Las opciones de configuración varían según el formato de archivo o la conexión de bases de datos que utilices para ingresar o exportar datos de salida. Selecciona las opciones de formato de archivo en estas herramientas: Herramienta Datos de entrada , Herramienta Datos de salida , Herramienta Conexión En-BD , Herramienta Entrada de flujo de datos , Herramienta Escribir datos en-BD .
Opción | Descripción | Formatos de archivo |
|---|---|---|
Permitir la extracción de archivos >2 GB | Selecciona esta opción para permitir que Alteryx extraiga un archivo de más de 2 GB. Consulta Compatibilidad de archivos Zip y Compatibilidad de archivos Gzip . | .zip, *.gz, *.tgz |
Permitir acceso de escritura compartido | Selecciona esta opción para leer un archivo abierto que puede estar en proceso de actualización. Esta opción está destinada a la lectura de registros web. | |
Anexar a tabla ya existente | Selecciona esta opción para agregar registros a una tabla existente. | .dbase, .sdf |
Anexar mapa de campos | Selecciona esta opción para agregar campos y establece cómo los campos de salida se asignarán a los campos de la tabla OleDB. | .mdb, .xls, .accdb, ODBC, OLEDB |
Página de código | Selecciona una página de código para convertir texto dentro de los datos de entrada o salida. Consulta Páginas de código . | .csv, .dbf, .flat, .json, .mid, .mif, .tab, .shp |
Crear campos Int32 como binarios | Selecciona esta opción para crear todos los campos Int32 como valores binarios de 32 bits (4 bytes) en la base de datos en lugar del formato de texto predeterminado de 11 caracteres. Esta opción no es compatible con todos los lectores DBF. | .dbase |
Delimitador | Selecciona el delimitador de campo en los datos. Utiliza \0 para leer o escribir un archivo de texto sin delimitador. Utiliza 0 si los datos contienen dos o más delimitadores para forzar a Alteryx Designer a leer los datos como texto sin formato. Utiliza la Herramienta RegEx en modo Tokenize para analizar los datos. | .csv, .txt |
Archivo de descripción o datos | Define el nombre de archivo de un archivo .flat utilizado como archivo de diseño. | .flat |
No mostrar el % completado | Selecciona esta opción para desactivar un informe de estado del progreso de lectura de archivos; esto acelera el tiempo de lectura. | |
Habilitar compresión (Desinflar) | Selecciona para mostrar un archivo .avro comprimido. El algoritmo deflate (similar al gzip) se utiliza y debe ser compatible con otras herramientas con capacidad Avro, como Hive. La compresión aumenta el tiempo de salida, pero con archivos más grandes, reducirá el tiempo de red. | .avro |
Habilita la compatibilidad con tablas de archivos de SQL Server | Selecciona esta opción para escribir un archivo de Excel en un FileTable de Microsoft SQL Server | .xlsx |
Expandir etiquetas de valores | Lee y aplica etiquetas de valor (clave) a los datos. Esta opción está seleccionada de forma predeterminada para los archivos SPSS y SAS. Consulta Formatos de archivo compatibles con Stat Transfer . Si no se selecciona esta opción, solo se muestra la clave de valor. | .spss, .sas |
Longitud del campo | Define la longitud máxima del campo en los datos de entrada. | |
Formato de archivo | Selecciona el formato de archivo de datos. | todos los formatos |
Archivo en almacenamiento | Cambia el archivo (o archivos) a entrada. Consulta Compatibilidad de archivos Zip . | .zip |
La primera fila contiene datos | Selecciona esta opción si la primera línea se debe tratar como datos, no como encabezado. | .xlsx |
La primera fila contiene nombres de campos | Selecciona esta opción si deseas que la primera línea se trate como encabezado. | .csv |
Forzar compatibilidad con SQL WChar | Selecciona esta opción para permitir que las columnas de caracteres se traten como SQL_WCHAR, SQL_WVARCHAR, or SQL_WLONGVARCHAR. | .oci, unicode.txt |
Si se permiten líneas largas | Utiliza el archivo .flat seleccionado (por defecto), o anula la configuración. | .flat |
Si se permiten líneas cortas | Utiliza el archivo .flat seleccionado (por defecto), o anula la configuración. | .flat |
Ignorar delimitadores entre | Seleccionar una opción: Comillas : ignorar delimitadores entre comillas. Comillas simples : ignorar delimitadores entre comillas simples. Auto : ignorar delimitadores autodetectados. Ninguno : no ignorar los delimitadores. | |
Ignorar errores de XML y continuar | Ignora el formato XML incorrecto y continúa ejecutando el flujo de trabajo. Consulta Lectura XML . | .xml |
Estilo de final de línea | Define el carácter o la secuencia de caracteres que indican el final de una línea de texto. | .csv, .flat |
Cantidad máxima de registros por archivo | Define el número de registros que se desea enviar a un solo archivo. Si los datos contienen más registros, se crean varios archivos y se nombran secuencialmente. | todos los formatos |
Ningún índice espacial | Selecciona esta opción si deseas desactivar el índice espacial. Utiliza esta opción solo cuando escribas archivos temporales de gran tamaño que no se utilizarán en operaciones espaciales. Con esta opción, se escriben archivos más pequeños y más rápido. | .yxdb |
Emitir todos los campos como cadenas | Selecciona esta opción para convertir los campos de entrada al tipo de dato de cadena; esto evita los errores de conversión si el tipo de dato es incorrecto en los archivos .dbf. | .dbf |
Generar campo con el nombre de archivo | Selecciona esta opción para agregar un campo con el nombre del archivo o la ruta de acceso del archivo a cada registro. | |
Opciones de salida | Selecciona una opción de salida: Crear nueva hoja : crea una nueva hoja, pero no sobrescribe una hoja existente. Anexar a hoja existente : anexa datos a una hoja existente para que la salida contenga datos nuevos y antiguos. Sobrescribir hoja o rango : elimina los datos de la hoja o rango seleccionado y escribe los datos en la hoja o rango con el nombre seleccionado. No utilices la opción anterior si el archivo de Excel contiene fórmulas, tablas, gráficos e imágenes, ya que estos elementos pueden dañarse. Sobrescribir archivo (Eliminar) : elimina el archivo existente y crea un archivo nuevo. | .xlsx, .xlsm (mediante Alteryx .xlsx driver) |
Opciones de salida | Selecciona una opción de salida: Crear nueva tabla : crea una nueva tabla, pero no sobrescribe una tabla existente. Agregar a tabla existente : Agrega datos a una tabla existente de modo que la salida conste de Registros antes y Registros después. Eliminar datos y anexar : elimina todos los registros originales de la tabla y anexa los datos a la tabla existente. Sobrescribir tabla (descartar) : descarta la tabla existente y crea una nueva. | .accdb, .mdb, .tde, .xls, .xlsx (mediante legacy .xlsx driver), .oci, OLEDB, ODBC |
Opciones de salida | Seleccionar una opción: Actualizar: Advertir en caso de falla : actualiza los registros existentes utilizando la salida y advierte si un registro no se pudo actualizar. Actualizar: Generar error en caso de falla : actualiza los registros existentes usando la salida y detiene el procesamiento si un registro no se pudo actualizar. Actualizar, insertar si es nuevo : actualiza los registros existentes utilizando la salida, inserta nuevos registros si no estaban en la tabla de la base de datos y detiene el procesamiento si no se pudo actualizar un registro. El campo de clave principal debe incluirse para que la actualización funcione. Si hay varios registros con la misma clave principal y no se producen otros errores SQL, el nuevo registro actualiza el registro anterior en la base de datos. Utiliza la Herramienta Única para comprobar si hay varias claves principales antes de escribir en la base de datos. | .oci, OLEDB, ODBC |
Sobrescribir tabla ya existente | Seleccionada de forma predeterminada, esta opción sobrescribe un tipo de archivo existente del mismo nombre. | .mdb* |
Analizar el archivo seleccionado como | Cambia el formato en el que se desea analizar el archivo. | .zip |
Analizar valor como cadena | Selecciona esta opción para analizar los datos de salida como una cadena; si no se selecciona, los datos se analizan en función del tipo de dato. | |
Contraseñas | Selecciona cómo se mostrará una contraseña en la ventana de configuración: Ocultar (opción predeterminada), Cifrar para la máquina , Cifrar para el usuario . | |
Instrucción Post Create SQL* | Define una sentencia SQL para ejecutar a través del controlador ODBC/OLEDB después de crear la tabla de salida. | .mdb, .mdb*, .oci, .accdb, ODBC, OLEDB |
Instrucción Pre Create SQL* | Define una sentencia SQL para ejecutar a través del controlador ODBC/OLEDB antes de crear la tabla de salida. | .mdb, .mdb*, .oci, .accdb, ODBC, OLEDB |
Conservar formato al sobrescribir (rango obligatorio) | Conserva el formato de Excel del rango que estás sobrescribiendo. No utilices esta opción si el archivo de Excel contiene fórmulas, tablas, gráficos e imágenes, ya que estos elementos pueden dañarse. Al seleccionar esta opción, también debes hacer lo que se indica a continuación:
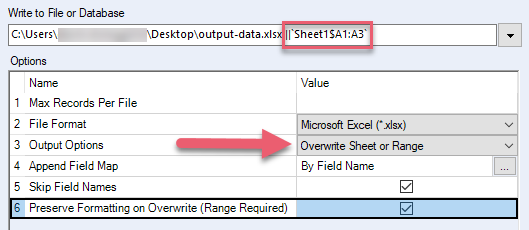 | .xlsx, .xlsm (mediante Alteryx .xlsx driver) |
Proyección | Define el proyecto de salida. De forma predeterminada, la proyección está en blanco y se envía a WGS 84. Consulta Admisión de proyección . | .mid, .mif, .tab, .shp, .oci, .mdb |
Encerrar campos de salida entre comillas | Elige una opción para los campos de salida entre comillas: Automático : inserta comillas alrededor de los campos que tienen comillas simples o dobles y alrededor de los campos que contienen delimitadores. Siempre : inserta comillas alrededor de cada campo. Nunca : no inserta comillas. | |
Leer objetos espaciales como centroides | Para los datos con objetos poligonales, selecciona esta opción para utilizar el centroide poligonal como objeto espacial. | .mdb*, .tab, .oci, .sdf, .shp, .geo, .kml, .mid, .mif |
Límite de registros | Selecciona esta opción para limitar los registros leídos de los datos de entrada. Si es 0, se devuelven todos los registros. Si es -1, solo se devuelven los metadatos. | |
Devolver valores de elementos secundarios | Seleccionado de forma predeterminada para mostrar los valores secundarios del elemento raíz o un nombre de elemento secundario XML especificado. Consulta Lectura XML . | .xml |
Devolver XML externo | Selecciona esta opción para mostrar el formato de la etiqueta XML de un nombre de elemento secundario XML especificado. Anula la selección para mostrar el formato de los elementos secundarios del elemento raíz. Consulta Lectura XML . | .xml |
Devolver elemento raíz | Selecciona esta opción para mostrar el elemento principal que encierra todos los demás elementos. Consulta Lectura XML . | .xml |
Ejecuta PreSQL en la configuración de la herramienta | Seleccionada de forma predeterminada, esta opción ejecuta sentencias preSQL cuando una herramienta se introduce en un flujo de trabajo. Anula la selección de la casilla de verificación para ejecutar sentencias preSQL cuando se ejecute el flujo de trabajo. | |
Guardar origen y descripción | Esta opción, que se selecciona de forma predeterminada, incluye los datos de origen y descripción en la metainformación. Anula la selección de la opción a fin de excluir los datos de origen y de descripción. | |
Buscar en subdirectorios | Utiliza esta opción para introducir múltiples entradas si los archivos de datos están en un subdirectorio y contienen la misma estructura, nombres de campo, longitud y tipos de datos. | |
Conjunto de caracteres de sesión | De forma predeterminada, el cargador masivo de Teradata utiliza codificación UTF8, que no se ajusta al conjunto de caracteres latinos extendido que Teradata utiliza para caracteres diacríticos. Se agregó una nueva opción (Conjunto de caracteres de sesión) a la herramienta Datos de salida para permitir cambiar el conjunto de caracteres. | ODBC de Teradata |
Tamaño de los trozos de carga masiva (de 1 MB a 102 400 MB) | El tamaño de los trozos de carga masiva para escribir. La configuración predeterminada es de 128 MB. | |
Omitir nombres de campos | Cuando está activada, esta opción te permite escribir datos solo en una hoja o en un rango. | .xlsx, .xlsm |
Campo de objeto espacial | Define el objeto espacial que se debe incluir en la salida. Los archivos espaciales solo pueden contener un objeto espacial por registro. Alteryx no admite la lectura o escritura de múltiples tipos de geometría en un solo archivo. | .mdb*, .tab, .oci, .sdf, .shp, .geo, .kml, .mid, .mif |
Mostrar mensaje de transacción | Selecciona esta opción para que se muestre, en la ventana de resultados, un mensaje para cada transacción. Cada mensaje reporta la suma de los registros escritos hasta esa transacción. | |
Comenzar la importación de datos en la línea | Define un número de línea en el que se deba comenzar a leer datos. De forma predeterminada, comienza en la Línea 1. | .csv, .xlsx |
Admitir valores nulos | Selecciona esta opción para que se muestre un archivo .avro con valores nulos. Esta opción de salida apila campos con una rama nula y una rama de valor. Si el valor Alteryx es nulo, la salida usará la rama nula; de lo contrario, se usará la rama de valor. Si esta opción no está seleccionada, todos los campos de salida se escribirán como sus tipos .avro nativos (sin apilarse). Los campos Alteryx que son nulos se escriben como su valor predeterminado. Utiliza la Herramienta Fórmula para manejar valores nulos con valores “conocidos” a fin de que los valores se puedan leer en Hadoop. | .avro |
Tipo de tabla | Utiliza esta opción para seleccionar los almacenamientos predeterminados del sistema, de la columna o de la tabla de filas. Los almacenamientos de tablas representan cómo se almacenan los datos. El sistema por defecto honra el almacenamiento de tablas de la base de datos subyacente. Notarás una disminución en el rendimiento cuando crees una tabla de almacenamiento de columnas en comparación con una tabla de almacenamiento de filas. | ODBC de SAP HANA |
Estilo SQL de nombre de tabla/campo | Selecciona Entre comillas o Ninguno . Entre comillas utiliza el identificador de comillas para el tipo de base de datos. | .oci, OLEDB, OBDC, |
Tabla o consulta | Si los datos contienen varias tablas, define la tabla para ingresar o selecciona esta opción para crear una consulta. Consulta Elegir tabla o especificar ventana de consulta . | |
Tomar nombre de archivo del campo | Selecciona una opción para escribir un archivo separado para cada valor de un campo en particular: Anexar sufijo al nombre de archivo y/o de la tabla : anexa el nombre de campo seleccionado al final del nombre de la tabla. Anteponer prefijo al nombre de archivo y/o de la tabla : antepone el nombre del campo seleccionado al principio del nombre de la tabla. Cambiar el nombre del archivo : cambia el nombre del archivo al nombre del campo seleccionado. Cambiar ruta completa del archivo : cambia el nombre del archivo al nombre del campo seleccionado que contiene una ruta completa. | todos los formatos de salida |
Tamaño de la transacción | Define el número de registros que se pueden escribir a la vez en una base de datos. Los registros se cometen en lotes menores a 655 360 bytes o tamaño de transacción * tamaño de registro. El tamaño del registro se calcula en función de los tamaños de campo especificados en la salida del flujo de trabajo. Si el tamaño del registro es superior a 655 360 bytes, el tamaño de la transacción se establece automáticamente en 1. Para las actualizaciones, el tamaño de la transacción es siempre 1. Por defecto, el tamaño de la transacción es 0, es decir, todos los registros. Establece los registros en al menos 1000 porque la base de datos crea un archivo de registro temporal para cada transacción que podría llenar rápidamente el espacio temporal. | .oci, OLEDB, ODBC |
Tratar errores como advertencias | Selecciona esta opción para ingresar datos con registros que no se ajustan a la estructura de datos. Normalmente, los errores provocan que la entrada falle; esta opción previene el fallo de entrada, ya que trata los errores como advertencias. | |
Recortar espacio en blanco | Utiliza el archivo .flat seleccionado (por defecto), o anula la configuración. | .flat |
Qué tipo de extremo de línea se debe usar | Utiliza el archivo .flat seleccionado (por defecto), o anula la configuración. | .flat |
Escribir BOM | Selecciona esta opción para incluir la marca de orden de bytes (BOM) en la salida o anula la selección para generar la salida sin una marca de orden de bytes. | .csv |