Import PDF Data
Note
NOTE: This feature is in Beta release.
Dataprep by Trifacta can directly import Adobe® Acrobat® PDF files containing one or more tables.
The tables of a PDF can be imported as:
Individual datasets
A single dataset
A dataset with parameters
Note
When importing as a parameterized dataset, all selected tables are imported into a single dataset.
PDF files can be uploaded from your local system.
Note
PDF import is supported through file upload only.
Limitations
Note
Before you begin, you should review information on file formats supported for import, which can cause your files to fail to import or to be properly ingested and formatted. For more information, see Supported File Formats.
PDF ingest is limited to 100 MB per file.
Filepath and source row number information is not available from original PDF files. These references return values from the CSV files that have been converted on the backend. For more information, see Source Metadata References.
You cannot import password-protected PDF files.
Compressed PDF files are not supported.
Conversion of large PDF files require non-linear increases in memory requirements on the Trifacta node.
If loading your PDF-based dataset in the Transformer page results in a blank screen, please take a new sample. The file requires conversion again with each generated sampling.
Latest state of the PDF file may not be reflected in the Transformer page due to caching. When you run a job, the platform always collects the latest version of the data and converts it to CSV for execution.
Table Import
The PDF file format is a publishing format designed around visual layout of information, some of which may include tabular data. Table data in PDF files must be detected and converted into CSV data for proper ingestion in the platform. This ingest process occurs on the backend datastore.
To facilitate ingestion, the following requirements must be met for tables in your source PDF files:
Non-tabular data in the file is ignored.
Tables must be enclosed in a border. Each cell in the table must be bordered.
Tabular data in the PDF cannot be scanned data, which is stored as an image. Data must be written into the file.
When a table spans multiple pages, it is ingested as two separate CSV files, which can be combined later.
If a file contains multiple tables, each table is converted as a separate dataset.
Tip
After import, separate datasets can be unioned together or integrated using as a dataset with parameters.
Import Steps
In the menu bar, click Library for Data.
In the Library for Data page, click Import Data. Select the connection to use.
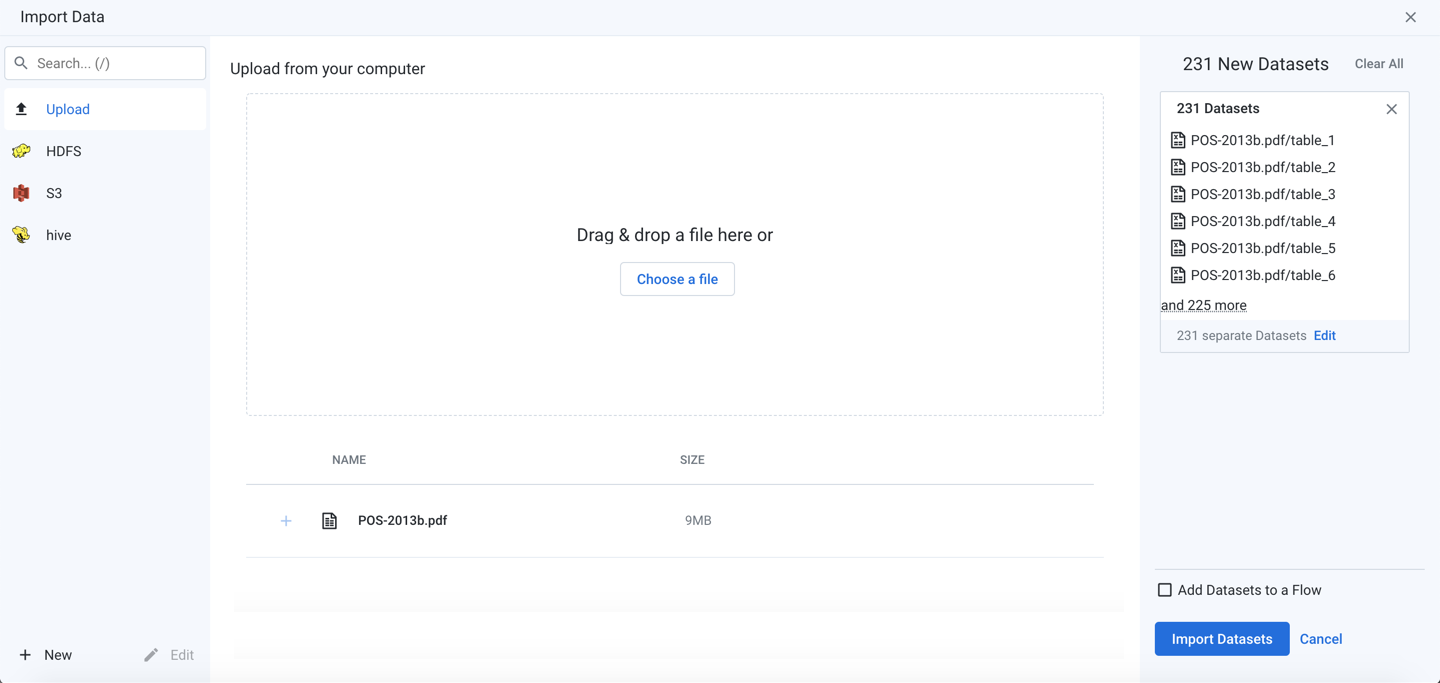
Figure: Import PDF file containing multiple pages
After you select the file, it is uploaded and converted to into individual CSV files for each page in the PDF file and then stored by the platform. Depending on the size of the file, this process may take a while.
By default, all pages in the PDF are imported as individual datasets. To change how the data is imported, click Edit in the right panel.
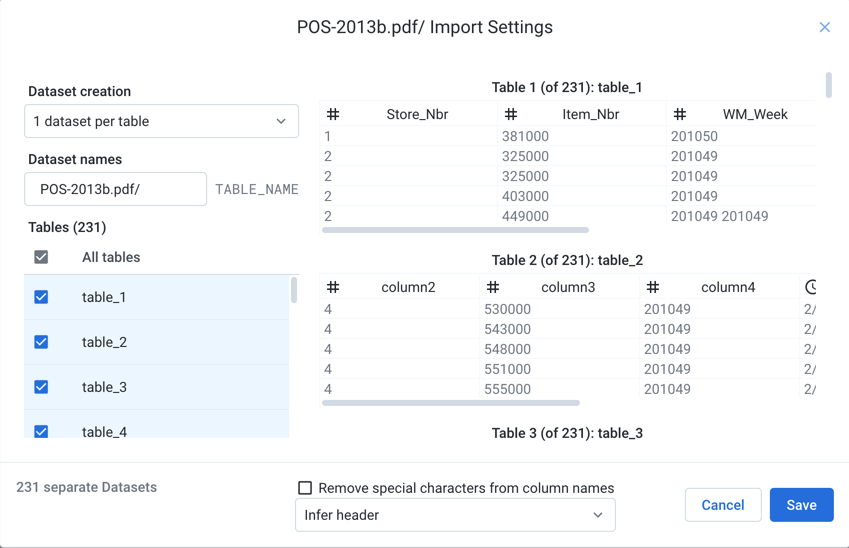
Figure: Import settings for PDF datasets
Dataset creation:
1 dataset per table: (Default) Each selected table in the PDF is imported as a separate dataset.
Specify the base name of the datasets that you are creating. If you are creating a single dataset, the name of the PDF file is used.
Selected tables into 1 dataset: All selected tables in the PDF are combined and imported as a single dataset.
Note
The schemas of each dataset must match. Columns must be listed in the same order in each dataset. The column headers are taken from the first selected dataset.
Selected tables:
You can select the tables to import. A table can be a single page, or a single table among multiple on a page.
Note
If you are importing a folder of PDF files, data preview and initial sampling are executed against the first file found in the folder.
To preview the data of an individual table, mouse over a dataset and click Jump to.
Remove special characters from column names: Select this option to remove any special characters from the inferred column headers during import.
You can also choose how to detect column headers from each imported table.
To save changes, click Save.
After your datasets have been added, you can edit the name and description information for each in the right navigation panel.
Optionally, you can assign the new dataset(s) to an existing flow or create a new one to contain them.
For more information, see Import Data Page.