Requisitos de configuração do driver | Para processamento em banco de dados e para evitar erros de gravação com a ferramenta Dados de Saída , especifique warehouse, esquema e banco de dados no driver. |
Tipo de suporte | Leitura e gravação; no banco de dados. |
Validado em | Versão do banco de dados: 6.8.1 Versão de cliente ODBC: 3.0.0.1001 64 bits |
Ferramenta Dados de Saída (processamento de fluxo de trabalho padrão)
Ferramenta Conectar In-DB e Ferramenta Entrada do Fluxo de Dados (processamento de fluxos de trabalho em banco de dados)


Selecione a ferramenta Dados de Entrada e navegue até o painel Dados de Entrada (1) - Configuração > clique na seta suspensa em Conectar a um arquivo ou banco de dados .
Na janela "Conexões de dados", vá para Fontes de dados > Todas as fontes de dados > Snowflake > ODBC .
Na janela pop-up Conexão Snowflake ODBC , digite seu Nome de usuário e Senha .
Na janela Escolher tabela ou especificar consulta , selecione a guia Tabelas > selecione uma tabela > clique em OK .
Se desejar trabalhar no modo Clássico , navegue até Opções > Configurações de usuário > Editar configurações de usuário > marque a caixa de seleção Usar modo clássico para o menu de opções das ferramentas de Entrada/Saída .
Para especificar uma consulta, selecione a guia Editor de SQL > digite a consulta no espaço disponível > selecione o botão Testar consulta > selecione OK .
Selecione a ferramenta Dados de Saída e navegue até o menu > Opções .
Selecione Configurações de usuário > Editar configurações de usuário > marque a caixa de seleção Usar modo clássico para o menu de opções das ferramentas de Entrada/Saída .
Navegue até o painel Dados de Saída (1) - Configuração > em Gravar em arquivo ou banco de dados > clique na seta suspensa .
Selecione Outros bancos de dados > selecione Snowflake em massa... .
Você pode usar a ferramenta Dados de Entrada (modo clássico) para selecionar seus arquivos e fontes de dados.
Se quiser alternar para o modo clássico , substitua a ferramenta Dados de Saída por uma nova ferramenta > clique na tela ou pressione F5 para atualizar.
Para dar suporte total para leitura e gravação de tabelas e colunas, defina a opção do Alteryx Designer Estilo SQL do nome do campo/tabela como Entre aspas . A opção "Entre aspas" seleciona especificamente a tabela no banco de dados, enquanto a opção Nenhum produz resultados em letras maiúsculas.
Antes de configurar uma conexão em massa do Snowflake, saiba que:
Você só pode gravar dados com o carregador em massa do Snowflake.
Depois de gravar os dados na nova saída, o carregador em massa do Snowflake remove os dados gravados do bucket do S3.
O comprimento máximo permitido para campos de texto é de 16.777.216 bytes.
Para obter mais informações, acesse a documentação do Snowflake .
Nota
A partir da versão 2023.2, o Designer cancela todas as execuções não concluídas no banco de dados ao cancelar o fluxo de trabalho no local. Isso permite que você desbloqueie seus pipelines de dados. O recurso melhora a interação geral do banco de dados.
Em Administrador de Fonte de Dados ODBC , selecione o driver do Snowflake e clique em Configurar .
Digite suas configurações de conexão e credenciais.
Selecione OK para salvar a conexão.
Nota
Para oferecer suporte total para leitura e gravação de tabelas e colunas em CamelCase, é necessário definir a opção do Alteryx Designer Estilo SQL do nome do campo/tabela como Entre aspas .
Para configurar um JWT do Snowflake por meio do driver ODBC:
Crie o token de acordo com as instruções do Snowflake: https://docs.snowflake.com/en/user-guide/key-pair-auth.html.
Defina o Autenticador no DSN do ODBC como SNOWFLAKE_JWT.
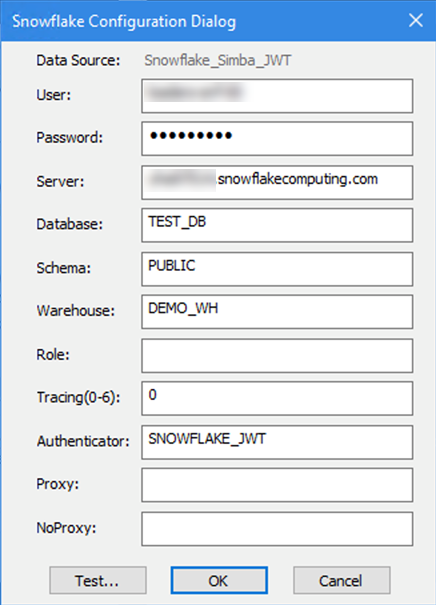
No Alteryx, a cadeia de conexão deve apontar para o local do arquivo, por exemplo:
odbc:DSN=Simba_Snowflake_JWT;UID=user;PRIV_KEY_FILE=G:\AlteryxDataConnectorsTeam\OAuth project\PEMkey\rsa_key.p8;PRIV_KEY_FILE_PWD=__EncPwd1__;JWT_TIMEOUT=120Para obter mais instruções, consulte a documentação do Snowflake .
O carregamento em massa tem suporte para conexões usando um DSN, bem como conexões sem DSN.
Para configurar o carregador em massa usando uma cadeia de conexão sem DSN, construa a cadeia de conexão manualmente. A cadeia de caracteres deve conter parâmetros necessários para gravar para Snowflake e aqueles necessários para o preparo. Os necessários para o Snowflake podem ser encontrados na documentação do Snowflake . Os necessários para o preparo podem ser encontrados abaixo.
Exemplo de cadeia de conexão:
snowbl:Driver= {SnowflakeDSIIDriver};Server=customerinstance.snowflakecomputing.com;Database=TEST_DB; Warehouse=TEST_WAREHOUSE;schema=PUBLIC;UID=user;PWD=password;Bucket=S3Bucket; Access=IAMAccessKey;Secret=IAMSecretKey;URL=s3.amazonaws.com;Region=us-east-1
Para configurar o carregador em massa com um DSN, use a interface do usuário e siga as etapas abaixo:
Selecione a ferramenta Dados de Saída e navegue até o painel Dados de Saída (1) - Configuração .
Em Gravar em arquivo ou banco de dados , selecione a seta suspensa > na janela Conexões de dados , selecione a guia Fontes de dados > Todas as fontes de dados > Snowflake > Em massa .
Na janela Conexão em massa do Snowflake , selecione a guia Local > insira suas credenciais nos espaços Nome de usuário (opcional) e Senha (opcional) > clique em OK para ver a janela pop-up Tabela de saída .
Digite o nome da tabela (ou planilha) para o arquivo de saída que foi especificado, seja com o nome da tabela ou na forma de db.schema.tablename : essa é sua tabela totalmente qualificada.
Em Opções , no painel Dados de Saída (1) - Configuração , selecione na lista suspensa Estilo SQL do nome do campo/tabela a opção Entre aspas ou Nenhum .
Em Obter nome de arquivo/tabela de um campo , decida se deseja marcar a caixa de seleção para habilitar o menu suspenso Adicionar sufixo ao nome do arquivo/tabela . Se você marcar a caixa de seleção, nas opções do menu suspenso, escolha...
Adicionar sufixo ao nome do arquivo/tabela
Adicionar prefixo ao nome do arquivo/tabela
Alterar nome do arquivo/tabela
Alterar todo o caminho do arquivo
Se você marcar a caixa de seleção Adicionar sufixo ao nome do arquivo/tabela , em Campo que contém o nome do arquivo ou parte do nome do arquivo , selecione um dos seguintes:
SEQUENCE_CATALOG
SEQUENCE_SCHEMA
SEQUENCE_NAME
SEQUENCE_OWNER
DATA_TYPE
NUMERIC_PRECISION
NUMERIC_PRECISION_RADIX
NUMERIC_SCALE
START_VALUE
MINIMUM_VALUE
MAXIMUM_VALUE
NEXT_VALUE
INCREMENT
CYCLE_OPTION
CREATED
LAST_ALTERED
COMMENT
Decida se deseja marcar a caixa de seleção Manter campo na saída , para a opção selecionada na lista suspensa para usar com os dados da tabela.
Na janela Dados de Saída - Configuração , selecione Gravar em arquivo ou banco de dados e selecione Outros bancos de dados > Snowflake em massa para exibir a janela Conexão em massa do Snowflake .
Selecione o Nome da fonte de dados ou clique em Admin ODBC para criar um. Consulte Conexões de banco de dados ODBC e OLEDB .
Digite Nome de usuário e Senha , conforme necessário.
Na guia Amazon S3 , digite sua Chave de acesso do AWS e sua Chave secreta do AWS .
Em Criptografia de chave secreta , selecione uma opção de criptografia:
Ocultar : ocultar a senha usando criptografia mínima.
Criptografar para máquina : qualquer usuário no computador tem acesso total à conexão.
Criptografar para usuário : o usuário conectado tem acesso total à conexão em qualquer computador.
Em Ponto de extremidade , selecione uma das seguintes opções:
Default : a Amazon determina o ponto de extremidade com base no bucket selecionado.
Ponto de extremidade específico : para especificar a região do S3 onde está o bucket, especifique um ponto de extremidade personalizado ou selecione um ponto de extremidade inserido anteriormente.
O bucket do S3 deve estar na região do S3 especificada. Caso contrário, o seguinte erro será exibido: O bucket que você está tentando acessar deve ser tratado usando o ponto de extremidade especificado. Envie todas as solicitações futuras para esse ponto de extremidade.
Selecione Padrão para fechar a janela de erro.
(Opcional) Selecione Usar Signature V4 para autenticação para aumentar a segurança para além do Signature versão 2 padrão. Essa opção é habilitada automaticamente para regiões que exigem o Signature versão 4. As regiões criadas após 30 de janeiro de 2014 são compatíveis apenas com o Signature versão 4. As seguintes regiões exigem autenticação do Signature versão 4:
Região do leste dos EUA (Ohio)
Região do Canadá (central)
Região da Ásia-Pacífico (Mumbai)
Região da Ásia-Pacífico (Seul)
Região da UE (Frankfurt)
Região da UE (Londres)
Região da China (Pequim)
Selecione um método de Criptografia do lado do servidor para carregar para um bucket criptografado do Amazon S3. Consulte o guia do desenvolvedor do Amazon S3.
Nenhum (padrão) : nenhum método de criptografia é usado.
SSE-KMS : usa criptografia do lado do servidor com as chaves gerenciadas pelo AWS KMS. Você também pode fornecer um ID de chave KMS . Quando você seleciona esse método, Usar Signature V4 para autenticação é habilitado por padrão.
Digite o Nome do bucket da AWS no qual seus objetos de dados estão armazenados.
Configure opções adicionais de Formato de arquivo no painel Dados de Saída (1) - Configuração . Consulte Opções de formato de arquivo .
Agora você tem três opções aprimoradas para escolher ao preparar os dados para sua unidade local.
Selecione a ferramenta Dados de saída e navegue até o painel Dados de Saída (1) - Configuração > em Gravar em arquivo ou banco de dados , navegue até a janela Conexões de dados e selecione a guia Fontes de dados > Todas as fontes de dados > Snowflake > selecione Em massa . Na janela Conexão em massa do Snowflake > selecione a guia Local .
Preparo por usuário (User Stage) : preparo interno fornecido pelo Snowflake associado ao usuário.
Selecione Preparo por usuário > clique em OK . Na janela pop-up Tabela de saída , digite o nome da tabela (ou planilha) para o formato de arquivo da saída, seja usando o nome da tabela ou a forma db.schema.tablename : essa é a tabela totalmente qualificada. Clique em OK . Em Opções , no painel Dados de Saída (1) - Configuração , selecione no menu suspenso Estilo SQL do nome do campo/tabela a opção Entre aspas ou Nenhum .
Preparo por tabela (Table Stage) : preparo interno fornecido pelo Snowflake associado à tabela.
Selecione Preparo por tabela (Table Stage) > clique em OK . Na janela pop-up Tabela de saída , digite o nome da tabela (ou planilha) para o formato de arquivo da saída, seja usando o nome da tabela ou a forma db.schema.tablename : essa é a tabela totalmente qualificada. Clique em OK . Em Opções , no painel Dados de Saída (1) - Configuração , selecione no menu suspenso Estilo SQL do nome do campo/tabela a opção Entre aspas ou Nenhum .
Preparo interno nomeado : na base de dados do Snowflake , crie e execute um comando CREATE STAGE e forneça o nome do preparo à configuração da ferramenta.
Nota
O tamanho máximo do campo é de 16 MB. Se o limite de tamanho do campo for excedido, um erro será emitido e nenhum dado será gravado.
Tipo de compactação : as opções são "Sem compactação" ou "Compactar com GZip".
Sem compactação: os arquivos são preparados e carregados como CSV
Compactar com GZip: os arquivos CSV são compactados com GZip
Tamanho das partes em MB (1 a 999) : essa opção permite selecionar o tamanho de cada CSV preparado localmente.
Nota
O tamanho real do arquivo pode variar em relação ao tamanho das partes selecionado devido à formatação e compactação subjacentes.
Número de threads (1 a 99) : essa opção especifica o número de threads a serem usadas ao carregar arquivos para o Snowflake. O desempenho pode melhorar em arquivos maiores quando esse valor é mais alto. Se 0 for inserido, será usado o padrão do Snowflake (4).
A partir do preparo, cada cópia na tabela pode conter até 1.000 arquivos. Se houver mais de 1.000 arquivos no preparo, você poderá ver várias cópias para instruções. Esse é um requisito do Snowflake para copiar para instruções usando arquivos. Para obter mais informações, consulte o portal do Snowflake .
Mais informações sobre as opções de tipo de compactação, tamanho das partes em MB e número de threads podem ser encontradas no portal do Snowflake .