Analyser le fichier sélectionné en tant que | Modifiez le format d’analyse du fichier. | .zip |
Analyser la valeur comme chaîne | Sélectionnez cette option pour analyser les sorties de données comme une chaîne ; si cette option n'est pas sélectionnée, les données sont analysées en fonction de leur type. | |
Mots de passe | Sélectionnez le mode d'affichage d'un mot de passe dans la fenêtre Configuration : Masquer (par défaut), Chiffrer pour l'ordinateur , Chiffrer pour l'utilisateur . | |
Post-créer l’instruction SQL* | Définissez une instruction SQL à exécuter via le pilote ODBC/OLEDB après la création de la table de sortie. | .mdb, .mdb*, .oci, .accdb, ODBC, OLEDB |
Pré-créer l’instruction SQL* | Définissez une instruction SQL à exécuter via le pilote ODBC/OLEDB avant la création de la table de sortie. | .mdb, .mdb*, .oci, .accdb, ODBC, OLEDB |
Préserver la mise en forme lors du remplacement (plage requise) | Conservez la mise en forme Excel de la plage que vous écrasez. N'utilisez pas cette option si votre fichier Excel contient des formules, des tables, des graphiques et des images, car ces éléments peuvent être corrompus. Lorsque vous sélectionnez cette option, vous devez également :
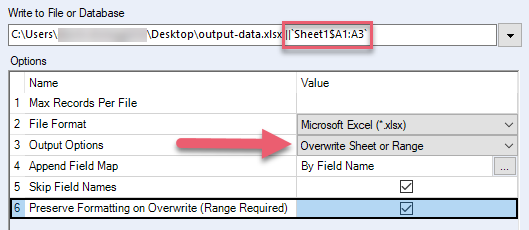 | .xlsx, .xlsm (via le pilote .xlsx Alteryx) |
Projection | Définissez le projet de sortie. Par défaut, le champ Projection est vide et génère la sortie WGS 84. Voir Prise en charge des projections . | .mid, .mif, .tab, .shp, .oci, .mdb |
Champ de sortie entre guillemets | Choisissez une option pour mettre les champs de sortie entre guillemets : Auto : insère des guillemets autour des champs qui ont un guillemet simple ou double, et autour des champs qui contiennent des délimiteurs. Toujours : met chaque champ entre guillemets. Jamais : n'insère pas de guillemets. | |
Lire les objets géographiques comme des centroïdes | Pour les données associées à des objets polygone, sélectionnez cette option pour que le centroïde du polygone serve d’objet géographique. | .mdb*, .tab, .oci, .sdf, .shp, .geo, .kml, .mid, .mif |
Limite d'enregistrements | Sélectionnez cette option pour limiter les enregistrements lus à partir des données d’entrée. Si cette option est renseignée par 0, tous les enregistrements sont renvoyés. Si cette option est renseignée par -1, seules les métadonnées sont renvoyées. | |
Renvoyer les valeurs enfants | Sélectionné par défaut pour sortir les valeurs enfant de l'élément racine ou un nom d'élément enfant XML spécifié . Voir Lecture d'XML . | .xml |
Renvoyer les codes XML externes | Sélectionnez pour sortir le format d'une balise XML d'un nom d'élément enfant XML spécifié. Désélectionnez pour sortir le format des enfants d’un élément racine. Voir Lecture d'XML . | .xml |
Retourner l'élément racine | Sélectionnez pour sortir l’élément parent qui contient tous les autres éléments. Voir Lecture d'XML . | .xml |
Exécuter PreSQL dans la configuration de l’outil | Sélectionnée par défaut, cette option exécute des instructions preSQL lorsqu'un outil est transféré dans un workflow. Décochez la case pour exécuter des instructions preSQL lorsque le workflow est exécuté à la place. | |
Enregistrer la source et la description | Sélectionnée par défaut, cette option inclut les données source et de description dans les méta-infos. Désélectionnez cette option pour exclure les données source et de description. | |
Chercher dans les sous-rép. | Cette option permet d’utiliser des entrées multiples si les fichiers de données se trouvent dans un sous-répertoire et s’ils contiennent les mêmes structures, noms de fichier, longueurs et types de données. | |
Taille des fragments de chargement en masse (de 1 Mo à 102 400 Mo) | Taille des fragments de chargement en masse à écrire. La valeur par défaut est 128 Mo. | |
Ignorer les noms de champ | Lorsque cette option est cochée, elle vous permet d'écrire des données uniquement dans une feuille ou une plage. | .xlsx, .xlsm |
Champ d'objet géographique | Définissez l'objet géographique à inclure dans la sortie. Les fichiers géographiques ne peuvent contenir qu’un seul objet géographique par enregistrement. Alteryx ne prend pas en charge la lecture ou l’écriture de plusieurs types de géométrie dans un seul fichier. | .mdb*, .tab, .oci, .sdf, .shp, .geo, .kml, .mid, .mif |
Afficher les messages de transaction | Sélectionnez cette option pour afficher un message pour chaque transaction dans la fenêtre Résultats. Chaque message indique la somme des enregistrements écrits jusqu’à cette transaction. | |
Démarrer l'importation des données sur la ligne | Définissez le numéro de ligne à partir duquel commencer la lecture des données. Par défaut, la lecture commence à la ligne 1. | .csv, .xlsx |
Prise en charge des valeurs Null | Sélectionnez cette option pour générer un fichier .avro contenant des valeurs Null. Cette option de sortie réunit des champs avec une branche Null et une branche de valeur. Si la valeur Alteryx est Null, la sortie utilise la branche null ; sinon, c’est la branche de valeur qui est utilisée. Si cette option n’est pas sélectionnée, tous les champs de sortie sont écrits dans leur type Avro natif (sans union). Les champs Alteryx nuls sont écrits avec leur valeur par défaut. Utilisez l' outil Formule pour gérer les valeurs Null avec des valeurs « connues » afin de pouvoir être lues dans Hadoop. | .avro |
Type de table | Permet de sélectionner les magasins de table par défaut, de colonnes ou de lignes du système. Les magasins de table représentent la façon dont les données sont stockées. La valeur par défaut du système respecte le magasin de table de la base de données sous-jacente. Vous remarquerez une baisse des performances lorsque vous créez une table de magasin de colonnes par rapport à une table de magasin de lignes. | ODBC SAP HANA |
Style SQL de nom de table/champ | Sélectionnez Entre guillemets ou Aucun . L’option Entre guillemets utilise l’identifiant de guillemet pour le type de base de données. | .oci, OLEDB, OBDC, |
Table ou requête | Si les données contiennent plusieurs tables, définissez la table à entrer ou cliquez pour créer une requête. Voir Fenêtre Choisir une table ou préciser la requête . | |
Prendre le nom de fichier dans le champ | Sélectionnez une option pour écrire un fichier distinct pour chaque valeur d’un champ particulier : Ajouter un suffixe au nom du fichier/de la table : ajoute le nom du champ sélectionné à la fin du nom de la table. Ajouter un préfixe au nom du fichier/de la table : ajoute le nom du champ sélectionné au début du nom de la table. Modifier le nom de fichier : remplace le nom du fichier par le nom du champ sélectionné. Modifier le chemin de fichier complet : remplace le nom du fichier par le nom du champ sélectionné contenant un chemin entier. | Tous les formats de sortie |
Taille de la transaction | Définissez le nombre d'enregistrements à écrire simultanément dans une base de données. Les enregistrements sont validés par lots inférieurs à 655 360 octets, ou taille de transaction * taille d'enregistrement. La taille d'enregistrement est calculée en fonction des tailles de champ spécifiées dans la sortie de workflow. Si la taille de l'enregistrement est supérieure à 655 360 octets, la taille de la transaction est automatiquement définie sur 1. Pour les mises à jour, la taille de la transaction est toujours de 1. La taille de transaction par défaut est égale à 0 (tous les enregistrements). Définissez une valeur minimum de 1 000 enregistrements, car la base de données crée un fichier journal temporaire pour chaque transaction, et l’espace temporaire risque d’arriver rapidement à saturation. | .oci, OLEDB, ODBC |
Traiter les erreurs comme des avertissements | Sélectionnez cette option pour entrer les données contenant des enregistrements non conformes à la structure des données. Les erreurs entraînent généralement l’échec de l’entrée ; cette option évite l’échec de l’entrée en traitant les erreurs comme des avertissements. | |
Supprimer les espaces vides | Utilisez le fichier .flat sélectionné (par défaut) ou remplacez le paramètre. | .flat |
Type de saut de ligne à utiliser | Utilisez le fichier .flat sélectionné (par défaut) ou remplacez le paramètre. | .flat |
Écrire la BOM | Sélectionnez cette option pour inclure l’indicateur d’ordre des octets (BOM) dans la sortie ou désélectionnez-la si vous voulez générer la sortie sans BOM. | .csv |