Trifacta Classic Experience
Welcome to Designer Cloud, the leading data preparation solution for data volumes of any scale. Use these steps to get started using the Cloud Portal and to find resources to assist you on your way.
Get Started
Upload data: The fastest way to get going is to upload a file to start exploring the Cloud Portal. See Import Basics.
First user: If you are the first user of your project or workspace, you may need to set up the environment for other users, including provisioning access to data.
Introduction to Data Wrangling
Data wrangling, also known as data preparation, is the process of transforming diverse datasets for use in analytics, reporting, and machine learning. Historically, this process has been time-consuming and tedious, but Designer Cloud enables rapid and automated transformation of messy datasources into well-structured data for data engineering uses across the enterprise.
Data preparation has been around since the first time that data needed to be moved, but recent trends have turned this domain for programmers into a mission-critical business process:
The volume and diversity of datasources has exploded. Data is now being read from and written to virtual file systems, data warehouses, data lakes, and REST API endpoints at larger volumes.
Move to the cloud. An enormous volume of data is now stored in multi-cloud and hybrid solutions.
Data access has been democratized.Enterprise data is now reaching all departments in its native form.
While extracting data from systems and loading it into other systems are fairly well-contained processes, the transformation of data remains a difficult and messy bottleneck, complicated by the scale and urgency of modern requirements.
The Designer Cloud approach
Designer Cloud presents a modern solution to the expanding challenge of data transformation. While Designer Cloud can be used to build end-to-end data pipelines, it is also designed to fit seamlessly within existing data pipelines, so that you can gain benefits of the solution without re-engineering your existing flows.
The Alteryx solution represents an evolutionary step for data engineering pipelines:
Datasource location-agnostic. Designer Cloud can work with datastores that are on-premises, on a Hadoop cluster, or in cloud infrastructures.
Work on sampled data. On datasets of any scale, Designer Cloud displays a sample of the data, allowing you to work quickly and iteratively. If you need a different perspective on your data, you can generate a new sample using one of several supported sampling methods. Through representative sampling, you can build your transformations in a more responsive manner.
A visual approach to transformation. The Cloud Portal surfaces issues in the data in a way that is easy to identify and enables deeper exploration. When data of interest is selected, a machine learning-based set of suggested transformations are displayed, allowing you in a few clicks to make the suggested and previewed change. Persistent data quality rules that you define sustain data quality throughout the transformation process.
Integrate with existing data pipelines. Transformation jobs can be launched on-demand or on schedule, using the UI, REST API, or SDKs. Change inputs and outputs as needed.
Data Wrangling Process
The Cloud Portal approach to data wrangling emphasizes easy-to-use visualization and rapid iteration through the browser on sampled data. Below, you can review the stages of building a data pipeline within the Cloud Portal.
Note
Aspects of this process can be managed entirely through REST APIs and SDKs for better integration with your data infrastructure.
Astuce
This PDF contains visual descriptions of common transformations that you can create in the Transformer page. For more information, please visit https://www.trifacta.com/resource-library/data-wrangling-cheat-sheet/.
Connect and Import
Through its robust connectivity framework, the Alteryx One supports connection to a wide range of file-based and relational datasources for import. If you have access to a file or table ready for import, you should be able to import it in the product.
Connections can be created by any provisioned user from within the Cloud Portal to an accessible datastore.
Connection credentials are stored with the connection object in masked form.
Connections can be shared or made public for broader use in the project or workspace.
When datasets are selected for import, a reference object is created to the dataset.
Data is imported only when:
Data is needed for sampling. All transformation within the Cloud Portal occurs on a sample of your data. In this manner, interaction and visual transformation can happen at a much faster pace.
Jobs are executed to generate results across the entire dataset.
Note
Source data is never modified.
Discover
After data has been imported, you can immediately begin exploring. In the Transformer page, you can readily explore your data for scope, trends, and other factors that give meaning to it. In your data pipeline, the Transformer page is where domain expertise in the data can be applied to determine what needs to be done with it.
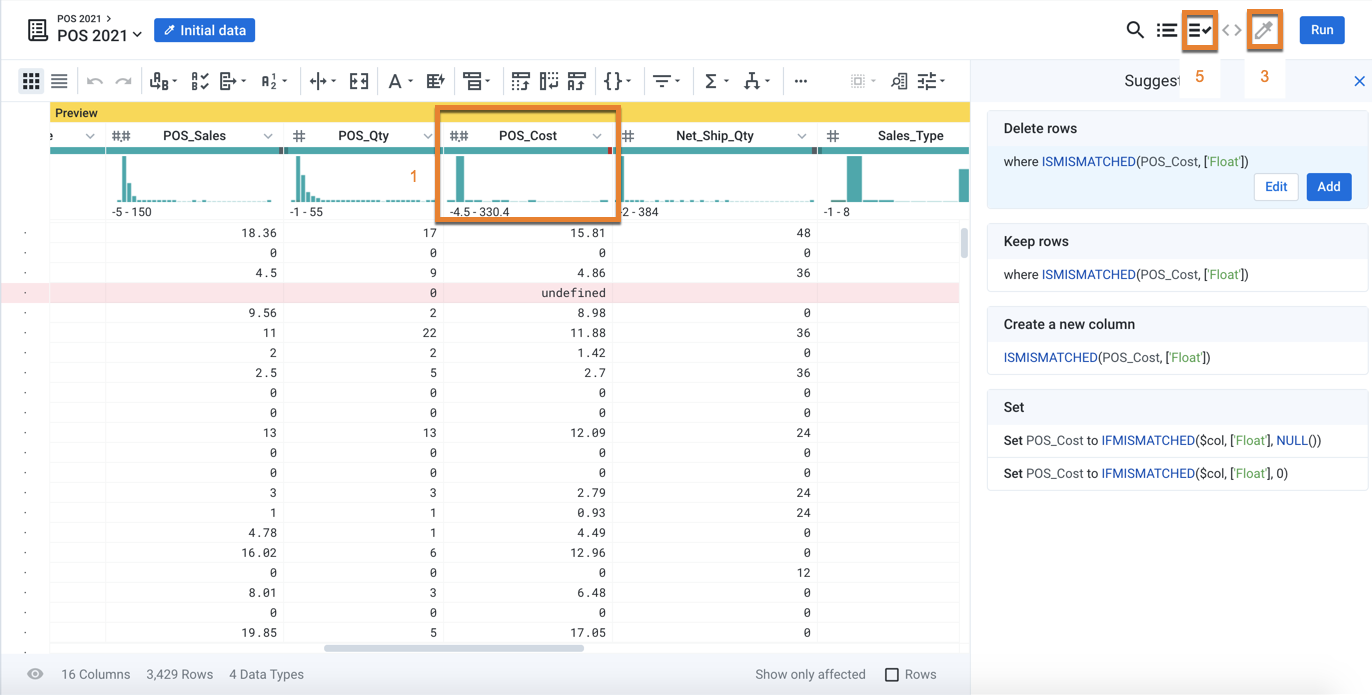
Figure: In the Transformer page, you can explore your data and discover its characteristics and issues.
Tools of discovery include:
Review the column histograms and data quality bars to identify issues with column values (Item 1 above).
Explore Column Details to review additional metrics based on a column's data type (available through the column menu).
Generate new samples to explore different slices of the data (Item 3).
Create a visual profile for a snapshot of the current state of your entire dataset (optionally created when you run a job).
Create data quality rules to continuously monitor domain-specific data quality issues in the data (Item 5).
Cleanse
In the Cloud Portal, it is very easy to identify where there are errors in your data. What is truly innovative is how you correct them:
Select data of interest.
Review suggested transformations.
Select transformation. Modify as needed.
Save your transformation to your recipe.
Data is updated.
Astuce
This process of presenting suggestions based on selections is called predictive transformation. For more information, see Overview of Predictive Transformation.
For more information, see Cleanse Tasks.
Structure
Beginning when data is imported, Designer Cloud supports consistent structuring and reshaping of your data. During file and table import, Designer Cloud applies sophisticated logic to the data to render it into consistent tabular data. If needed, these initial parsing steps can be tuned to meet the requirements of your particular data or file format.
In the Transformer page, you can apply transformations to add new columns, nested and unnested data, and restructure your dataset using aggregations and pivots. For more information, see Reshaping Steps.
Enrich
Prepared data is often sourced from multiple datasets or joined with others or both. In Designer Cloud, you can enrich your data by joining in other datasets or appending additional data to it. Through broad-based connectivity, you can pull in data from disparate sources and combine together to augment your current dataset.
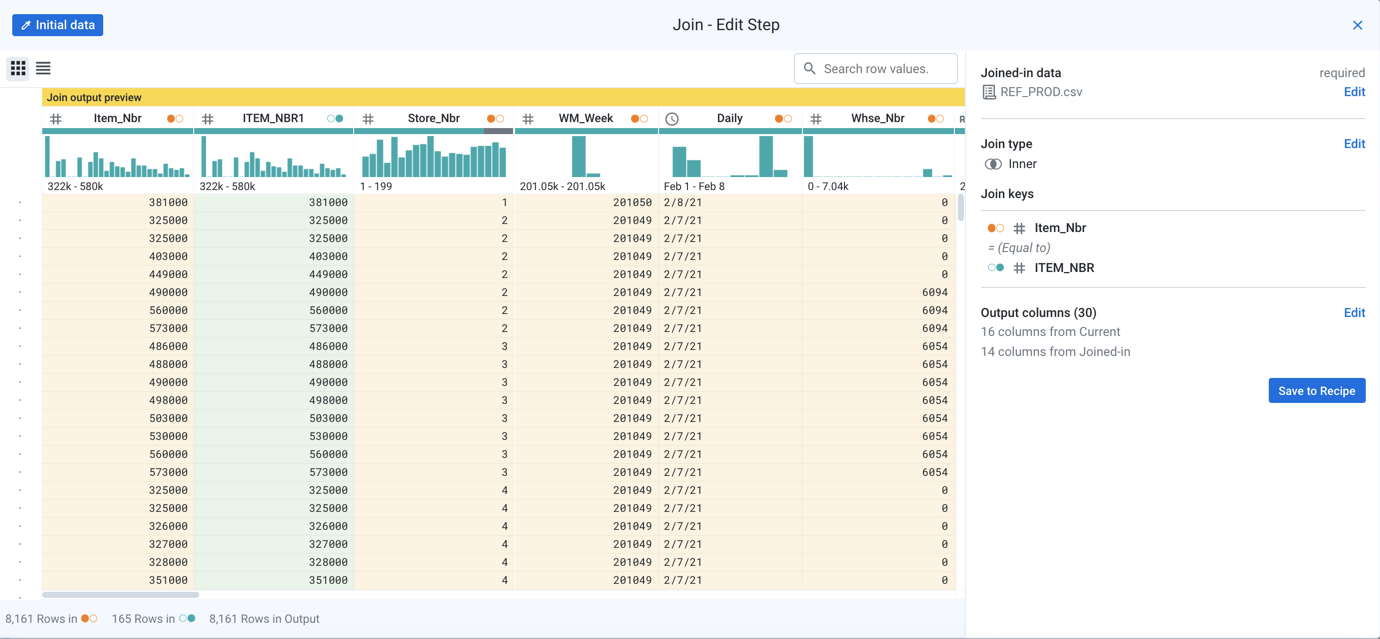
Figure: Join datasets based on one or more key fields. Multiple join types are supported.
Validate
Throughout the transformation development process, you can continuously validate your sampled data against data type and validation rules built for your enterprise requirements. These validation checks exist in the user interface and outside of your recipe steps, so that they provide a continuous status update on any emerging data quality, consistency, and security-related issues.
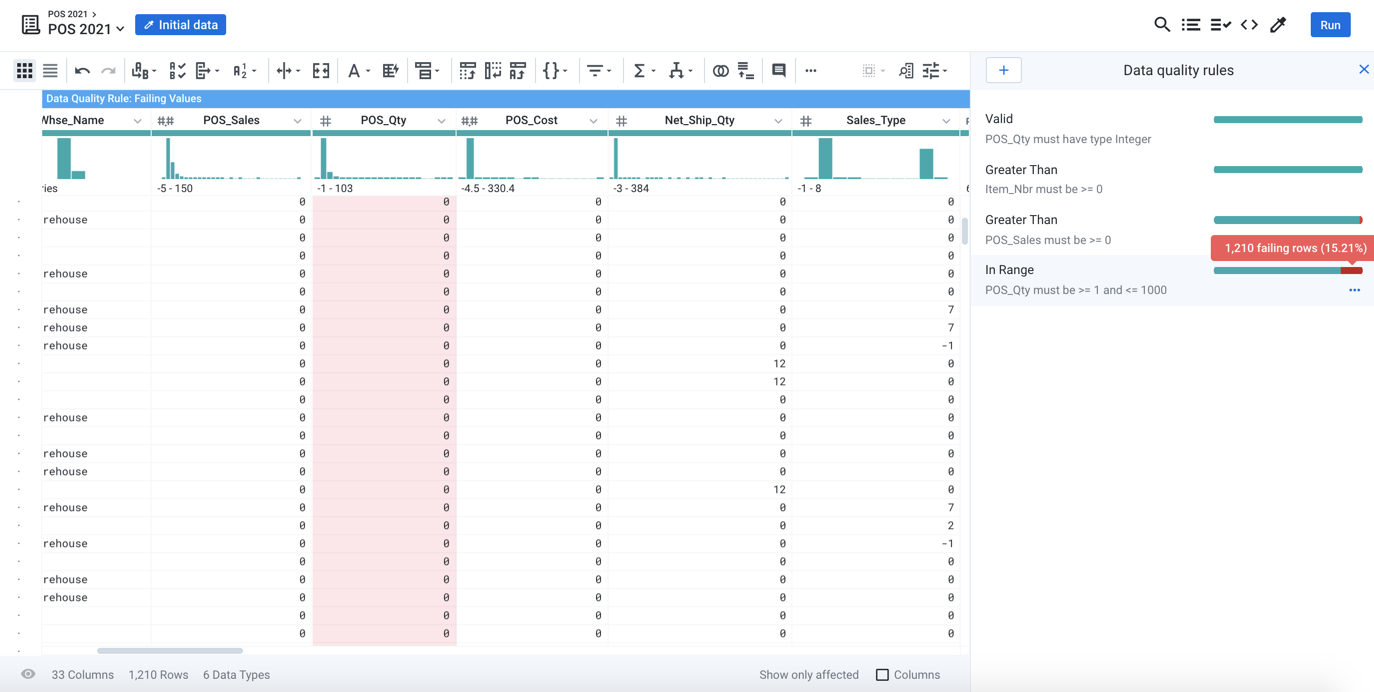
Figure: Data quality rules ensure that your transformations result in higher quality and more consistent data on output.
Publish
When your sample has been transformed, you are ready to apply your transformation across the entire dataset and publish the results. Many of the available connection types support publishing back to the connected datastore, allowing you to take inputs through multiple connections and publish cleaned and transformed data back to one of your available connections where downstream stakeholders and applications can access cleaned, validated, and transformed data.
For more information, see Export Data.
Automate
After your data pipeline has been created and verified, you can automate the execution of the pipeline on a regular basis. When data is landed for import in your datastore, a scheduled execution of your job can bring in the fresh data and apply the same set of transformations to the new data. For more information, see Schedules.
Plans: You can also build sequences of flow jobs and other tasks for more complex tasks. Plans can be scheduled.
See Plans.
Get Results
Run Jobs: To apply your transformations to the entire dataset, you run a job. A job applies the steps in your recipe or recipes to the source data on a running environment that is either co-located with the Cloud Portal for fast execution of smaller jobs or in a distributed cluster of nodes. See Running Job Basics.
Export Results: When results are generated, they can be delivered to the output of your choice. File-based outputs can be stored in the storage layer, where you can access and download them from the Cloud Portal. See Export Basics.
Other Resources
Community: Check out the Alteryx Community, where users collaborate on solutions and share ideas. Additional use-case content can assist you in solving the challenges in front of you. Register for a free account at: Alteryx Community
Training and certification: The Alteryx Academy provides free and paid training to broaden and enhance your command of Designer Cloud. Get certified! For more information, please visit Alteryx Academy