Depending on the file format or database connection you use to input or output data, configuration options vary. Select file format options in these tools: Input Data tool, Output Data tool, Connect In-DB tool, Data Stream In tool, Write Data In-DB tool.
Option | Description | File Formats |
|---|---|---|
Allow Extraction of Files >2GB | Select to allow Alteryx to extract a file greater than 2 GB. See Zip File Support and Gzip File Support. | .zip, *.gz, *.tgz |
Allow Shared Write Access | Select to read an open file that may be in the process of being updated. This option is intended for reading web logs. | |
Append to Existing Table | Select to append records to an existing table. | .dbase, .sdf |
Append Field Map | Select to append fields and set how output fields will map to the fields in the OleDB table. | .mdb, .xls, .accdb, ODBC, OLEDB |
Code Page | Select a code page for converting text within input or output data. See Code Pages. | .csv, .dbf, .flat, .json, .mid, .mif, .tab, .shp |
Create Int32 Fields as Binary | Select to create all Int32 fields as 32 bit (4 byte) binary values in the database instead of the default 11-character text format. This option is not supported by all DBF readers. | .dbase |
Delimiter | Select the field delimiter in the data. Use \0 to read or write a text file with no delimiter. Use 0 if the data contains two or more delimiters to force Designer to read the data as flat text. Use the RegEx tool in Tokenize mode to parse your data. | .csv, .txt |
Description or Data File | Define the file name of a .flat file used as a layout file. | .flat |
Do not show % Complete | Select to disable a status report of file read-in progress; this speeds up read time. | |
Enable Compression (Deflate) | Select to output a compressed .avro file. The deflate algorithm (similar to gzip) is used and should be supported by other Avro-capable tools such as Hive. Compression increases output time, but with larger files, it will reduce network time. | .avro |
Enable SQL Server FileTable Support | Select to write an Excel file to a Microsoft SQL Server FileTable | .xlsx |
Expand Value Labels | Read and apply value labels (key) to data. This option is selected by default for SPSS and SAS files. See Stat Transfer Supported File Formats. If not selected, only the value key is displayed. | .spss, .sas |
Field Length | Define the maximum field length in the input data. | |
File Format | Select the data file format. | all formats |
File in Archive | Change the file (or files) to input. See Zip File Support. | .zip |
First Row Contains Data | Select if the first row should be treated as data, not a header. | .xlsx |
First Row Contains Field Names | Select if the first row should be treated as a header. | .csv |
Force SQL WChar Support | Select to allow character columns to be treated as SQL_WCHAR, SQL_WVARCHAR, or SQL_WLONGVARCHAR. | .oci, unicode.txt |
If Long Lines are Allowed | Use the selected .flat file (default), or override the setting. | .flat |
If Short Lines are Allowed | Use the selected .flat file (default), or override the setting. | .flat |
Ignore Delimiters in | Select an option: Quotes: Ignore delimiters in quotes. SingleQuotes: Ignore delimiters in single quotes. Auto: Ignore auto-detected delimiters. None: Do not ignore delimiters. | |
Ignore XML Errors and Continue | Ignore incorrect XML formatting and continue running the workflow. See Reading XML. | .xml |
Line Ending Style | Define the character or sequence of characters signifying the end of a line of text. | .csv, .flat |
Max Records Per File | Define the number of records to output to a single file. If the data contains more records, multiple files are created and named sequentially. | all formats |
No Spatial Index | Select to turn off the spatial index. Use this option only when writing large temporary files that will not be used in spatial operations. This option writes smaller files faster. | .yxdb |
Output all Fields as Strings | Select to convert incoming fields to string data type; this bypasses conversion errors if the data type is wrong in .dbf files. | .dbf |
Output File Name as Field | Select to append a field with the file name or file path to each record. | |
Output Options | Select an output option: Create New Sheet: Creates a new sheet, but does not overwrite an existing sheet. Append to Existing Sheet: Appends data to an existing sheet so that the output consists of new and previous data. Overwrite Sheet or Range: Deletes the data in the selected sheet or range and writes data into the sheet or range with the selected name. Do not use the above option if your Excel file contains formulas, tables, charts, and images as these items can be corrupted. Overwrite File (Remove): Deletes the existing file and creates a new file. | .xlsx, .xlsm (via Alteryx .xlsx driver) |
Output Options | Select an output option: Create New Table: Creates a new table, but does not overwrite an existing table. Append Existing: Appends data to an existing table so that the output consists of Records Before plus Records After. Delete Data and Append: Deletes all original records from the table and appends data to the existing table. Overwrite Table (Drop): Drops the existing table and creates a new table. | .accdb, .mdb, .tde, .xls, .xlsx (via the legacy .xlsx driver), .oci, OLEDB, ODBC |
Output Options | Select an option: Update, warn on failure: Updates existing records using the output and warns if a record could not be updated. Update, error on failure: Updates existing records using the output and stops processing if a record could not be updated. Update, insert if new: Updates existing records using the output and inserts new records if they were not in the database table and stops processing if a record could not be updated. Primary key field needs to be included for the update to work. If there are multiple records with the same primary key and no other SQL errors occur, the new record updates the older record in the database. Use the Unique Tool to check for multiple primary keys prior to writing to the database. | .oci, OLEDB, ODBC |
Overwrite Existing Table | Selected by default, this option overwrites an existing file type of the same name. | .mdb* |
Parse Selected File as | Change the format in which to parse the file. | .zip |
Parse Value as String | Select to parse output data as a string; if not selected, data is parsed based on the data type. | |
Passwords | Select how a password will display in the Configuration window: Hide (default), Encrypt for Machine, Encrypt for User. | |
Post Create SQL* Statement | Define an SQL statement to execute via the ODBC/OLEDB driver after the output table is created. | .mdb, .mdb*, .oci, .accdb, ODBC, OLEDB |
Pre Create SQL* Statement | Define an SQL statement to execute via the ODBC/OLEDB driver before the output table is created. | .mdb, .mdb*, .oci, .accdb, ODBC, OLEDB |
Preserve Formatting on Overwrite (Range Required) | Preserve the Excel formatting of the range that you are overwriting. Do not use this option if your Excel file contains formulas, tables, charts, and images as these items can be corrupted. When you select this option, you must also:
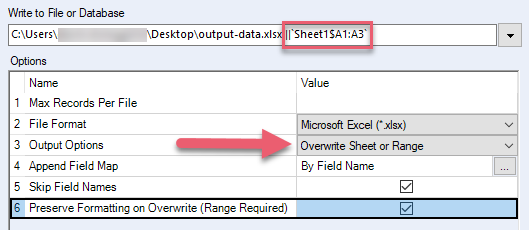 | .xlsx, .xlsm (via Alteryx .xlsx driver) |
Projection | Define the output project. By default, Projection is blank and outputs to WGS 84. See Projection Support. | .mid, .mif, .tab, .shp, .oci, .mdb |
Quote Output Field | Choose an option for quoting output fields: Auto: Insert quotes around fields that have a single or double quote, and around fields that contain delimiters. Always: Insert quotes around each field. Never: Don't insert quotes. | |
Read Spatial Objects as Centroids | For data with polygon objects, select to use the polygon's centroid as the spatial object. | .mdb*, .tab, .oci, .sdf, .shp, .geo, .kml, .mid, .mif |
Record Limit | Select to limit the records read from input data. If 0, all records are returned. If -1, only the metadata is returned. | |
Return Child Values | Selected by default to output the child values of the root element or a specified XML Child Element Name. See Reading XML. | .xml |
Return Outer XML | Select to output the format of the XML tag of a specified XML Child Element Name. Deselect to output the format of the root element's children. See Reading XML. | .xml |
Return Root Element | Select to output the parent element that encloses all other elements. See Reading XML. | .xml |
Run PreSQL on tool configuration | Selected by default, this option runs preSQL statements when a tool is brought into a workflow. Deselect the check box to run preSQL statements when the workflow is executed instead. | |
Save Source and Description | Selected by default, this option includes source and description data in the metainfo. Deselect the option to exclude source and description data. | |
Search SubDirs | Use to bring in multiple inputs if data files are in a sub-directory and contain the same structure, field names, length, and data types. | |
Session Character Set | By default, the Teradata bulk loader uses UTF8 encoding, which does not fit the extended Latin character set Teradata uses for diacritical characters. A new option (Session Character Set) was added to the Output tool to allow changing the character set. | Teradata ODBC |
Size of Bulk Load Chunks (1 MB to 102400 MB) | The size of bulk load chunks to write. The default setting is 128 MB. | |
Skip Field Names | When checked, this option allows you to write data only in a sheet or a range. | .xlsx, .xlsm |
Spatial Object Field | Define the spatial object to include in the output. Spatial files can only contain one spatial object per record. Alteryx does not support reading or writing multiple geometry types in a single file. | .mdb*, .tab, .oci, .sdf, .shp, .geo, .kml, .mid, .mif |
Show Transaction Message | Select to display, in the Results window, a message for each transaction. Each message reports the sum of records written up to that transaction. | |
Start Data Import on Line | Define a line number on which to start reading data. By default, it begins on Line 1. | .csv, .xlsx |
Support Null Values | Select to output a .avro file with Null values. This output option unions fields with a null branch and a value branch. If the Alteryx value is Null, the output will use the null branch; otherwise, the value branch is used. If this option is not selected, all output fields will write as their native .avro types (non-union). Alteryx fields that are Null are written as their default value. Use the Formula tool to handle Null values with 'known' values so that the values can be read in Hadoop. | .avro |
Table Type | Use to select system default, column, or row table stores. The table stores represent how the data is stored. The system default honors the table store of the underlying database. You will notice a decline in performance when you create a column store table versus a row store table. | SAP HANA ODBC |
Table/Field Name SQL Style | Select Quoted or None. Quoted uses the Quote Identifier for the database type. | .oci, OLEDB, OBDC, |
Table or Query | If data contains multiple tables, define the table to input, or select to create a query. See Choose Table or Specify Query Window. | |
Take File Name From Field | Select an option to write a separate file for each value of a particular field: Append Suffix to File/Table Name: Appends selected field name to the end of the table name. Prepend Prefix to File/Table Name: Prepends selected field name to the beginning of the table name. Change File Name: Changes the file name to the select field name. Change Entire File Path: Changes the file name to the selected field name that contains a full path. | all output formats |
Transaction Size | Define the number of records at a time to write to a database. Records are committed in batches lesser than 655360 bytes or transaction size * record size. Record size is calculated based on the field sizes specified in the workflow output. If the record size is greater than 655360 bytes, the transaction size is automatically set to 1. For updates, transaction size is always 1. By default, transaction size is 0, meaning all records. Set records to at least 1000 because the database creates a temporary log file for each transaction which could quickly fill up temporary space. | .oci, OLEDB, ODBC |
Treat Errors as Warnings | Select to input data with records that do not conform to the data structure. Typically errors cause the input to fail; this option prevents input failure by treating errors as warnings. | |
Trim White Space | Use the selected .flat file (default), or override the setting. | .flat |
What Kind of Line Ends to Use | Use the selected .flat file (default), or override the setting. | .flat |
Write BOM | Select to include the byte order mark (BOM) in the output, or deselect to output without a byte order mark. | .csv |