データの入力または出力に使用するファイル形式またはデータベース接続に応じて、構成オプションは異なります。入力データツール、出力データツール、接続In-DBツール、データストリーム入力ツール、データ書込In-DBツール でファイル形式のオプションを選択します。
オプション | 説明 | ファイル形式 |
|---|---|---|
>2 GBのファイルの抽出を許可する | Alteryxが2 GBを超えるファイルを抽出できるようにする場合に選択します。「Zipファイルサポート」および「Gzipファイルサポート」を参照してください。 | .zip、*.gz、*.tgz |
共有書き込みアクセスを許可する | 更新されている可能性のある開いているファイルを読み込む場合に選択します。このオプションはWebログを読むためのものです。 | |
既存のテーブルに付加する | 既存のテーブルにレコードを付加する場合に選択します。 | .dbase、.sdf |
フィールドマップを追加 | フィールドを付加し、出力フィールドをOleDBテーブルのフィールドにマップする方法を設定する場合に選択します。 | .mdb、.xls、.accdb、ODBC、OLEDB |
コードページ | 入力データまたは出力データ内のテキストを変換するコードページを選択します。「コードページ」を参照してください。 | .csv、.dbf、.flat、.json、.mid、.mif、.tab、.shp |
バイナリとして Int32 フィールドを作成する | すべてのInt32フィールドを既定の11文字のテキスト形式ではなく、データベースの32ビット(4バイト)バイナリ値として作成する場合に選択します。このオプションは、すべてのDBFリーダーでサポートされているわけではありません。 | .dbase |
区切り文字 | データのフィールド区切り文字を選択します。 区切り文字なしのテキストファイルを読み書きするには、\ 0を使用します。データに2つ以上の区切り文字が含まれている場合に、Designerにデータをフラットテキストとして読み込ませるには、0を使用します。 トークン化モードで 正規表現ツール を使用してデータを解析します。 | .csv、.txt |
説明またはデータファイル | レイアウトファイルとして使用する.flatファイルのファイル名を定義します。 | .flat |
%完了を表示しない | ファイルの読み込み進捗状況のステータスレポートを無効にする場合に選択します。これにより、読み取り時間が短縮されます。 | |
圧縮を有効にする (Deflate) | 圧縮された.avroファイルを出力する場合に選択します。 デフレートアルゴリズム(gzipに似ています)が使用され、Hiveなどの他のAvro対応ツールでサポートされる必要があります。圧縮すると出力時間は長くなりますが、ファイルが大きくなるとネットワーク時間が短縮されます。 | .avro |
SQL Server FileTable Supportを有効にする | ExcelファイルをMicrosoft SQL Server FileTableに書き込む場合に選択します。 | .xlsx |
値ラベルを展開する | 値ラベル(キー)を読み取り、データに適用します。このオプションは、SPSSおよびSASファイルではデフォルトで選択されています。「Stat/Transferでサポートされているファイル形式」を参照してください。 選択されていない場合、値キーのみが表示されます。 | .spss、.sas |
フィールド長 | 入力データの最大フィールド長を定義します。 | |
ファイル形式 | データファイル形式を選択します。 | すべての形式 |
アーカイブのファイル | 入力するファイルを変更します。「Zipファイルサポート」を参照してください。 | .zip |
最初の行はデータを含む | 最初の行をヘッダーではなくデータとして扱う場合に選択します。 | .xlsx |
最初の行はフィールド名を含む | 最初の行がヘッダーとして処理される場合に選択します。 | .csv |
SQL WChar サポートを強制する | 文字列をSQL_WCHAR、SQL_WVARCHAR、またはSQL_WLONGVARCHARとして処理される場合に選択します。 | .oci、unicode.txt |
長い行が許可されている場合 | 選択した.flatファイル(デフォルト)を使用するか、設定を無効にします。 | .flat |
短い行が許可される場合 | 選択した.flatファイル(デフォルト)を使用するか、設定を無効にします。 | .flat |
次の区切り記号を無視する | オプションを選択: 引用符: 引用符内の区切り記号を無視します。 一重引用符: 一重引用符内の区切り記号を無視します。 自動: 自動的に検出された区切り記号を無視します。 なし: 区切り記号を無視しません。 | |
XML エラーを無視して続行する | 間違ったXML形式を無視して、ワークフローの実行を継続します。「XMLを読む」を参照してください。 | .xml |
行終了スタイル | 文字または文字列を定義して、テキスト行の終わりを示します。 | .csv、.flat |
ファイルごとの最大レコード数 | 1つのファイルに出力するレコードの数を定義します。データにさらにレコードが含まれている場合、複数のファイルが作成され、順番に名前が付けられます。 | すべての形式 |
空間インデックスなし | 空間インデックスをオフにする場合に選択します。 このオプションは、空間操作で使用されない大きな一時ファイルを書き込む場合にのみ使用してください。このオプションは、ファイルが小さいほど高速に書き込みを行います。 | .yxdb |
すべてのフィールドを文字列として出力する | 着信フィールドを文字列データ型に変換する場合に選択します。これは、データ型が.dbfファイルで間違っている場合、変換エラーをバイパスします。 | .dbf |
ファイル名をフィールドとして出力する | ファイル名またはファイルパスを含むフィールドを各レコードに付加する場合に選択します。 | |
出力オプション | 出力オプションを選択する: 新しいシートを作成する: 新しいシートを作成しますが、既存のシートを上書きしません 既存のシートに追加する: 既存のシートにデータを付加して、出力が新しいデータと前のデータで構成されるようにします。 シートまたは範囲を上書きする: 選択したシートまたは範囲のデータを削除し、選択した名前でシートまたは範囲にデータを書き込みます。 上記のオプションは、Excelファイルに数式、表、グラフ、画像が含まれている場合は使用しないでください。これらのアイテムが壊れる可能性があります。 ファイルを上書きする(削除): 既存のファイルを削除し、新しいファイルを作成します。 | .xlsx、.xlsm(Alteryx .xlsxドライバ経由) |
出力オプション | 出力オプションを選択する: 新しいテーブルを作成する: 新しいテーブルを作成しますが、既存のテーブルを上書きしません。 既存のものを追加する: 出力が前レコードと後レコードで構成されるように、既存のテーブルにデータを付加します。 データの削除と付加: テーブルから元のレコードをすべて削除し、既存のテーブルにデータを付加します。 テーブルを上書きする(ドロップ): 既存のテーブルをドロップし、新しいテーブルを作成します。 | .accdb、.mdb、.tde、.xls、.xlsx(従来の.xlsxドライバを使用)、.oci、OLEDB、ODBC |
出力オプション | オプションを選択: 更新:、失敗時の警告: 出力を使用して既存のレコードを更新し、レコードを更新できなかった場合は警告します 更新、失敗時のエラー: 出力を使用して既存のレコードを更新し、レコードを更新できなかった場合は、処理を停止します。 更新、新しい場合挿入: 出力を使用して既存のレコードを更新し、それらがデータベーステーブルになかった場合は新しいレコードを挿入し、レコードを更新できなかった場合は処理を停止します。 更新を機能させるには、プライマリキーフィールドが含まれている必要があります。 同じ主キーを持つ複数のレコードが存在し、他のSQLエラーが発生しない場合、新しいレコードはデータベース内の古いレコードを更新します。ユニークツール を使用して、データベースに書き込む前に複数のプライマリキーをチェックします。 | .oci、OLEDB、ODBC |
既存のテーブルを上書きする | 既定で選択されたこのオプションは、同じ名前の既存のファイルタイプを上書きします。 | .mdb * |
選択したファイルを次の形式として解析 | ファイルを解析する形式を変更します。 | .zip |
値を文字列として解析する | 出力データを文字列として解析する場合に選択します。選択されていない場合、データはデータ型に基づいて解析されます。 | |
パスワード | 設定ウィンドウでのパスワードの表示方法を選択します。[非表示(既定)]、[マシン用の暗号化]、[ユーザー用に暗号化する] があります。 | |
SQLステートメントの作成を投稿する | 出力テーブルの作成後にODBC / OLEDBドライバを介して実行するSQLステートメントを定義します。 | .mdb、.mdb *、.oci、.accdb、ODBC、OLEDB |
SQL*ステートメントの事前作成 | 出力テーブルを作成する前に、ODBC / OLEDBドライバを介して実行するSQLステートメントを定義します。 | .mdb、.mdb *、.oci、.accdb、ODBC、OLEDB |
上書きのフォーマットを保持する (範囲が必要) | 上書きする範囲のExcelフォーマットを保持します。 このオプションは、Excelファイルに数式、表、グラフ、画像が含まれている場合は使用しないでください。これらのアイテムが壊れる可能性があります。 このオプションを選択する場合は、次の操作も行う必要があります。
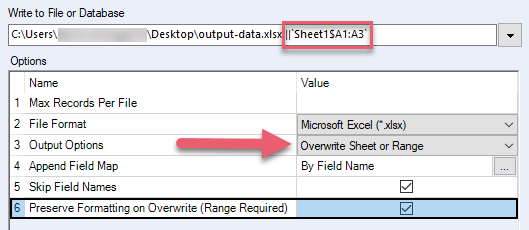 | .xlsx、.xlsm(Alteryx .xlsxドライバ経由) |
投影法 | 出力プロジェクトを定義します。デフォルトで、投影は空白で、WGS 84に出力されます。「プロジェクションサポート」を参照してください。 | .mid、.mif、.tab、.shp、.oci、.mdb |
出力フィールドを引用 | 出力フィールドを引用するためのオプションを選択します。 自動: 一重引用符、二重引用符、または区切り記号を含むフィールドの前後に引用符を挿入します。 常時: 各フィールドの前後に引用符を挿入します。 挿入しない: 引用符を挿入しません。 | |
空間オブジェクトを重心として読み込む | ポリゴンオブジェクトのデータの場合は、ポリゴンの重心を空間オブジェクトとして使用する場合に選択します。 | .mdb *、.tab、.oci、.sdf、.shp、.geo、.kml、.mid、.mif |
レコード制限 | 入力データから読み込まれたレコードを制限する場合に選択します。0の場合、すべてのレコードが返されます。-1の場合、メタデータのみが返されます。 | |
子要素の値を返す | ルート要素または指定された [XML子要素の名前] の子値を出力するように既定で選択されています 。「XMLを読む」を参照してください。 | .xml |
外部 XML を返す | 指定した [XML子要素の名前] のXMLタグの形式を出力する場合に選択します。ルート要素の子の形式を出力する場合は、選択を解除します。「XMLを読む」を参照してください。 | .xml |
ルート要素を返す | 他のすべての要素を囲む親要素を出力する場合に選択します。「XMLを読む」を参照してください。 | .xml |
ツール設定で PreSQL を実行する | 既定で選択されています。このオプションでは、ツールがワークフローに取り込まれるとpreSQLステートメントを実行します。 チェックボックスをオフにすると、ワークフローが実行された際に、preSQLステートメントが実行されます。 | |
ソースと説明を保存 | デフォルトで選択されているこのオプションでは、メタ情報にソースと説明のデータが含まれています。ソースおよび説明データを除外するオプションの選択を解除します。 | |
サブディレクトリを検索する | データファイルがサブディレクトリにあり、同じ構造体、フィールド名、長さ、およびデータ型を含む場合は、複数の入力を取り込むために使用します。 | |
セッション文字セット | 既定では、TeradataバルクローダーはUTF8エンコーディングを使用しますが、UTF8エンコーディングは、Teradataが発音区別符号付き文字に使用する拡張ラテン文字セットには適合しません。出力ツールに新しいオプション(セッション文字セット)が追加され、文字セットを変更できるようになりました。 | Teradata ODBC |
バルクロードチャンクのサイズ (1MB~102400 MB) | 書き込むバルクロードチャンクのサイズ。既定の設定は128 MBです。 | |
フィールド名をスキップする | このオプションをオンにすると、シートまたは範囲にのみデータを書き込むことができます。 | .xlsx、.xlsm |
空間オブジェクトフィールド | 出力に含める空間オブジェクトを定義します。空間ファイルには、レコードごとに1つの空間オブジェクトしか含めることができません。 Alteryxでは、1つのファイルで複数のジオメトリタイプを読み書きすることはできません。 | .mdb *、.tab、.oci、.sdf、.shp、.geo、.kml、.mid、.mif |
トランザクションメッセージを表示する | 「結果」ウィンドウに各トランザクションのメッセージを表示する場合に選択します。各メッセージは、そのトランザクションまで書き込まれたレコードの合計を報告します。 | |
データインポートの開始行 | データの読み込みを開始する行番号を定義します。デフォルトで、行1から始まります。 | .csv、.xlsx |
Null 値をサポートする | Null値を持つ.avroファイルを出力する場合に選択します。 この出力オプションは、nullブランチと値のブランチを持つフィールドを結合します。Alteryxの値がNullの場合、出力にはnullブランチが使用されます。それ以外の場合は、値ブランチが使用されます。 このオプションが選択されていない場合、すべての出力フィールドはネイティブの.avroタイプ(非ユニオン)として書き込まれます。NullのAlteryxフィールドはデフォルト値として書き込まれます。 フォーミュラツール を使用すると、「既知の」値を持つNULL値を処理して、値をHadoopに読み込めるようになります。 | .avro |
テーブルタイプ | システム既定、列、行テーブルストアの選択に使用します。 テーブルストアでは、データの格納方法が表示されます。システム既定では、基盤となるデータベースのテーブルストアが優先されます。 列ストアテーブルを作成すると、行ストアテーブルを作成するときに比べて、パフォーマンスが低下します。 | SAP HANA ODBC |
テーブル/フィールド名SQLスタイル | [引用符付き] または [なし] を選択します。Quotedは、データベースタイプの引用識別子を使用します。 | .oci、OLEDB、OBDC、 |
テーブルまたはクエリ | データに複数のテーブルが含まれている場合は、入力するテーブルを定義するか、クエリを作成することを選択します。テーブルの選択またはクエリウィンドウを指定 を参照してください。 | |
フィールドからファイル名を取得する | 特定のフィールドの値ごとに別個のファイルを書き込むオプションを選択します。 ファイル/テーブル名に接尾辞を追加する: 選択したフィールド名をテーブル名の末尾に付加します。 ファイル/テーブル名に接頭辞を追加する: 選択したフィールド名をテーブル名の前に付加します。 ファイル名を変更する: ファイル名を選択したフィールド名に変更します。 ファイルパス全体を変更する: ファイル名をフルパスを含む選択したフィールド名に変更します。 | すべての出力形式 |
トランザクションサイズ | データベースに書き込むレコードの数を一度に定義します。 レコードは、655,360バイトまたはトランザクションサイズ*レコードサイズ未満のバッチでコミットされます。レコードサイズは、ワークフロー出力で指定されたフィールドサイズに基づいて計算されます。レコードサイズが655,360バイトを超えると、トランザクションサイズは自動的に1に設定されます。更新の場合、トランザクションサイズは常に1です。 デフォルトで、トランザクションサイズは0で、すべてのレコードを意味します。データベースは各トランザクションの一時ログファイルを作成して一時的なスペースをすぐに埋める可能性があるため、レコード数は1000以上に設定してください。 | .oci、OLEDB、ODBC |
読み込みエラーを警告として扱う | データ構造に適合しないレコードにデータを入力する場合に選択します。通常、エラーは入力を失敗させます。このオプションは、エラーを警告として扱うことで入力エラーを防止します。 | |
空白を除去する | 選択した.flatファイル(デフォルト)を使用するか、設定を無効にします。 | .flat |
使用する行の種類 | 選択した.flatファイル(デフォルト)を使用するか、設定を無効にします。 | .flat |
BOM を書き込む | 出力にバイトオーダーマーク(BOM)を含める場合は選択し、バイトオーダーマークなしで出力する場合は選択を解除します。 | .csv |