Transform Builder
The Transform Builder enables you to search for transformations and to rapidly assemble complete transform steps through a simple menu-driven interface.
After you select the transformation to apply, all relevant parameters can be configured through selection or type-ahead fields, so that you can choose from only the elements that are appropriate for the selected transformation.
Tip
When you add, edit, or delete a recipe step, your changes to the recipe are automatically saved.
To open the Transform Builder, begin creating a step through one of the following methods:
Select a transformation from the Transformer toolbar. See Transformer Toolbar.
Click the Macros icon in the toolbar to apply a macro as your next step. See Apply a Macro.
Select a transformation from a column menu. See Column Menus.
Search for and select a transformation in the Search panel. See Search Panel.
Click New Step in the Recipe panel. See Recipe Panel.
Edit an existing step.
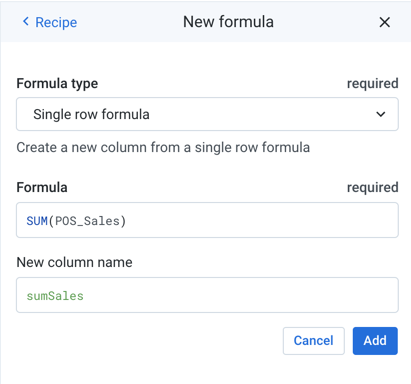
Figure: Transform Builder
Keyboard shortcuts:
Tip
When keyboard shortcuts are enabled, press ? in the application to see the available shortcuts. Individual users must enable them. See User Profile Page.
Step 1 - Select transformation in the Search Panel
From the Search panel, begin typing to see the list of available transformations. Select your preferred one.
Join and union transformations have dedicated pages for configuring this transformations. You can enter join datasets or union as the search term to open the corresponding tool:
See Join Window.
See Union Page.
For a list of available transformations, see Transformation Reference.
Step 2 - Specify the column(s), formula, or condition
Depending on the transform that you have selected, you must specify one or more of the following in the Transform Builder.
Some transforms support combinations of the following.
Some transforms, like
deduplicate, require no parameters.
The following are general categories of object types:
Literal values. A literal, or constant, value is a fixed numeric, string, Boolean, or other type of value, which does not change depending on the row under evaluation.
Functions. Designer Cloud supports a wide variety of numerical, statistical, and other function types. For a list of available transforms and functions, see Wrangle Language.
Columns. When a column name is used in a formula, the transform uses the value in the named column for the currently evaluated row.
Operators. You can apply logical, numeric, or comparison operators as part of your formula.
See Logical Operators.
See Numeric Operators.
See Comparison Operators.
Parameters: Add a reference to a flow parameter in your transformation. See Manage Parameters Dialog.
Metadata. You can insert special strings that evaluate to references of your dataset's metadata. For more information, see Source Metadata References.
Columns
Using the Columns parameter, you can select or specify the column or columns to which to apply the transform.
The following options are available when specifying one or more columns in a transformation:
Multiple: Select one or more discrete columns from the drop-down list.
All: Select all columns in the dataset.
Range: Specify a start column and ending column. All columns inclusive are selected.
Advanced: Specify the columns using a comma-separated list. You can combine multiple and range options under Advanced. Ranges of columns can be specified using the tilde (
~) character. Example:Store_Nbr, Item_Nbr, WM_Week~POS_Cost
Patterns
For some transforms, you can specify patterns to identify conditions or elements of the data on which to take action. These matching patterns can be specified using one of the following types.
Pattern Type | Description | Example |
|---|---|---|
Literal value | An exact string or value. | The following matches on the exact value between the quotes: |
Wrangle | Designer Cloud supports a variety of macro-like pattern identifiers, which can be used in place of more complex regular expressions. | The following matches when two digits appear at the beginning of a value:
|
Regular expression | Regular expressions are a standard method of describing matching patterns. Note The syntax of regular expressions can be complex and can lead to unexpected results if they are improperly specified. Regex is considered a developer-level skill. | The following matches on all numerical values from 0 to 99:
|
For more information on pattern-based matching, see Text Matching.
Flow parameter: You can also insert a flow parameter into your pattern-based inputs in the Transform Builder. To reference a flow parameter, click the Parameterize icon above any field that accepts pattern-based inputs.
The parameter values or any overrides applied to those values are applied to the results displayed in the data grid, as well as during job execution.
For more information on creating flow parameters, see Manage Parameters Dialog.
For more information on parameterization, see Overview of Parameterization.
Delimiter Groups
In the Transform Builder, transforms that require delimiter are organized into delimiter groups, so that you specify only the elements of a pattern that work together. Delimiter groups apply to the following transforms:
Delimiter groups are listed below.
Delimiter group | Description |
|---|---|
On delimiter | Transformation is applied based on a specific literal or pattern. |
Between delimiters | Transformation is applied on database between two literal or pattern-based delimiters. Details are below. |
On multiple delimiters | Transformation is applied based on a sequence of delimiters. An individual pattern can be a string literal, Wrangle , or regular expression, and the sequence can contain combinations of these pattern types. |
Between positions | Transformation is applied based on a starting index position and an ending index position. Index positions start from 0 on the left side of any cell value. |
On positions | Transformation is applied based on a sequence of listed index positions. Index positions start from 0 on the left side of any cell value. |
At regular interval | Transformation is applied at every nth position. Index positions start from 0 on the left side of any cell value. |
For more information on the underlying syntax for delimiter groups, see Pattern Clause Position Matching.
Matches any values that appear between two delimiters. One delimiter describes the beginning of the match, and the other delimiter describes the end of the match.
Each delimiter can either include or exclude the matching value:
Transform Builder option | Include as part of transform | Include/Exclude |
|---|---|---|
Start delimiter | false | Excludes sub-pattern |
Start delimiter | true | Includes sub-pattern |
End delimiter | false | Excludes sub-pattern |
End delimiter | true | Includes sub-pattern |
Condition
A condition is an expression that yields a true or false value. A condition may include all of the elements of a formula. This value determines whether the transformation is applied to the evaluated row.
Step 3 - Grouping, Ordering, and Naming
A number of transforms support the following parameters.
Note
Transforms that use the group parameter can result in non-deterministic re-ordering in the data grid. However, you should apply the group parameter, particularly on larger datasets, or your job may run out of memory and fail. To enforce row ordering, you can use the sort transform. For more information, see Sort Transform.
Group parameter: For transforms that aggregate data, such as pivot or window, you can specify the column by which you wish to group the computed aggregations. In the following example, all values in the POS_Sales column are summed up for each value in the Store_Nbr column.
Transformation Name |
|
|---|---|
Parameter: Row labels | Store_Nbr |
Parameter: Values | sum(POS_Sales) |
Assuming that there are entries in the Store_Nbr column, the resulting transform step has 50 rows, each of which contains the total sales for the listed store number.
Order parameter: Some transforms support the order parameter, which allows you to specify the column of values that are used to sort the output. In the following example, all aggregates Sales values are ordered by the contract date and grouped by State:
Transformation Name |
|
|---|---|
Parameter: Row labels | Store_Nbr |
Parameter: Column labels | contractDate |
Parameter: Values | sum(Sales) |
New Column Name parameter: For transforms that generate new columns, such as derive and extract, you can optionally specify the name of the new column, which saves adding a step to rename it. In the following example, the values of colA and colB are summed and written to the new column colC:
Transformation Name |
|
|---|---|
Parameter: Formula type | Single row formula |
Parameter: Formula | colA + colB |
Parameter: New column name | colC |
Step 3 - Specify other parameters
Depending on the transform, you may be presented with other required or optional parameters to specify. See Transforms.
Step 4 - Add the step
When you have finished your transform step, review the preview in the data grid.
If the results look ok, click Add.
The step is added to your recipe and applied to the data grid.
See Data Grid Panel.
See Transform Preview.
Edit a transform
After you have added a step, you can modify it as needed. In the Recipe panel, select the Pencil icon next to the recipe step. The step is displayed for editing in the Transform Builder.