Driver Configuration Requirements | For the in-database process, and to avoid errors when you write data with the Output Data tool, specify a Warehouse, Schema, and Database in the driver. |
Type of Support | Read & Write; In-Database. |
Validated On | Database Version: 6.8.1 ODBC Client Version: 3.0.0.1001 64-bit |
Output Data Tool (Standard workflow processing)
Connect In-DB Tool and Data Stream In Tool (In-database workflow processing)


Select the Input Data tool and navigate to the Input Data (1) - Configuration pane > Select the dropdown icon under Connect a File or Database.
Navigate the Data connections window > All data sources > Snowflake > ODBC.
In the Snowflake ODBC Connection pop-up window, enter your User name and Password.
In the Choose Table or Specify Query window, select the Tables tab > Select a table > Select OK.
If wanting to work in Classic mode, navigate to Options > User Settings > Edit User Settings > Select the Use classic mode for the Input/Output tool menu options checkbox.
To specify a query, select the SQL Editor tab > Enter the query in the available space > Select the Test Query button > Select OK.
Select the Output Data tool, and navigate to the menu > Options.
Select User Settings > Edit User Settings > Select the Use classic mode for the Input/Output tool menu options checkbox.
Navigate to the Output Data (1) - Configuration pane > Under Write to File or Database > Select the dropdown icon.
Select Other Databases > Select Snowflake Bulk....
You can also use the Input Data tool (Classic Mode) to select your files and data sources.
If wanting to switch to Classic mode, replace your Output Data tool with a new tool > Select the canvas, or F5 to refresh.
To fully support the read and write of tables and columns, set the Alteryx Designer Table/Fieldname SQL style option to Quoted. Quoted will specifically select the table in the database, while selecting None will produce results in all caps.
Review the following before you configure a Snowflake Bulk connection:
You can only write data with the Snowflake Bulk loader.
After writing data to the new output, the Snowflake Bulk loader removes the written data from the S3 bucket.
Maximum allowed length for text fields is 16,777,216 bytes.
For more information, see the Snowflake documentation.
In the ODBC Data Source Administrator, select the Snowflake driver and select Configure.
Enter your Connection Settings and credentials.
Select OK to save the connection.
Note
To fully support the reading and writing of camel case tables and columns, you must set the Alteryx Designer Table/Fieldname SQL style option to quoted.
To configure Snowflake JWT through the ODBC driver:
Create the token as per the instructions from Snowflake: https://docs.snowflake.com/en/user-guide/key-pair-auth.html.
Set the Authenticator in the ODBC DSN to SNOWFLAKE_JWT.
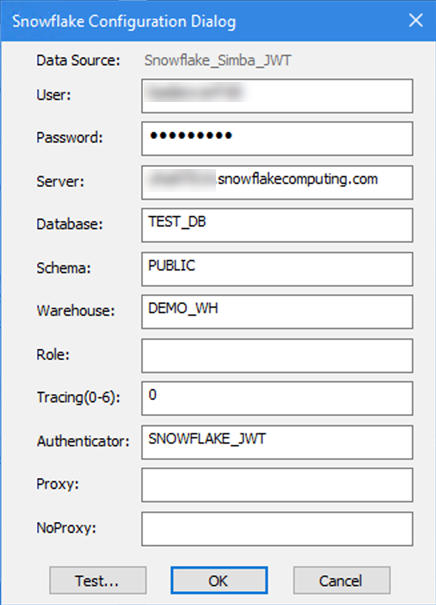
In Alteryx, the connection string has to point at the file location, e.g.:
odbc:DSN=Simba_Snowflake_JWT;UID=user;PRIV_KEY_FILE=G:\AlteryxDataConnectorsTeam\OAuth project\PEMkey\rsa_key.p8;PRIV_KEY_FILE_PWD=__EncPwd1__;JWT_TIMEOUT=120For more instructions, see Snowflake Documentation.
Select the Output Data tool, and navigate to the Output Data (1) - Configuration pane.
Under Write to File or Database, select the dropdown icon > navigate the Data connections window to select the Data sources tab > All data sources > Snowflake > Select Bulk.
In the Snowflake Bulk Connection window, select the Local tab > Enter your credentials in the Username (optional) and Password (optional) spaces > Select OK to view the Output Table pop-up window.
Enter the table (or worksheet) name for the output file that was specified, either with the table name, or in the form of db.schema.tablename: this is your fully qualified table.
Under Options, in the Output Data (1) - Configuration pane, select from the Table/FildName SQL Style dropdown either with Quoted or None.
Under Take File/Table Name From Field, decide whether to select its checkbox for the Append Suffix to File/Table Name dropdown. If you select the checkbox, from the dropdown selections, choose to...
Append Suffix to File/Table Name.
Prepend Prefix to File/Table Name.
Change File/Table Name
Change Entire File Path.
If you select the Append Suffix to File/Table Name checkbox, under Field Containing File Name or Part of File Name, select to use one of the following:
SEQUENCE_CATALOG
SEQUENCE_SCHEMA
SEQUENCE_NAME
SEQUENCE_OWNER
DATA_TYPE
NUMERIC_PRECISION
NUMERIC_PRECISION_RADIX
NUMERIC_SCALE
START_VALUE
MINIMUM_VALUE
MAXIMUM_VALUE
NEXT_VALUE
INCREMENT
CYCLE_OPTION
CREATED
LAST_ALTERED
COMMENT
Decide whether to select the Keep Field in Output checkbox, for the option that you have selected from the dropdown to use with your table's data.
From the Output Data - Configuration window, select Write to File or Database and select Other Databases > Snowflake Bulk to display the Snowflake Bulk Connection window.
Select a Data Source Name, or select ODBC Admin to create one. See ODBC and OLEDB Database Connections.
Enter a User Name and Password, as necessary.
In Amazon S3, enter your AWS Access Key and your AWS Secret Key.
From Secret Key Encryption, select an encryption option:
Hide: Hides the password using minimal encryption.
Encrypt for Machine: Any user on the computer has full access to the connection.
Encrypt for User: The logged in user has full access to the connection on any computer.
From Endpoint, select one of the following options:
Default: Amazon determines the endpoint based on the selected bucket.
Specific endpoint: To specify an S3 region in which the bucket resides, specify a custom endpoint or select from previously entered endpoints.
The S3 bucket must be in the specified S3 region. Otherwise, the following error displays: The bucket you are attempting to access must be addressed using the specified endpoint. Please send all future requests to this endpoint.
Select Default to close the error window.
(Optional) Select Use Signature V4 for Authentication to increase security beyond the default Signature Version 2. This option is automatically enabled for regions requiring Signature Version 4. Regions created after January 30, 2014 support only Signature Version 4. The following regions require Signature Version 4 authentication:
US East (Ohio) Region
Canada (Central) Region
Asia Pacific (Mumbai) Region
Asia Pacific (Seoul) Region
EU (Frankfurt) Region
EU (London) Region
China (Beijing) Region
Select a Server-Side Encryption method for uploading to an encrypted Amazon S3 bucket. See Amazon Simple Storage Service Developer Guide.
None (Default): An encryption method is not used.
SSE-KMS: Use server-side encryption with AWS KMS-managed keys. You can also provide a KMS Key ID. When you select this method, Use Signature V4 for Authentication is enabled by default.
Enter the Bucket Name of the AWS bucket in which the data objects are stored.
Configure additional File Format Options in the Output Data (1) - Configuration pane. See File Format Options.
You now have three enhanced options to choose from when you stage data to your local drive!
Select the Output Data tool, and navigate to the Output Data (1) Configuration pane > Under Write to File or Database, navigate the Data connections window and select the Data sources tab > All data sources > Snowflake > Select Bulk. In the Snowflake Bulk Connection window > Select the Local tab >
User Stage: The internal stage provided by Snowflake, associated with the user.
Select User > Select OK. In the Output Table pop-up window, enter the table (or worksheet) name for the output file format that was specified either with the table name, or in the form of db.schema.tablename: this is your fully qualified table. Select OK. Under Options in the Output Data (1) - Configuration pane, select from the Table/FieldName SQL Style dropdown either with Quoted or None.
Table Stage: The internal stage provided by Snowflake, associated with the table.
Select Table Stage > Select OK. In the Output Table pop-up window, enter the table (or worksheet) name for the output file format that was specified either with the table name, or in the form of db.schema.tablename: this is your fully qualified table. Select OK. Under Options in the Output Data (1) - Configuration pane, select from the Table/FieldName SQL Style dropdown either with Quoted or None.
Internal Name Stage: In the Snowflake database, create and execute a CREATE STAGE command, and provide the stage name to the tool configuration.
Note
The maximum field size is 16MB. If the field size threshold is exceeded, an error will be thrown and no data will be written.
Compression Type: Options are either “No Compression” or “Compress with GZip.”
No compression - files are staged and uploaded as CSV
Compress with GZIP - CSV files are zipped with GZIP
Chunk Size in MB (1-999): This option allows you to select the size of each CSV that gets staged locally.
Note
Actual file size may vary from selected Chunk Size due to underlying formatting and compression.
Number of Treads (1-99): This option specifies the number of threads to use for uploading files to Snowflake. Performance may improve for larger files when this value is increased. If 0 is entered, the Snowflake default is used (4).
From stage, each copy into the table can contain up to 1000 files. If there are more than 1000 files in stage, you may see multiple copy into statements. This is a Snowflake requirement for copy into statements using files. For more information, see Snowflake portal.
More information on Compression type, Chunk size in MB, andNumber of treads options can be found on Snowflake portal.