
Introducción a En base de datos.
El procesamiento en base de datos permite la mezcla y el análisis frente a grandes conjuntos de datos sin mover los datos de una base de datos, lo que puede proporcionar mejoras significativas en el performance sobre los métodos de análisis tradicionales que requieren que los datos se muevan a un medio ambiente para el procesamiento.
Realizar análisis en la base de datos puede ahorrar tiempo de procesamiento. Con Alteryx Designer como interfaz, los flujos de trabajo en base de datos se integran con flujos de trabajo estándar para la combinación y análisis de datos adicionales.
Los objetos espaciales no se admiten actualmente con herramientas de base de datos.
- El procesamiento en base de datos requiere Alteryx de 64 bits con controladores de base de datos de 64 bits.
- Para ejecutar flujos de trabajo en el servidor Alteryx, el controlador ODBC debe configurarse como DSN de sistema. Para el procesamiento en base de datos, el tipo de conexión debe ser "System" además de la conexión ODBC que se configura como un DSN del sistema.
| Soporte en base de datos | Soporte predictivo de bases de datos |
|---|---|
| Amazon Redshift | |
| Apache Spark ODBC | |
| Cloudera Impala | |
| Databricks | |
| EXASOL | |
| Hive | |
| HP Vertica | |
| IBM Netezza | |
| Microsoft Analytics Platform System | |
| Base de datos de Microsoft Azure SQL | |
| Almacén de datos de Microsoft Azure SQL | |
| Microsoft SQL Server 2008, 2012, 2014, 2016 | Sí (2016) |
|
|
|
| Oracle | Sí |
| Pivotal Greenplum | |
| PostgreSQL | |
| SAP Hana | |
| Snowflake | |
| Teradata | Sí |
Consulta Fuentes de datos y formatos de archivo admitidos para la lista completa de plataformas de datos soportadas por Alteryx.
Consulta Analítica Predictiva para obtener más información sobre el soporte predictivo en base de datos.
| Nombre de la herramienta | Descripción de la herramienta | |
|---|---|---|
|
|
Buscar en la herramienta dB | Revise sus datos en cualquier punto de un flujo de trabajo in-dB. Nota: cada búsqueda en dB activa una consulta de base de datos y puede impactar el rendimiento. |
|
|
Herramienta Conexión en BDD | Establecer una conexión de base de datos para un flujo de trabajo in-dB. |
|
|
Secuencia de datos en la herramienta | Incorpora datos desde un flujo de trabajo estándar a uno In-BD. |
|
|
Herramienta de flujo de datos | Flujo de datos desde un flujo de trabajo in-dB a un flujo de trabajo estándar, con una opción para ordenar los registros. |
|
|
Herramienta de entrada dinámica en dB | Tome el nombre de conexión en dB y los campos de consulta desde una secuencia de datos estándar y los introduzca en un flujo de datos en dB. |
|
|
Herramienta de salida dinámica in-dB | Emitir como salida la información sobre el flujo de trabajo In-BD a un flujo de trabajo estándar para In-BD predictiva. |
|
|
Herramienta filtro in-dB | Filtra registros In-BD con un filtro básico o con una expresión personalizada utilizando el lenguaje nativo de la base de datos (p. ej.: SQL). |
|
|
Herramienta de fórmula in-dB | Crea o actualiza campos en un flujo de datos In-BD con una expresión que utilice el lenguaje nativo de la base de datos (p. ej.: SQL). |
|
|
Unirse a la herramienta in-dB | Combine dos flujos de datos en dB basados en campos comunes realizando una combinación interna o externa. |
|
|
Herramienta de entrada de macros en dB | Crea una conexión de entrada In-BD en una macro y complétala con valores de marcador de posición. |
|
|
Herramienta de salida de macros en dB | Crear una conexión de salida In-BD en una macro. |
|
|
Ejemplo de herramienta in-dB | Limita el flujo de datos In-BD a un número o a un porcentaje de registros. |
|
|
Herramienta Seleccionar en BDD | Seleccione, anule la selección, reordene y cambie el nombre de los campos en un flujo de trabajo in-dB. |
|
|
Resumir la herramienta in-dB | Resuma los datos in-dB agrupando, resumiendo, contando, contando campos distintos, y más. La salida solo contiene el resultado de los cálculos. |
|
|
Herramienta TRANSPOSE in-dB | Pivotear la orientación de una tabla de datos en un flujo de trabajo in-dB. Transforma los datos para que pueda ver los campos de datos horizontales en un eje vertical. |
|
|
Herramienta Union in-dB | Combina al menos dos flujos de datos In-BD con estructuras similares en función de los nombres o de las posiciones de los campos. En la salida, cada columna contendrá los datos de cada entrada. |
|
|
Herramienta escribir datos in-dB | Utiliza un flujo de datos In-BD para crear o actualizar una tabla directamente en la base de datos. |
| Nombre de la herramienta | Descripción de la herramienta | |
|---|---|---|
|
|
Herramienta Modelo aumentado | La herramienta modelo impulsada proporciona modelos de regresión propulsados generalizados basados en los métodos de aumento de gradiente de Friedman. |
|
|
Herramienta árbol de decisión | La herramienta árbol de decisiones crea un conjunto de reglas de división if y then que optimizan un criterio para crear un modelo que predice una variable de destino mediante una o más variables predictoras. |
|
|
Herramienta modelo forestal | La herramienta modelo de bosque crea un modelo que construye un conjunto de modelos de árbol de decisión para predecir una variable de destino basada en una o más variables predictoras. |
|
|
Herramienta de regresión lineal | La herramienta de regresión lineal construye una función lineal para crear un modelo que predice una variable de destino basada en una o más variables predictoras. |
|
|
Herramienta de regresión logística | La herramienta de regresión logística crea un modelo que relaciona una variable binaria de destino (como sí/no, Pass/Fall) a una o más variables predictoras para obtener la probabilidad estimada para cada una de las dos posibles respuestas para la variable de destino. |
|
|
Herramienta Puntuación | La herramienta puntuación evalúa un modelo y crea un campo de evaluación, o puntuación, que estima la precisión de los valores predichos por el modelo. |
Cuando se coloca una herramienta predictiva con soporte en base de datos en el lienzo con otra herramienta in-dB, la herramienta predictiva cambia automáticamente a la versión in-dB. Para cambiar manualmente la versión de la herramienta:
- Haz clic con el botón derecho en la herramienta.
- Elija la versión de la herramienta.
- Haga clic en una versión diferente de la herramienta.
Consulta Analítica Predictiva para obtener más información sobre el soporte predictivo en base de datos.
Dado que el procesamiento de flujo de trabajo en la base de datos se produce dentro de la base de datos, las herramientas de base de datos no son compatibles con las herramientas Alteryx estándar. Varios indicadores visuales muestran compatibilidad de conexión.
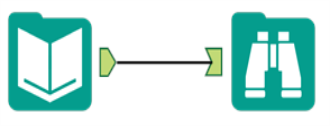
Herramientas estándar Utilice un anclaje de flecha verde para conectarse a otra herramienta. La conexión se muestra como una sola línea. |
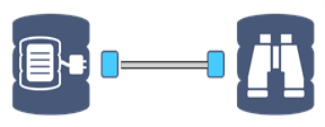
Las herramientas de base de datos utilizan un anclaje de base de datos de color azul cuadrado para conectarse a otra herramienta de base de datos. La conexión entre dos herramientas en la base de datos se muestra como una línea doble. Debido a la naturaleza del procesamiento en base de datos, no se muestra el progreso de la conexión. |
Para conectar herramientas estándar a herramientas de base de datos, utilice las herramientas de entrada y salida dinámicas o las herramientas de secuencia de datos.
Los datos se transmiten dentro y fuera de un flujo de trabajo dentro de la base de datos utilizando las herramientas de transmisión y transmisión de datos, o conectándose directamente a una base de datos mediante la herramienta Connect in-dB. Las herramientas Stream de datos y salida de datos utilizan un anclaje in-dB para conectarse a herramientas in-dB y un anclaje de flujo de trabajo estándar para conectarse a herramientas de flujo de trabajo estándar.
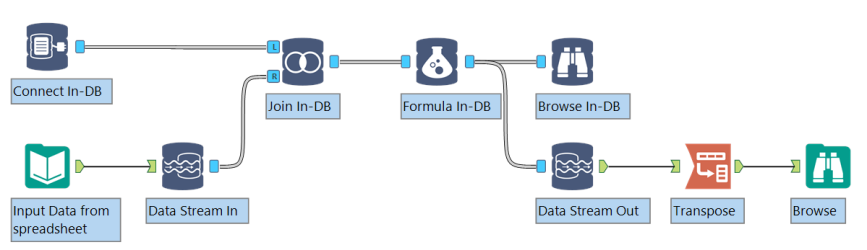
- Defina la conexión a la base de datos mediante la herramienta Connect in-dB o utilice la secuencia de datos en la herramienta para transmitir datos de un flujo de trabajo estándar a una tabla temporal de la base de datos.
- Conecte otras herramientas de la base de datos al flujo de trabajo para procesar los datos.
- Utilice la herramienta escribir datos in-dB para crear o actualizar una tabla en la base de datos, o utilizar la herramienta de salida de información para transmitir los resultados en dB a un flujo de trabajo para el procesamiento estándar.
- Ejecute el flujo de trabajo para procesar los datos en la plataforma de datos. No se devuelve ningún resultado al motor Alteryx hasta que se haya procesado el flujo de trabajo completo en la base de datos.
El procesamiento del flujo de trabajo puede tardar más tiempo cuando una gran cantidad de datos se transmiten dentro y fuera de una base de datos. El procesamiento en base de datos se puede utilizar para acelerar un flujo de trabajo.
Por ejemplo, en un flujo de trabajo estándar, una tabla de base de datos grande es arrastrada a la memoria para unirse con una pequeña hoja de cálculo. La mayoría del tiempo de ejecución se gasta en streaming en los registros de la base de datos. En un flujo de trabajo en la base de datos, la pequeña hoja de cálculo se transmite a la base de datos, reduciendo sustancialmente el tiempo de ejecución.
Los privilegios de lectura son necesarios para acceder a la base de datos subyacente.
Los privilegios de escritura son necesarios para crear una tabla en la base de datos.
Las tablas temporales se eliminan al final de la ejecución. Si Alteryx se bloquea mientras se ejecuta la secuencia de datos de la herramienta, la próxima vez que se ejecute un flujo de trabajo en la base de datos, todos los archivos temporales creados por Alteryx en la base de datos en los tres días anteriores se limpian.
Para permitir la visibilidad de una tabla temporal entre sesiones, Alteryx debe crear una tabla permanente que eventualmente se elimine al final de un flujo de trabajo. Es necesario tener permisos de creación para transmitir datos desde una base de datos y escribir datos en una base de datos. La excepción es Microsoft SQL Server.
Las reglas subyacentes se mantienen durante el proceso de la misma manera que con las conexiones de base de datos mediante los datos de entrada estándar y las herramientas de datos de salida. Si hay un tiempo de espera de la base de datos o si hay un límite al número de consultas por día que se puede ejecutar, afectará a la conexión a la base de datos.
Una instrucción SELECT es activada por la herramienta Connect in-dB y las consultas adicionales se crean mediante herramientas descendentes y anidadas dentro de esta consulta. La adición de una de las tres herramientas siguientes completa la consulta y la envía a la base de datos subyacente: escriba in-dB, Data Stream out, examine in-dB.
Puede introducir su propia instrucción SQL en el cuadro de consulta de la herramienta Connect in-dB, que también se incrusta dentro de la instrucción SELECT.
La consulta SQL para la base de datos subyacente se activa en tiempo de ejecución para cada herramienta examinar en dB, flujo de datos o escritura de datos en-dB.
La herramienta examinar datos en dB se puede configurar para almacenar en caché los datos como un archivo. yxdb cuando se ejecuta el flujo de trabajo.
Una vez que los datos se almacenan en caché, si el flujo de trabajo se vuelve a ejecutar y la conexión o consulta de la base de datos (incluido el número de registros que se van a examinar) no ha cambiado, la consulta no se volverá a ejecutar. En su lugar, los datos se sacarán de la caché.
Un mensaje de salida indica si los datos se almacenaron en caché o no. Al hacer clic en el vínculo se abrirá el resultado de los datos como un archivo. yxdb en una ventana separada.
La caché en la base de datos se utiliza en cualquier momento en que se vuelva a ejecutar un flujo de trabajo sin cambios en las herramientas de upstream. Al realizar un cambio en cualquier herramienta upstream se desencadenará una nueva consulta y se creará una nueva caché.
No, la opción "examinar primero [100] Records" sólo limita el número de registros mostrados en la herramienta examinar en-dB. Otras herramientas del flujo de trabajo procesarán el número de registros que se pasan a través de un punto determinado.
El campo tiene tipo de CLOB/LOB y no funciona con la mayoría de los operadores de comparación en las herramientas de filtro o fórmula. El error refleja que no se devuelven columnas, incluso cuando los datos coinciden con la comparación. Este comportamiento se espera con SQL y Oracle, ya que no admiten comparaciones con los datos de LOB.