Die Konfigurationsoptionen variieren je nach Dateiformat oder Datenbankverbindung, das bzw. die Sie zum Ein- oder Ausgeben von Daten verwenden. Wählen Sie die Dateiformatoptionen in diesen Tools aus: Eingabedaten-Tool , Datenausgabe-Tool , In-DB-verbinden-Tool , Eingehender-Datenstrom-Tool , In-DB-Daten-schreiben-Tool .
Option | Beschreibung | Dateiformate |
|---|---|---|
Extrahierung von Dateien zulassen >2 GB | Wählen Sie diese Option aus, um Dateien mit einer Größe von mehr als 2 GB zu extrahieren. Siehe Unterstützung für ZIP-Dateien und Unterstützung für GZIP-Dateien . | ZIP, GZ, TGZ |
Gemeinsamen Schreibzugriff zulassen | Wählen Sie diese Option aus, um eine geöffnete Datei zu lesen, die möglicherweise gerade aktualisiert wird. Diese Option ist zum Lesen von Web-Protokollen vorgesehen. | |
Vorhandener Tabelle anfügen | Wähle Sie diese Option aus, um an eine vorhandene Tabelle Datensätze anzufügen. | DBASE, SDF |
Feldzuordnung hinzufügen | Wählen Sie diese Option aus, um Felder anzufügen und festzulegen, wie Ausgabefelder den Feldern in der OleDB-Tabelle zugeordnet werden. | MDB, XLS, ACCDB, ODBC, OLEDB |
Codepage | Wählen Sie eine Codepage zum Konvertieren von Text aus, der sich in Eingabe- oder Ausgabedaten befindet. Siehe Codepages . | CSV, DBF, FLAT, JSON, MID, MIF, TAB, SHP |
Int32-Felder binär erstellen | Wählen Sie diese Option aus, um in der Datenbank alle Int32-Felder als 32-Bit-Binärwerte (4-Byte-Binärwerte) anstelle des Standardtextformats mit 11 Zeichen zu erstellen. Diese Option ist nicht von allen DBF-Readern unterstützt. | DBASE |
Trennzeichen | Wählen Sie das Feldtrennzeichen in den Daten aus. Verwenden Sie „\0“, um eine Textdatei ohne Trennzeichen zu lesen oder zu schreiben. Verwenden Sie „0", wenn die Daten zwei oder mehr Trennzeichen enthalten, damit Designer die Daten als Flatfile-Textdatei liest. Verwenden Sie das RegEx-Tool im Tokenize-Modus, um die Daten zu parsen. | CSV, TXT |
Beschreibung oder Datendatei | Definieren Sie den Dateinamen einer als Layoutdatei verwendeten FLAT-Datei. | FLAT |
Fortschrittsbalken nicht anzeigen | Wählen Sie diese Option aus, um einen Statusbericht eines laufenden Dateilesevorgangs zu deaktivieren. Dadurch wird die Lesezeit beschleunigt. | |
Komprimierung aktivieren (Deflate) | Wählen Sie diese Option aus, um eine komprimierte AVRO-Datei auszugeben. Der Deflate-Algorithmus (ähnelt dem GZIP-Prinzip) wird verwendet und sollte von anderen Avro-fähigen Tools wie Hive unterstützt werden. Durch die Komprimierung erhöht sich die Ausgabezeit, bei größeren Dateien verringert sich jedoch die Netzwerkzeit. | AVRO |
Unterstützung für SQL Server FileTable aktivieren | Diese Option wählen, um eine Excel-Datei in eine Microsoft SQL Server Dateitabelle zu schreiben | XLSX |
Wertbeschriftungen erweitern | Lesen Sie Wertbeschriftungen (Schlüssel), und wenden Sie sie auf Daten an. Für SPSS- und SAS-Dateien ist diese Option standardmäßig ausgewählt. Siehe Stat Transfer unterstützte Dateiformate . Wenn diese Option nicht ausgewählt ist, wird nur der Wertschlüssel angezeigt. | SPSS, SAS |
Feldlänge | Definieren Sie die maximale Feldlänge in den Eingabedaten. | |
Dateiformat | Wählen Sie das Format für die Datendatei aus. | alle Formate |
Datei in Archiv | Ändern Sie die Datei (oder Dateien) für die Eingabe. Siehe Unterstützung für ZIP-Dateien . | ZIP |
Erste Zeile enthält Daten | Wählen Sie aus, ob die erste Zeile nicht als Überschrift, sondern wie Daten behandelt werden soll. | XLSX |
Erste Zeile enthält Feldnamen | Wählen Sie aus, ob die erste Zeile als Überschrift behandelt werden soll. | CSV |
Unterstützung für SQL_WCHAR erzwingen | Wählen Sie diese Option aus, um die Behandlung von Zeichenspalten als SQL_WCHAR, SQL_WVARCHAR oder SQL_WLONGVARCHAR zuzulassen. | OCI, unicode.txt |
Wenn lange Zeilen erlaubt sind | Verwenden Sie die ausgewählte FLAT-Datei (Standardeinstellung), oder überschreiben Sie die Einstellung. | FLAT |
Wenn kurze Zeilen erlaubt sind | Verwenden Sie die ausgewählte FLAT-Datei (Standardeinstellung), oder überschreiben Sie die Einstellung. | FLAT |
Trennzeichen ignorieren in | Wählen Sie eine Option aus: Anführungszeichen : Trennzeichen in Anführungszeichen ignorieren. Einfache Anführungszeichen : Trennzeichen in einfachen Anführungszeichen ignorieren. Auto : Automatisch erkannte Trennzeichen ignorieren. Keine : Trennzeichen nicht ignorieren. | |
XML-Fehler ignorieren und fortsetzen | Ignorieren Sie die falsche XML-Formatierung und führen Sie den Workflow weiter aus. Siehe XML-Code lesen . | XML |
Zeilenende-Stil | Definieren Sie das Zeichen oder die Zeichensequenz, das bzw. die das Ende einer Textzeile angibt. | CSV, FLAT |
Max. Datensätze pro Datei | Definieren Sie die Anzahl der Datensätze für die Ausgabe in einer einzelnen Datei. Wenn die Daten mehrere Datensätze enthalten, werden mehrere Dateien erstellt und fortlaufend benannt. | alle Formate |
Kein Geodaten-Index | Wählen Sie diese Option aus, um den Geodaten-Index zu deaktivieren. Verwenden Sie diese Option nur beim Schreiben umfangreicher temporärer Dateien, die nicht in Geodatenvorgängen verwendet werden. Diese Option schreibt kleinere Dateien schneller. | YXDB |
Alle Felder als Zeichenfolge ausgeben | Wählen Sie diese Option aus, um eingehende Felder in den Zeichenfolgen-Datentyp zu konvertieren. Dadurch werden Konvertierungsfehler umgangen, wenn der Datentyp in DBF-Dateien falsch ist. | DBF |
Datei als Feldname ausgeben | Wählen Sie diese Option aus, um an jeden Datensatz ein Feld mit dem Dateinamen oder Dateipfad anzuhängen. | |
Ausgabeoptionen | Wählen Sie eine Ausgabeoption aus: Neue Tabelle erstellen : Erstellt eine neue Tabelle, vorhandene Tabellen werden jedoch nicht überschrieben. An vorhandene Tabelle anhängen : Hängt Daten an eine vorhandene Tabelle an, sodass die Ausgabe neue und vorherige Daten enthält. Tabelle oder Bereich überschreiben : Löscht die Daten in der ausgewählten Tabelle oder im ausgewählten Bereich und schreibt Daten mit dem ausgewählten Namen in die Tabelle oder den Bereich. Verwenden Sie die obige Option nicht, wenn Ihre Excel-Datei Formeln, Tabellen, Diagramme und Bilder enthält, da diese Elemente beschädigt werden können. Datei überschreiben (entfernen) : Löscht die vorhandene Datei und erstellt eine neue Datei. | XLSX, XLSM (via Alteryx-XLSX-Treiber) |
Ausgabeoptionen | Wählen Sie eine Ausgabeoption aus: Neue Tabelle erstellen : Erstellt eine neue Tabelle, vorhandene Tabellen werden jedoch nicht überschrieben. Vorhandene anfügen : Fügt Daten einer vorhandenen Tabelle an, sodass die Ausgabe aus Datensätzen davor und Datensätzen danach besteht. Daten löschen und anfügen : Löscht alle ursprünglichen Datensätze aus der Tabelle und fügt Daten der vorhandenen Tabelle an. Tabelle überschreiben (verwerfen) : Verwirft die vorhandene Tabelle und erstellt eine neue Tabelle. | ACCDB, MDB, TDE, XLS, XLSX (via alten XLSX-Treiber), OCI, OLEDB, ODBC |
Ausgabeoptionen | Wählen Sie eine Option aus: Aktualisieren, Warnung bei Fehlschlagen : Aktualisiert vorhandene Datensätze mithilfe der Ausgabe und gibt eine Warnung aus, wenn ein Datensatz nicht aktualisiert werden konnte. Aktualisieren, Fehler bei Fehlschlagen : Aktualisiert vorhandene Datensätze mithilfe der Ausgabe und stoppt die Verarbeitung, wenn ein Datensatz nicht aktualisiert werden konnte. Aktualisieren, einfügen wenn neu : Aktualisiert vorhandene Datensätze mithilfe der Ausgabe und fügt neue Datensätze ein, wenn sie nicht in der Datenbanktabelle vorhanden waren und stoppt die Verarbeitung, wenn ein Datensatz nicht aktualisiert werden konnte. Das primäre Schlüsselfeld muss enthalten sein, damit die Aktualisierung funktioniert. Wenn mehrere Datensätze mit demselben primären Schlüssel vorliegen und keine weiteren SQL-Fehler auftreten, wird der ältere Datensatz in der Datenbank anhand des neuen Datensatzes aktualisiert. Mit dem Einmalig-Tool können Sie vor dem Schreiben in die Datenbank prüfen, ob mehrere primäre Schlüssel vorhanden sind. | OCI, OLEDB, ODBC |
Vorhandene Tabelle überschreiben | Diese Option ist standardmäßig ausgewählt und überschreibt einen vorhandenen Dateityp desselben Namens. | MDB |
Ausgewählte Datei analysieren als | Ändern Sie das Format, in dem die Datei analysiert werden soll. | ZIP |
Wert als Zeichenfolge analysieren | Wählen Sie diese Option aus, um Ausgabedaten als Zeichenfolge zu parsen. Wenn diese Option nicht ausgewählt ist, werden die Daten basierend auf dem Datentyp geparst. | |
Kennwörter | Wählen Sie aus, wie ein Kennwort im Konfigurationsfenster angezeigt werden soll: Ausblenden (Standard), Für Rechner verschlüsseln , Für Benutzer verschlüsseln . | |
SQL*-Anweisung nach Erstellen | Definieren Sie eine SQL-Anweisung, die über den ODBC/OLEDB-Treiber ausgeführt wird, nachdem die Ausgabetabelle erstellt wurde. | MDB, MDB*, OCI, ACCDB, ODBC, OLEDB |
SQL*-Anweisung vor Erstellen | Definieren Sie eine SQL-Anweisung, die über den ODBC/OLEDB-Treiber ausgeführt wird, bevor die Ausgabetabelle erstellt wird. | MDB, MDB*, OCI, ACCDB, ODBC, OLEDB |
Formatierung beim Überschreiben erhalten (Bereich benötigt) | Behalten Sie die Excel-Formatierung des Bereichs, der überschrieben wird, bei. Verwenden Sie diese Option nicht, wenn Ihre Excel-Datei Formeln, Tabellen, Diagramme und Bilder enthält, da diese Elemente beschädigt werden können. Wenn Sie diese Option auswählen, müssen Sie außerdem Folgendes durchführen:
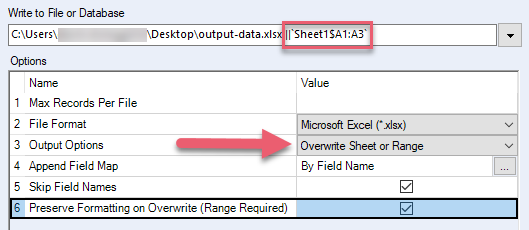 | XLSX, XLSM (via Alteryx-XLSX-Treiber) |
Projektion | Definieren Sie das Ausgabeprojekt. Standardmäßig ist die Projektion leer und wird in WGS 84 ausgegeben. Siehe Projektionsunterstützung . | MID, MIF, TAB, SHP, OCI, MDB |
Anführungszeichen für Ausgabefelder | Wählen Sie eine Option zum Einfügen von Anführungszeichen in Ausgabefelder: Auto : Fügt Anführungszeichen um Felder mit einem einfachen oder doppelten Anführungszeichen und um Felder mit Trennzeichen ein. Immer : Fügt Anführungszeichen um alle Felder ein. Nie : Fügt keine Anführungszeichen ein. | |
Geo-Objekte als Centroids lesen | Aktivieren Sie diese Option für Daten mit Polygonobjekten, um die Zentroide der Polygone als Geo-Objekte zu verwenden. | MDB*, TAB, OCI, SDF, SHP, GEO, KML, MID, MIF |
Datensatzlimit | Wählen Sie diese Option aus, um die Anzahl der Datensätze zu beschränken, die aus den Eingabedaten gelesen werden. Bei 0 werden alle Datensätze zurückgegeben. Bei -1 werden nur die Metadaten zurückgegeben. | |
Untergeordnete Werte zurückgeben | Ist standardmäßig ausgewählt, um die untergeordneten Werte des Stammelements oder eines angegebenen Namens des untergeordneten XML-Elements auszugeben. Siehe XML-Code lesen . | XML |
Äußeres XML zurückgeben | Wählen Sie diese Option aus, um das Format des XML-Tags eines angegebenen Namens des untergeordneten XML-Elements auszugeben. Deaktivieren Sie diese Option, um das Format der untergeordneten Elemente des Stammelements auszugeben. Siehe XML-Code lesen . | XML |
Stammelement zurückgeben | Wählen Sie diese Option aus, um das übergeordnete Element auszugeben, das alle anderen Elemente enthält. Siehe XML-Code lesen . | XML |
PreSQL auf Tool-Konfiguration ausführen | Diese Option ist standardmäßig ausgewählt und führt preSQL-Anweisungen aus, wenn ein Tool in einen Workflow eingebunden wird. Deaktivieren Sie das Kontrollkästchen, um preSQL-Anweisungen auszuführen, wenn stattdessen der Workflow ausgeführt wird. | |
Quelle und Beschreibung speichern | Diese Option ist standardmäßig ausgewählt und schließt Quell- und Beschreibungsdaten in die Metainformationen ein. Heben Sie die Auswahl der Option auf, um Quell- und Beschreibungsdaten auszuschließen. | |
SubDirs durchsuchen | Verwenden Sie diese Option, um mehrere Eingaben einzufügen, wenn sich Datendateien in einem Unterverzeichnis befinden und dieselbe Struktur, dieselben Feldnamen, dieselbe Länge und dieselben Datentypen enthalten. | |
Größe der Bulk-Load-Blöcke (1 MB bis 102400 MB) | Die Größe der zu schreibenden Bulk-Load-Blöcke. Die Standardeinstellung ist 128 MB. | |
Feldnamen überspringen | Wenn diese Option aktiviert ist, können Sie Daten nur in eine Tabelle oder einen Bereich schreiben. | XLSX, XLSM |
Geo-Objektfeld | Definieren Sie das in die Ausgabe einzubeziehende Geo-Objekt. Geodatendateien können pro Datensatz nur ein Geo-Objekt umfassen. Das Lesen oder Schreiben von mehreren Geometrietypen in einzelnen Dateien wird von Alteryx nicht unterstützt. | MDB*, TAB, OCI, SDF, SHP, GEO, KML, MID, MIF |
Transaktionsmeldungen anzeigen | Wählen Sie diese Option aus, um im Ergebnisfenster eine Meldung für die einzelnen Transaktionen anzuzeigen. Jede Meldung gibt die Summe der bis zu der jeweiligen Transaktion geschriebenen Datensätze an. | |
Datenimport starten ab Zeile | Definieren Sie eine Zeilennummer, bei der das Lesen der Daten beginnen soll. Standardmäßig beginnt es in Zeile 1. | CSV, XLSX |
Nullwerte unterstützen | Wählen Sie diese Option aus, um eine AVRO-Datei mit Nullwerten auszugeben. Diese Ausgabeoption vereint Felder mit einem Null-Zweig und einem Wert-Zweig. Wenn der Alteryx-Wert Null beträgt, wird für die Ausgabe der Null-Zweig verwendet. Andernfalls wird der Wert-Zweig verwendet. Wenn diese Option nicht ausgewählt ist, werden alle Ausgabefelder als deren systemeigene Avro-Typen (keine Vereinigung) geschrieben. Alteryx-Felder, die Null sind, werden als Standardwert geschrieben. Verwenden Sie das Formel-Tool , um Nullwerte mit einem „bekannten“ Wert zu verarbeiten, sodass sie in Hadoop gelesen werden können. | AVRO |
Tabellentyp | Verwenden Sie diese Option, um Systemstandard-, Spalten- oder Zeilentabellenspeicher auszuwählen. Die Tabellenspeicher zeigen an, wie die Daten gespeichert werden. Der Systemstandard berücksichtigt den Tabellenspeicher der zugrundeliegenden Datenbank. Die Leistung ist bei Erstellung von Spaltentabellenspeichern schwächer als bei Zeilentabellenspeichern. | SAP HANA ODBC |
Tabellen-/Feldname im SQL-Stil | Wählen Sie In Anführungszeichen oder Keine aus. Mit „In Anführungszeichen“ wird für den Datenbanktyp ein Bezeichner in Anführungszeichen verwendet. | OCI, OLEDB, ODBC |
Tabelle oder Abfrage | Wenn die Daten mehrere Tabellen enthalten, definieren Sie die Tabelle für die Eingabe oder wählen Sie diese Option aus, um eine Abfrage zu erstellen. Siehe Fenster „Tabelle auswählen oder Abfrage eingeben“ . | |
Dateinamen dem Feld entnehmen | Wählen Sie eine Option aus, um für jeden Wert eines bestimmten Felds eine separate Datei zu schreiben: Suffix dem Datei-/Tabellennamen anfügen : Fügt den ausgewählten Feldnamen dem Ende des Tabellennamens an. Präfix dem Datei-/Tabellennamen voranstellen : Stellt den ausgewählten Feldnamen dem Anfang des Tabellennamens voran. Dateiname ändern : Ändert den Dateinamen in den Namen des ausgewählten Felds. Gesamten Dateipfad ändern : Ändert den Dateinamen in den Namen des ausgewählten Felds, das einen vollständigen Pfad enthält. | alle Ausgabeformate |
Transaktionsgröße | Definieren Sie die Anzahl der jeweils in eine Datenbank zu schreibenden Datensätze. Datensätze werden in Batches mit weniger als 655.360 Byte oder Transaktionsgröße * Datensatzgröße festgeschrieben. Die Datensatzgröße wird basierend auf den Feldgrößen berechnet, die in der Workflow-Ausgabe angegeben sind. Wenn die Datensatzgröße größer als 655.360 Byte ist, wird die Transaktionsgröße automatisch auf 1 gesetzt. Bei Aktualisierungen ist die Transaktionsgröße immer 1. Standardmäßig beträgt die Transaktionsgröße 0, d. h. alle Datensätze werden berücksichtigt. Legen Sie die Anzahl der Datensätze mindestens auf 1000 fest, da die Datenbank für jede Transaktion eine temporäre Protokolldatei erstellt, wodurch der temporäre Speicher schnell voll werden kann. | OCI, OLEDB, ODBC |
Fehler als Warnungen behandeln | Wählen Sie diese Option für Eingabedaten mit Datensätzen aus, die nicht der Datenstruktur entsprechen. Bei Fehlern schlägt die Eingabe normalerweise fehl. Diese Option verhindert Eingabefehler, da Fehler als Warnungen behandelt werden. | |
Leerräume entfernen | Verwenden Sie die ausgewählte FLAT-Datei (Standardeinstellung), oder überschreiben Sie die Einstellung. | FLAT |
Zu verwendender Zeilenendetyp | Verwenden Sie die ausgewählte FLAT-Datei (Standardeinstellung), oder überschreiben Sie die Einstellung. | FLAT |
BOM schreiben | Wählen Sie diese Option aus, um die Byte-Reihenfolge-Markierung (Byte Order Mark, BOM) in die Ausgabe einzubeziehen, oder heben Sie die Auswahl dieser Option auf, um keine Byte-Reihenfolge-Markierung in der Ausgabe zu verwenden. | CSV |