Metadata is a set of data used to describe the input or output data of a Python SDK plugin. Plugins use Python Arrow data types to exchange data with Alteryx Designer. The metadata is used to map this data during the conversion to or from the internal Designer data format (Alteryx Multi-threaded Processing or AMP).
name: This is the same as the column name in a dataset.
type: The internal AMP Designer type.
size: The size of the data, in bytes.
scale: Scale is used only for 1 type:
fixeddecimal.source: This is a string that describes the origin of the data (for example, if data is read from a file in Designer, this is set to the file path of this input file).
description: This is an all-purpose string field.
It's not mandatory to use metadata in Python plugins. The simplest method is typically to create a Python Arrow schema directly, as the engine derives the necessary types when sent to Designer. But some plugins might need to export output data types to Alteryx Designer at plugin creation to build the workflow. In this case, metadata has to be sent to Designer through the __init__ method.
Also, sometimes you might need to fine-tune the data type used by Designer. Metadata is the only way to be sure to map a precise type of data to Designer because Python Arrow types might not allow for that. You might also want to modify fields like source or description to send some specific information through the Designer pipeline. Input metadata can also be used by the plugin for any reason, for example, the source field could be a file path the plugin can use.
You can use metadata in different places.
This method is called at plugin creation when Designer requests the output data types from the plugin before the workflow runs. You can send metadata to Designer at this time.
In this example, the data schema is a table with 2 columns of types int16 and string.
def __init__(self, provider: AMPProviderV2):
provider.push_outgoing_metadata("Output", create_schema({
"volts": {
"type": FieldType.int16
},
"device" {
"type": FieldType.string
}
}))
This method is called each time Designer sends data through the plugin. You can extract metadata from the input data for information and modify output data metadata. However, we don't recommend modifying the type, size, and scale as unexpected results can occur in Designer. You can modify the source and description.
On input plugins, a complete schema created with metadata can be exported to Designer for a precise data schema.
In this example, we specify type int16 for column volts and type string for column device.
def __init__(self, provider: AMPProviderV2):
provider.push_outgoing_metadata("Output", create_schema({
"volts": {
"type": FieldType.int16
},
"device" {
"type": FieldType.string
}
}))
In this case, description metadata is added to the batch.
def on_record_batch(self, batch: "pa.Table", anchor: Anchor) - > None:
batch = set_metadata(batch, {
"volts": {
"description": "Define the tension of the current"
}
})
self.provider.write_to_anchor("Output", batch)
This example shows how to use the source metadata. In this case, the source metadata is a file path, but it can be anything that describes the address of the source of the data.
def on_record_batch(self, batch: "pa.Table", anchor: Anchor) - > None:
meta = get_metadata(batch, "volts")
filepath = meta["source"]
with f = open(Path(filepath)):
content = f.read()
#...additional operations...
self.provider.write_to_anchor("Output", batch)
For V2 plugins, metadata is stored in PyArrow tables as a Python dictionary in each column schema. But Arrow doesn’t offer easy methods to access this metadata. The ayx_python_sdk.core.utils module provides functions to ease this access.
set_metadata(table, col_meta={}, schema=None)
This function updates column metadata from the given PyArrow table with a dictionary of column metadata or directly with a PyArrow Schema. It returns the new table with the new metadata. The input table remains unchanged.
This example modifies the metadata of 2 columns, volts and ampere.
def on_record_batch(self, batch: "pa.Table", anchor: Anchor) - > None:
batch = set_metadata(batch, {
"volts": {
"description": "tension"
},
"ampere": {
"source": "https://something.com"
}
})
self.provider.write_to_anchor("Output", batch)
get_metadata(table, col_name)
Get all columns' metadata or 1 column’s metadata if col_name is given, from the input PyArrow table.
If
col_nameis given, only the dictionary of metadata for this column is returned.If
col_nameis not given, it returns a dictionary of column names and their corresponding metadata dictionary.
def on_record_batch(self, batch: "pa.Table", anchor: Anchor) -> None:
meta_for_column_volts = get_metadata(batch, "volts")
The above example get_metadata returns the metadata for 1 column, of the following format (in this example):
meta_for_column_volts = {
"type": 3,
"size": 2,
"scale": 0,
"source": "",
"description": ""
}
注記
You can see in the above example that a number represents the type. Please refer to the Types section below for the mapping between type IDs and type names.
This example returns all metadata:
def on_record_batch(self, batch: "pa.Table", anchor: Anchor) -> None:
all_meta = get_metadata(batch)
The result dictionary looks like this:
all_meta = {
"volts": {
"type": 3,
"size": 2,
"scale": 0,
"source": "",
"description": ""
}
"device": {
"type": 9,
"size": 64,
"scale": 0,
"source": "",
"description": ""
}
}
Refer to this sequence diagram for a visual representation of the metadata lifecycle:
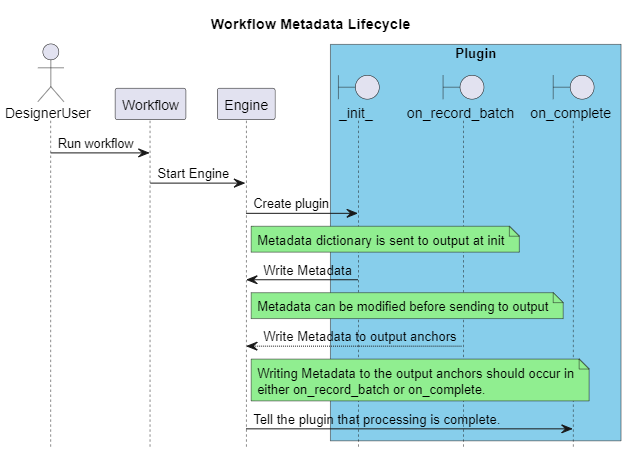
You can find a more complete example at Metadata Plugin Example.
The ayx_python_sdk.core.field module provides a definition of the Designer types with the class FieldType.
It defines a mapping between type names and a number:
FieldType.bool = 1
FieldType.byte = 2
FieldType.int16 = 3
FieldType.int32 = 4
FieldType.int64 = 5
FieldType.fixeddecimal = 6
FieldType.float = 7
FieldType.double = 8
FieldType.string = 9
FieldType.wstring = 10
FieldType.v_string = 11
FieldType.v_wstring = 12
FieldType.date = 13
FieldType.time = 14
FieldType.datetime = 15
FieldType.blob = 16
FieldType.spatialobj = 17
If only the type is specified at schema creation, the other metadata fields are automatically filled ("size", "scale", and "source").
The maximum size specified by "size" is set to the biggest when using string types but you can manually specify a size for string types. For example, if you set 4 as the size for a string, all strings in the corresponding column are truncated to 4 characters.
The type
FieldType.blobis not supported yet.The type
FieldType.spatialobjsupports spatial objects using the text format WKT. In order to use it,"source"metadata must be"WKT"(it's automatically set to it), so the source metadata field should not be modified.The type
FieldType.fixeddecimalrelies on"size"and"scale"metadata items to specify the size of the integer part (size) and the size of the fractional part (scale).