The Alteryx database file format YXDB is a file type that can hold data fields, values, and spatial objects. The YXDB format is the most efficient file type for reading and writing in Alteryx because it has no size limit, is compressed for maximum speed, and includes additional metadata that references the source of the data and how the data was created. While there is no limit to the number of rows or file size, there is a size limit of 2 GB for a single cell in a 64-bit environment. All Alteryx products have read and write support for YXDB files.
A YXDB file uses the exact same column types, structures, and formats as Alteryx does internally, so it works best with the program. There is no row limit so you can have greater than 2 billion rows. There is not any other file format, other than text, that supports as many rows.
Yes, they are minimally compressed for maximum speed, not maximum compression. If you have a spatial index, the compression is not very noticeable. Without a spatial index, the compression can be quite good at times.
Yes, but in this case, you would want to turn off the Spatial Index in the advanced options so you don't waste any time and space creating it.
When Alteryx writes to a YXDB file, the data in the Source and Description columns are saved in the file so you will always know how a field was created or what vintage of the underlying data values are. See the Field Info Tool for an example of this metadata.
Source: Contains the tool, file, or process the field came from. It might also contain additional meta info like a specific dataset from a plugin. The tools that report meta info include: Allocate Input tool and Allocate Append tool, CASS tool, Formula tool, Street Geocoder tool, and tools that use Guzzler like Trade Area tool, Distance tool, and Find Nearest tool.
Description: Might or might not contain information. If data is appended from an Allocate tool, the longer, more descriptive field name is contained here. Additionally, the user can add their own field description via the Select tool, and this information stays associated with the field.
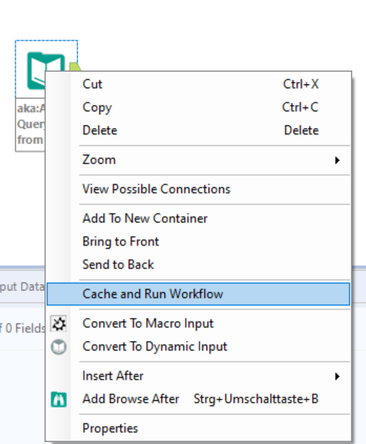
I have 2 SQL queries and a few workflows where the second dataset stays the same and has 3 million records. Is there a way I can reuse the second dataset in the same workflow or in different workflows so that it won't have to execute the select statement again and again?
If you need intermediate storage of data in your workflow, use an Output Data tool and write to YXDB format. You can have your first workflow write to the YXDB file which stores all of the data from your query. Then use that YXDB as the input data for your other workflows. This way you can work off of the static dataset for development. If you ever want to switch the workflow to a live data connection you can just copy the Input Data tool from the other workflow.
Alternatively, if you only need to reuse data within one workflow, consider the Cache and Run Workflow feature.