ドライバー設定要件 | インデータベース処理の場合、 データ出力ツール でデータを書き込むときのエラーを避けるために、ドライバーにウェアハウス、スキーマ、データベースを指定します。 |
サポートのタイプ | 読み取りと書き込み、インデータベース。 |
検証済み | データベースバージョン: 6.8.1 ODBCクライアントバージョン: 3.0.0.1001 64ビット |
データ出力ツール (標準ワークフロー処理)
接続In-DBツールおよびデータストリーム入力ツール(インデータベースのワークフロー処理)。


[ データ入力ツール ] を選択し、[ データ入力 (1) - 設定 ] ウィンドウに移動し、[ ファイルまたはデータベースを接続 ] の下の ドロップダウンアイコン を選択します。
[ データ接続 ] ウィンドウ > [ すべてのデータソース ] > [ Snowflake ] > [ ODBC ] の順に選択します。
[ Snowflake ODBC接続 ] ポップアップウィンドウで、 ユーザー名 と パスワード を入力します。
[ テーブルの選択またはクエリの指定 ] ウィンドウで [ テーブル ] タブ > テーブル > [ OK ] の順に選択します。
クラシック モード で作業する場合は、[ オプション ] > [ ユーザー設定 ] > [ ユーザー設定の編集 ] の順に移動し、[ 入力/出力ツールのメニューオプションにクラシックモードを使用する ] チェックボックスをオンにします。
クエリを指定するには、[ SQLエディター ] タブを選択し、利用可能なスペースにクエリを入力し、[ クエリをテスト ] ボタン > [ OK ] の順に選択します。
[ データ出力ツール ] を選択し、[ メニュー ] > [ オプション ] の順に移動します。
[ ユーザー設定 ] > [ ユーザー設定の編集 ] の順に選択し、[ 入力/出力ツールメニューオプションにクラシックモードを使用する ] チェックボックスをオンにします。
[ データ出力 (1) - 設定 ] ウィンドウに移動し、[ ファイルまたはデータベースへの書き込み ] の下にある ドロップダウンアイコン を選択します。
[ その他のデータベース ] > [ Snowflakeバルク... ] の順に選択します。
データ入力ツール(クラシックモード) を使用して、ファイルとデータソースを選択することもできます。
クラシックモード に切り替える場合は、 データ出力ツール を新しいツールに置き換えて、[ キャンバス ] を選択するか、 F5 キーを押して表示を更新します。
テーブルと列の読み書きを完全にサポートするには、Alteryx Designerの [ テーブル/フィールド名 SQL スタイル ] オプションを [ 引用符付き ] に設定する必要があります。引用符付きにするとデータベース内のテーブルの文字がそのままの状態で選択されますが、[ なし ] を選択すると結果がすべて大文字になります。
Snowflake バルク接続を設定する前に、次の点を確認してください。
Snowflake バルクローダーでは、データの書き込みのみ可能です。
新しい出力にデータを書き込んだ後に、Snowflake バルクローダーは、書き込まれたデータを S3 バケットから削除します。
テキストフィールドの最大長は16,777,216バイトです。
詳細については、 Snowflakeのドキュメント を参照してください。
ODBCデータソースアドミニストレーター でSnowflakeドライバーを選択し、[ 設定 ] を選択します。
接続設定と資格情報を入力します。
[ OK ] を選択して、接続を保存します。
注記
キャメルケースのテーブルと列の読み書きを完全にサポートするには、Alteryx Designerの [ テーブル/フィールド名SQLスタイル ] オプションを [ 引用符付き ] に設定する必要があります。
ODBC ドライバーを通じて Snowflake JWT を設定する方法:
Snowflake の手順 (https://docs.snowflake.com/en/user-guide/key-pair-auth.html) に従って、トークンを作成します。
ODBC DSN の認証方式を SNOWFLAKE_JWT に設定します。
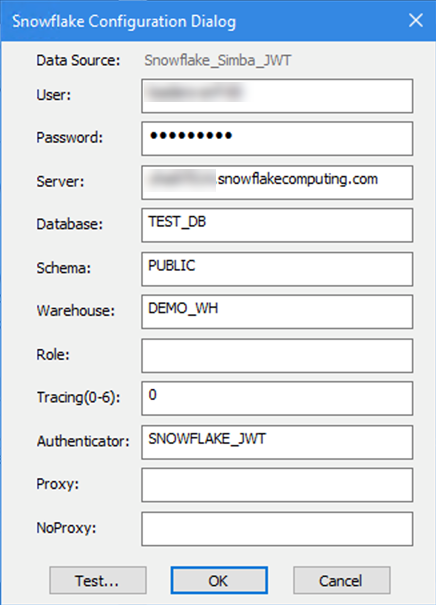
Alteryx では、接続文字列はファイルの場所を指す必要があります(例:
odbc:DSN=Simba_Snowflake_JWT;UID=user;PRIV_KEY_FILE=G:\AlteryxDataConnectorsTeam\OAuth project\PEMkey\rsa_key.p8;PRIV_KEY_FILE_PWD=__EncPwd1__;JWT_TIMEOUT=120)。詳細については、 Snowflakeのドキュメント を参照してください。
[ データ出力ツール ] を選択し、[ データ出力 (1) - 設定 ] ウィンドウに移動します。
[ ファイルまたはデータベースへの書き込み ] の下にある ドロップダウンアイコン を選択し、[ データ接続 ] ウィンドウに移動し、[ データソース ] タブ > [ すべてのデータソース ] > [ Snowflake ] > [ バルク ] の順に選択します。
[ Snowflakeバルク接続 ] ウィンドウで、[ ローカル ] タブを選択し、[ ユーザー名 (オプション) ] および [ パスワード(オプション) ] フィールドに資格情報を入力します。[ OK ] を選択すると、[ 出力テーブル ] ポップアップウィンドウが表示されます。
テーブル名 、または db.schema.tablename (完全修飾テーブル)という形式で指定された出力ファイルの テーブル(またはワークシート)の名前 を入力します。
[ データ出力 (1) - 設定 ] ウィンドウの [ オプション ] の下にある [ テーブル/フィールド名SQLスタイル ] ドロップダウンの [ 引用符付き ] または [ なし ] を選択します。
[ フィールドからファイル/テーブル名を取得する ] の下にある [ ファイル/テーブル名に接尾辞を追加する ] ドロップダウンのチェックボックスをオンにするかどうかを決定します。チェックボックスをオンにした場合は、ドロップダウンの選択肢から以下を選択します。
ファイル/テーブル名に接尾辞を追加する
ファイル/テーブル名に接頭辞を追加する
ファイル/テーブル名を変更する
ファイルパス全体を変更する
[ ファイル/テーブル名に接尾辞を追加する ] を選択した場合、[ ファイル名またはファイル名の一部を含むフィールド ] の下で次のいずれかを選択します。
SEQUENCE_CATALOG
SEQUENCE_SCHEMA
SEQUENCE_NAME
SEQUENCE_OWNER
DATA_TYPE
NUMERIC_PRECISION
NUMERIC_PRECISION_RADIX
NUMERIC_SCALE
START_VALUE
MINIMUM_VALUE
MAXIMUM_VALUE
NEXT_VALUE
INCREMENT
CYCLE_OPTION
CREATED
LAST_ALTERED
コメント
テーブルのデータで使用するためにドロップダウンから選択したオプションに対して、[ 出力でフィールドを保持する ] チェックボックスをオンにするかどうかを決定します。
[ データ出力 - 設定 ] ウィンドウの [ ファイルまたはデータベースへの書き込み ] を選択し、[ その他のデータベース] > [Snowflakeバルク ] の順に選択し、[ Snowflakeバルク接続 ] ウィンドウを表示します。
[ データソース名 ]、または [ ODBC管理者 ] を選択して、いずれかを作成します。ODBCとOLEDBのデータベース接続を参照してください。
必要に応じて、 ユーザー名 と パスワード を入力します。
Amazon S3 で、 AWS アクセスキー と AWS シークレットキー を入力します。
[ シークレットキー暗号化 ] から、次の暗号化オプションを選択します。
非表示 : 最小限の暗号化を使用してパスワードを非表示にします。
マシンに対して暗号化 : コンピューター上のユーザーであれば接続にフルアクセスできます。
ユーザーに対して暗号化 : ログインしているユーザーはどのコンピューターでも接続にフルアクセスできます。
[ エンドポイント ] から、次のいずれかのオプションを選択します。
既定 : 選択したバケットに基づいてAmazonがエンドポイントを決定します。
特定のエンドポイント : バケットが存在する S3 地域を指定するには、カスタムエンドポイントを指定するか、以前に入力したエンドポイントから選択します。
S3 バケットは指定された S3 リージョン内にある必要があります。ない場合は、「 アクセスしようとしているバケットは、指定されたエンドポイントを使用してアドレス指定をする必要があります 」というエラーが表示されます。 今後のリクエストはすべてこのエンドポイントに送信してください。
[ 既定 ] を選択して、エラーウィンドウを閉じます。
(オプション)既定の署名V2を上回るセキュリティにする場合は、[ 認証に署名V4を使用する ] を選択します。このオプションは、署名 V4 が必要なリージョンでは自動的に有効になります。2014 年 1 月 30 日より後に作成されたリージョンでは、署名 V4 のみがサポートされます。次のリージョンでは、署名 V4 認証が必要です。
アメリカ東部 (オハイオ) 地域
カナダ (中央) 地域
アジア太平洋 (ムンバイ) 地域
アジア太平洋 (ソウル) 地域
EU (フランクフルト) 地域
EU (ロンドン) 地域
中国 (北京) 地域
暗号化された Amazon S3 バケットにアップロードする場合は、 サーバーサイド暗号化メソッド を選択します。『Amazon Simple Storage Service 開発者ガイド』を参照してください。
None (Default) : 暗号化方式は使用されません。
SSE-KMS : AWS KMS で管理されたキーでサーバーサイドの暗号化を使用します。 KMSキーID を指定することもできます。この方法を選択すると、 認証にSignature V4 を使用する ことが既定で有効になります。
データオブジェクトが格納されているAWSバケットの [ バケット名 ] を入力します。
[ データ出力 (1) - 設定 ] ウィンドウで、追加の [ ファイル形式オプション ] を設定します。ファイル形式オプションを参照してください。
ローカルドライブにデータをステージングするときに、3 つの拡張オプションから選択できるようになりました。
[ データ出力ツール ] を選択し、[ データ出力 (1) - 設定 ] ウィンドウに移動し、[ ファイルまたはデータベースへの書き込み ] の下の [ データ接続 ] ウィンドウへ移動し、[ データソース ] タブ > [ すべてのデータソース ] > [ Snowflake ] > [ バルク ] の順に選択します。[ Snowflake バルク接続 ] ウィンドウで、[ ローカル ] タブを選択します。
ユーザーステージ : ユーザーに関連付けられた、Snowflakeが提供する内部ステージ。
[ ユーザー ] > [ OK ] の順に選択します。[ テーブル出力 ] ポップアップウィンドウで、 テーブル名 、または db.schema.tablename (完全修飾テーブル)という形式で指定された出力ファイル形式の テーブル(またはワークシート)の名前 を入力します。 OK を選択します。[ データ出力 (1) - 設定 ] ウィンドウの [ オプション ] の下にある [ テーブル/フィールド名SQLスタイル ] ドロップダウンの [ 引用符付き ] または [ なし ] を選択します。
テーブルステージ : テーブルに関連付けられた、Snowflakeが提供する内部ステージ。
[ テーブルステージ ] > [ OK ] の順に選択します。[ テーブル出力 ] ポップアップウィンドウで、 テーブル名 、または db.schema.tablename (完全修飾テーブル)という形式で指定された出力ファイル形式の テーブル(またはワークシート)の名前 を入力します。 OK を選択します。[ データ出力 (1) - 設定 ] ウィンドウの [ オプション ] の下にある [ テーブル/フィールド名SQLスタイル ] ドロップダウンの [ 引用符付き ] または [ なし ] を選択します。
内部名前付きステージ : Snowflakeデータベース で CREATE STAGE コマンドを作成して実行し、 ステージ名 をツール設定に提供します。
注記
最大フィールドサイズは 16 MB です。フィールドサイズの閾値を超えると、エラーがスローされ、データが書き込まれなくなります。
圧縮タイプ : 選択肢は「圧縮なし」と「Gzipで圧縮」です。
圧縮なし: ファイルはステージングされ、CSVとしてアップロードされます。
GZIP で圧縮: CSV ファイルが GZIP で圧縮されます。
MB単位のチャンクサイズ(1-999) : このオプションを使用すると、ローカルにステージングされる各CSVのサイズを選択できます。
注記
実際のファイルサイズは、もとになるフォーマットと圧縮により、選択したチャンクサイズとは異なる場合があります。
スレッドの数 (1-99) : Snowflake にファイルをアップロードする際に使用するスレッドの数を指定します。この値が大きくなると、より大きなファイルのパフォーマンスが向上する場合があります。0 を入力すると、Snowflake の既定 (4) が使用されます。
ステージから、テーブルへの各 copy into には、最大 1000 個のファイルを含めることができます。ステージに 1000 個を超えるファイルがある場合、複数の copy into ステートメントが表示される場合があります。これは、ファイルを使用している copy into ステートメントへの Snowflake の要件です。詳細については、 Snowflakeのポータル を参照してください。
圧縮タイプ、MB単位でのチャンクサイズ、スレッド数オプションの詳細については、 Snowflakeのポータル を参照してください。