
Visão geral do recurso Na base de dados
O processamento no banco de dados permite a mesclagem e a análise de grandes conjuntos de dados sem mover os dados de um banco de dados, o que pode fornecer melhorias significativas de desempenho em relação aos métodos de análise tradicionais que requerem que os dados sejam movidos para um ambiente para processamento.
Executar a análise no banco de dados pode economizar tempo de processamento. Usando o Alteryx designer como a interface, os fluxos de trabalho no banco de dados se integram aos fluxos de trabalho padrão para análise e mesclagem de dados adicionais.
Atualmente, não há suporte para objetos espaciais com ferramentas no banco de dados.
- O processamento no banco de dados requer Alteryx de 64 bits com drivers de banco de dados de 64 bits.
- Para executar fluxos de trabalho no servidor Alteryx, o driver ODBC deve ser configurado como um DSN do sistema. No processamento do banco de dados, o tipo de conexão deve ser "System", além da conexão ODBC que está sendo configurada como DSN do sistema.
| Suporte de banco de dados | Suporte de previsão no banco de dados |
|---|---|
| Amazon Redshift | |
| Apache Spark ODBC | |
| Cloudera Impala | |
| Databricks | |
| EXASOL | |
| Hive | |
| HP Vertica | |
| IBM Netezza | |
| Microsoft Analytics Platform System | |
| Banco de Dados SQL do Microsoft Azure | |
| SQL Data Warehouse do Microsoft Azure | |
| Microsoft SQL Server 2008, 2012, 2014, 2016 | Sim (2016) |
|
|
|
| Oracle | Sim |
| Pivotal Greenplum | |
| PostgreSQL | |
| SAP Hana | |
| Snowflake | |
| Teradata | Sim |
Veja Fontes de dados e formatos de arquivo compatíveis para a lista completa de plataformas de dados suportadas pelo Alteryx.
Veja Análise de dados preditiva para obter mais informações sobre o suporte de banco de dados preditivo.
| Nome da ferramenta | Descrição da ferramenta | |
|---|---|---|
|
|
Procurar ferramenta em-dB | Revise seus dados em qualquer ponto em um fluxo de trabalho in-DB. Nota: cada pesquisa em-dB dispara uma consulta de banco de dados e pode afetar o desempenho. |
|
|
Ferramenta Conectar na BD | Estabeleça uma conexão de banco de dados para um fluxo de trabalho in-DB. |
|
|
Fluxo de trabalho na ferramenta | Trazer dados de um workflow padrão para um workflow In-DB. |
|
|
Ferramenta de fluxo de dados para fora | Transmitir dados de um fluxo de trabalho in-DB para um fluxo de trabalho padrão, com uma opção para classificar os registros. |
|
|
Ferramenta de entrada dinâmica em-dB | Leve em-dB nome de conexão e campos de consulta de um fluxo de dados padrão e inseri-los em um fluxo de dados in-DB. |
|
|
Ferramenta de saída dinâmica em-dB | Gere informações sobre o workflow In-DB a um workflow padrão para In-DB preditivo. |
|
|
Filtrar ferramenta em-dB | Filtrar registros In-DB com um filtro básico ou com uma expressão personalizada usando a linguagem nativa da base de dados (por exemplo, SQL). |
|
|
Ferramenta de fórmula in-DB | Criar ou atualizar campos em um fluxo de dados In-BD com uma expressão usando a linguagem nativa da base de dados (por exemplo, SQL). |
|
|
Juntar-se em-dB Tool | Combine dois fluxos de dados in-DB com base em campos comuns executando uma junção interna ou externa. |
|
|
Ferramenta de entrada de macro em-dB | Crie uma conexão de entrada In-DB em um macro e a preencha com valores de espaço reservado. |
|
|
Ferramenta de saída macro em-dB | Crie uma conexão de saída In-DB em um macro. |
|
|
Ferramenta de amostra em-dB | Limite o fluxo de dados do recurso In-DB a um número ou porcentagem de registros. |
|
|
Selecione a ferramenta Na base de dados | Selecione, desmarque, reordene e renomeie campos em um fluxo de trabalho in-DB. |
|
|
Resuma a ferramenta em-dB | Resuma os dados em-dB agrupando, somando, contando, contando campos distintos e muito mais. A saída contém apenas os resultados do(s) cálculo(s). |
|
|
Transpor ferramenta em-dB | Gire a orientação de uma tabela de dados em um fluxo de trabalho in-DB. Ele transforma os dados para que você possa exibir campos de dados horizontais em um eixo vertical. |
|
|
Ferramenta União em-dB | Combine dois ou mais fluxos de dados na BD com estruturas semelhantes com base nos nomes ou posições dos campos. Na saída, cada coluna conterá os dados de cada entrada. |
|
|
Ferramenta de gravação de dados em-dB | Use um workflow do recurso In-DB para criar ou atualizar uma tabela diretamente na base de dados. |
| Nome da ferramenta | Descrição da ferramenta | |
|---|---|---|
|
|
Ferramenta Modelo impulsionado | A ferramenta de modelo impulsionada fornece modelos de regressão impulsionados generalizados com base nos métodos de aumento de gradiente de Friedman. |
|
|
Ferramenta de árvore de decisão | A ferramenta de árvore de decisão constrói um conjunto de regras If-então Split que otimizam um critério para criar um modelo que prevê uma variável de destino usando uma ou mais variáveis de preditor. |
|
|
Ferramenta do modelo da floresta | A ferramenta de modelo de floresta cria um modelo que constrói um conjunto de modelos de árvore de decisão para prever uma variável de destino com base em uma ou mais variáveis de preditor. |
|
|
Ferramenta de regressão linear | A ferramenta de regressão linear constrói uma função linear para criar um modelo que prevê uma variável de destino com base em uma ou mais variáveis de preditor. |
|
|
Ferramenta de regressão logística | A ferramenta de regressão logística cria um modelo que relaciona uma variável binária de destino (como Sim/Não, passar/falhar) a uma ou mais variáveis do preditor para obter a probabilidade estimada de cada uma das duas respostas possíveis para a variável de destino. |
|
|
Ferramenta Pontuação | A ferramenta Pontuação avalia um modelo e cria um campo de avaliação, ou pontuação, que estima a precisão dos valores previstos pelo modelo. |
Quando uma ferramenta preditiva com suporte de banco de dados é colocada na tela com outra ferramenta em-dB, a ferramenta preditiva muda automaticamente para a versão em-dB. Para alterar manualmente a versão da ferramenta:
- Clique com o botão direito do mouse na ferramenta.
- Aponte para escolher a versão da ferramenta.
- Clique em uma versão diferente da ferramenta.
Veja Análise de dados preditiva para obter mais informações sobre o suporte de banco de dados preditivo.
Como o processamento do fluxo de trabalho no banco de dados ocorre dentro do banco de dados, as ferramentas do banco de dados não são compatíveis com as ferramentas padrão Alteryx. Vários indicadores visuais mostram compatibilidade de conexão.
As ferramentas padrão usam uma âncora de seta verde para conectar-se a outra ferramenta. A conexão é exibida como uma única linha. |
As ferramentas de banco de dados usam uma âncora de banco de dados Blue Square para se conectar a outra ferramenta no banco de dados. A conexão entre duas ferramentas no banco de dados exibe como uma linha dupla. Devido à natureza do processamento do banco de dados, o andamento da conexão não é exibido. |
Para conectar ferramentas padrão a ferramentas de banco de dados, use as ferramentas de entrada e saída dinâmicas ou as ferramentas de fluxo de dados.
Os dados são transmitidos para dentro e fora de um fluxo de trabalho no banco de dados usando as ferramentas fluxo de dados e fluxo de dados para fora, ou conectando-se diretamente a um banco de dados usando a ferramenta Connect in-DB. As ferramentas fluxo de dados em e fluxo de dados para fora usam uma âncora in-DB para se conectar a ferramentas in-DB e uma âncora de fluxo de trabalho padrão para se conectar a ferramentas de fluxo de trabalho padrão.
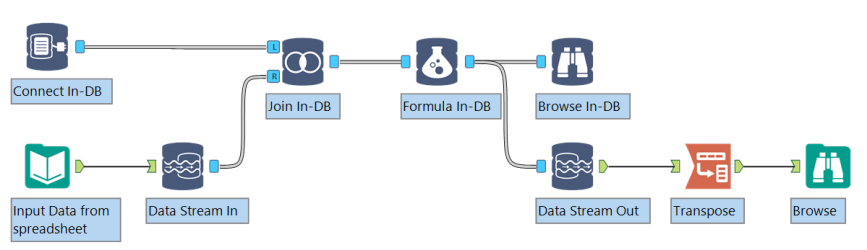
- Defina a conexão com o banco de dados usando a ferramenta Connect in-DB ou use o fluxo de dados na ferramenta para transmitir dados de um fluxo de trabalho padrão para uma tabela temporária no banco de dados.
- Conecte outras ferramentas do banco de dados ao fluxo de trabalho para processar os dados.
- Use a ferramenta gravar dados em-dB para criar ou atualizar uma tabela no banco de dados ou usar a ferramenta fluxo de dados para transmitir os resultados in-DB para um fluxo de trabalho para processamento padrão.
- Execute o fluxo de trabalho para processar os dados na plataforma de dados. Nenhum resultado é retornado ao mecanismo Alteryx até que o fluxo de trabalho completo do banco de dados tenha sido processado.
Processamento de fluxo de trabalho pode demorar mais quando uma grande quantidade de dados é transmitida dentro e fora de um banco de dados. O processamento do banco de dados pode ser usado para acelerar um fluxo de trabalho.
Por exemplo, em um fluxo de trabalho padrão, uma tabela de banco de dados grande é puxada para a memória para ser unida com uma planilha pequena. A maioria do tempo de execução é gasto streaming nos registros de banco de dados. Em um fluxo de trabalho no banco de dados, a planilha pequena é transmitida para o banco de dados, reduzindo substancialmente o tempo de execução.
Os privilégios de leitura são necessários para acessar o banco de dados subjacente.
Os privilégios de gravação são necessários para criar uma tabela no banco de dados.
As tabelas temporárias são excluídas no final da execução. Se Alteryx falhar enquanto o fluxo de dados na ferramenta estiver sendo executado, a próxima vez que um fluxo de trabalho no banco de dados for executado, todos os arquivos temporários criados pelo Alteryx no banco de dados nos três dias anteriores serão limpos.
Para permitir a visibilidade de uma tabela temporária entre as sessões, Alteryx deve criar uma tabela permanente que é eventualmente excluída no final de um fluxo de trabalho. É necessário criar permissões para transmitir dados de um banco de dados e gravar dados em um banco de dados. A exceção é o Microsoft SQL Server.
As regras subjacentes são mantidas durante o processo o mesmo que com as conexões de banco de dados por meio de dados de entrada padrão e ferramentas de dados de saída. Se houver um tempo limite de banco de dados ou se houver um limite para o número de consultas por dia que você pode executar, ele afetará sua conexão com o banco de dados.
Uma instrução SELECT é acionada pela ferramenta Connect in-DB e as consultas adicionais são criadas por ferramentas downstream e aninhadas nessa consulta. A adição de uma das três ferramentas a seguir conclui a consulta e a envia para o banco de dados subjacente: gravar em-dB, fluxo de dados para fora, procurar em-dB.
Você pode inserir sua própria instrução SQL na caixa de consulta para a ferramenta Connect in-DB, que também é incorporada na instrução SELECT.
A consulta SQL para o banco de dados subjacente é acionada em tempo de execução para cada pesquisa em-dB, fluxo de dados para fora ou gravar dados em-dB Tool.
A ferramenta procurar dados em-dB pode ser configurada para armazenar em cache os dados como um arquivo. yxdb quando o fluxo de trabalho é executado.
Depois que os dados forem armazenados em cache, se o fluxo de trabalho for executado novamente e a conexão ou consulta de banco de dados (incluindo o número de registros a serem consultados) não tiver sido alterada, a consulta não será executada novamente. Em vez disso, os dados serão retirados do cache.
Uma mensagem de saída indica se os dados foram ou não armazenados em cache. Clicando no link irá abrir os resultados de dados como um arquivo. yxdb em uma janela separada.
O cache do banco de dados é usado sempre que um fluxo de trabalho é executado novamente sem alterações nas ferramentas upstream. Fazer uma alteração em qualquer ferramenta upstream acionará uma nova consulta e um novo cache será criado.
Não, a opção "procurar primeiro [100] Records" limita o número de registros exibidos na ferramenta procurar em-dB. Outras ferramentas no fluxo de trabalho processarão o número de registros que passam por um determinado ponto.
O campo possui DataType/LOB e não funcionará com a maioria dos operadores de comparação nas ferramentas de filtro ou fórmula. O erro reflete que nenhuma coluna é retornada, mesmo quando os dados coincidem com a comparação. Isso é esperado comportamento com SQL e Oracle, como eles não oferecem suporte a comparações com dados LOB.