Requisiti di configurazione del driver | Per il processo In-Database e per evitare errori durante la scrittura dei dati con lo strumento Dati di output , specifica Warehouse, Schema e Database nel driver. |
Tipo di supporto | Lettura e scrittura; In-Database. |
Convalidato su | Versione database: 6.8.1 Versione client ODBC: 3.0.0.1001 a 64 bit |
Strumento Dati di output (elaborazione flusso di lavoro standard)
Strumento Connetti In-DB e Strumento Flusso di dati in entrata (elaborazione del flusso di lavoro In-Database)


Seleziona lo strumento Dati di input e accedi al riquadro Dati di input (1) - Configurazione > seleziona l' icona dell'elenco a discesa in Connetti un file o un database .
Accedi alla finestra Connessioni dati > Tutte le origini dati > Snowflake > ODBC .
Nella finestra pop-up Connessione ODBC Snowflake , immetti il nome utente e la password .
Nella finestra Scegli una tabella o specifica una query , seleziona la scheda Tabelle > seleziona una tabella > seleziona OK .
Se desideri lavorare nella modalità classica , accedi a Opzioni > Impostazioni utente > Modifica impostazioni utente > seleziona la casella di spunta Utilizza la modalità classica per le opzioni di menu degli strumenti di input/output .
Per specificare una query, seleziona la scheda Editor SQL > immetti la query nello spazio disponibile > seleziona il pulsante Test query > seleziona OK .
Seleziona lo strumento Dati di output e accedi al menu > Opzioni .
Seleziona Impostazioni utente > Modifica impostazioni utente > seleziona la casella di spunta Utilizza la modalità classica per le opzioni di menu degli strumenti di input/output .
Accedi al riquadro Dati di output (1) - Configurazione > in Scrivi nel file o nel database > seleziona l' icona del menu a discesa .
Seleziona Altri database > seleziona Snowflake Bulk...
Puoi anche utilizzare lo strumento Dati di input (modalità classica) per selezionare i file e le origini dati.
Per passare alla modalità classica , sostituisci lo strumento Dati di output con un nuovo strumento > seleziona l' area di disegno o premi F5 per aggiornare.
Per supportare completamente la lettura e la scrittura di tabelle e colonne, imposta l'opzione Stile SQL di Tabella/Nome campo di Alteryx Designer su Tra virgolette . L'opzione "Tra virgolette" consente di selezionare specificamente la tabella nel database, mentre l'opzione Nessuno consente di ottenere risultati tutti in lettere maiuscole.
Prima di configurare una connessione Snowflake Bulk, consulta le seguenti informazioni:
Puoi scrivere i dati solo con Snowflake Bulk Loader.
Dopo aver scritto i dati nel nuovo output, Snowflake Bulk Loader rimuove i dati scritti dal contenitore S3.
La lunghezza massima consentita per i campi di testo è di 16.777.216 byte.
Per ulteriori informazioni, consulta la documentazione Snowflake .
Nota
A partire dalla versione 2023.2, Designer annulla tutte le esecuzioni In-Database non completate quando annulla localmente il flusso di lavoro. Ciò consente di sbloccare le pipeline di dati. Questa funzionalità migliora l'interazione complessiva con il database.
In Amministrazione origine dati ODBC , seleziona il driver Snowflake e scegli Configura .
Immetti le credenziali e le impostazioni di connessione.
Seleziona OK per salvare la connessione.
Nota
Per supportare completamente la lettura e la scrittura di tabelle e colonne con notazioni a cammello, devi impostare l'opzione Stile SQL di Tabella/Nome campo di Alteryx Designer su Tra virgolette .
Per configurare un JWT Snowflake tramite il driver ODBC:
Crea il token come da istruzioni di Snowflake: https://docs.snowflake.com/en/user-guide/key-pair-auth.html.
Imposta il metodo di autenticazione nel DSN ODBC su SNOWFLAKE_JWT.
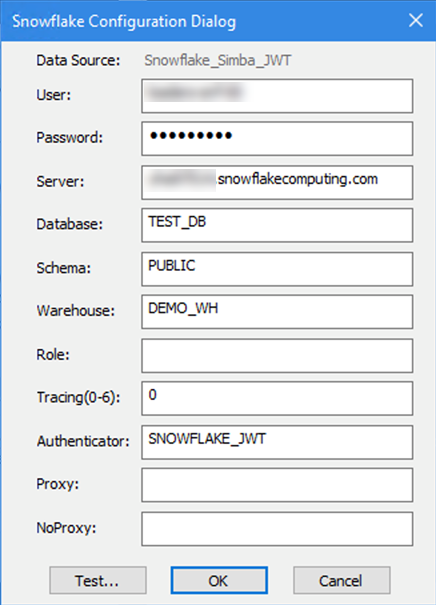
In Alteryx, la stringa di connessione deve puntare alla posizione del file, ad esempio:
odbc:DSN=Simba_Snowflake_JWT;UID=user;PRIV_KEY_FILE=G:\AlteryxDataConnectorsTeam\OAuth project\PEMkey\rsa_key.p8;PRIV_KEY_FILE_PWD=__EncPwd1__;JWT_TIMEOUT=120Per ulteriori istruzioni, vedi la documentazione Snowflake .
Il caricamento bulk è supportato per le connessioni che utilizzano un DSN e per le connessioni senza DSN.
Per configurare il caricamento bulk utilizzando una stringa di connessione senza DSN, costruire manualmente la stringa di connessione. La stringa deve contenere i parametri necessari per scrivere in Snowflake e quelli necessari per lo staging. Le informazioni necessarie per Snowflake si trovano nella documentazione Snowflake . Di seguito sono riportate le informazioni necessarie per lo staging.
Esempio di stringa di connessione:
snowbl:Driver= {SnowflakeDSIIDriver};Server=customerinstance.snowflakecomputing.com;Database=TEST_DB; Warehouse=TEST_WAREHOUSE;schema=PUBLIC;UID=user;PWD=password;Bucket=S3Bucket; Access=IAMAccessKey;Secret=IAMSecretKey;URL=s3.amazonaws.com;Region=us-east-1
Per configurare il caricamento bulk con un DSN, utilizzare l'interfaccia utente e attenersi alla procedura seguente:
Seleziona lo strumento Dati di output e accedi al riquadro Dati di output (1) - Configurazione .
In Scrivi nel file o nel database , seleziona l' icona del menu a discesa > accedi alla finestra Connessioni dati per selezionare la scheda Origini dati > Tutte le origini dati > Snowflake > seleziona Bulk .
Nella finestra Connessione Snowflake Bulk , seleziona la scheda Locale > immetti le tue credenziali negli spazi Nome utente (facoltativo) e Password (facoltativa) > seleziona OK per visualizzare la finestra pop-up Tabella di output .
Immetti il nome della tabella (o del foglio di lavoro) per il file di output specificato, con il nome della tabella o nel formato db.schema.tablename : si tratta del nome completo della tabella.
In Opzioni , nel riquadro Dati di output (1) - Configurazione , seleziona dal menu a discesa Stile SQL di Tabella/Nome campo Tra virgolette o Nessuno .
In Prendi il nome file/tabella dal campo , scegli se selezionare la relativa casella di spunta per il menu a discesa Aggiungi suffisso a nome file/tabella . Se selezioni la casella di spunta, dalle selezioni a discesa scegli...
Aggiungi suffisso a nome file/tabella.
Anteponi un prefisso al nome file/tabella.
Modifica file/nome tabella
Modifica intero percorso del file.
Se selezioni la casella di spunta Aggiungi suffisso a nome file/tabella , in Campo che contiene il nome del file o parte del nome del file , scegli di utilizzare una delle seguenti opzioni:
SEQUENCE_CATALOG
SEQUENCE_SCHEMA
SEQUENCE_NAME
SEQUENCE_OWNER
DATA_TYPE
NUMERIC_PRECISION
NUMERIC_PRECISION_RADIX
NUMERIC_SCALE
START_VALUE
MINIMUM_VALUE
MAXIMUM_VALUE
NEXT_VALUE
INCREMENT
CYCLE_OPTION
CREATED
LAST_ALTERED
COMMENT
Decidi se selezionare la casella di spunta Mantieni il campo nell'output per l'opzione selezionata dal menu a discesa da utilizzare con i dati della tabella.
Dalla finestra Dati di output - Configurazione , seleziona Scrivi nel file o nel database e seleziona Altri database > Snowflake Bulk per visualizzare la finestra Connessione di Snowflake Bulk .
Seleziona un Nome origine dati oppure Amministratore ODBC per crearne uno. Vedi Connessioni al database ODBC e OLEDB .
Immetti nome utente e password , se necessario.
In Amazon S3 , immetti la chiave di accesso AWS e la chiave segreta AWS .
In Crittografia chiave segreta , seleziona un'opzione di crittografia:
Nascondi : nasconde la password utilizzando la crittografia minima.
Crittografa per computer : qualsiasi utente del computer ha accesso completo alla connessione.
Crittografa per l'utente : l'utente connesso ha accesso completo alla connessione su qualsiasi computer.
In Endpoint , seleziona una delle seguenti opzioni:
Predefinito : Amazon determina l'endpoint in base al contenitore selezionato.
Endpoint specifico : per specificare un'area S3 in cui risiede il contenitore, specifica un endpoint personalizzato o selezionalo dagli endpoint precedentemente immessi.
Il contenitore S3 deve trovarsi nell'area S3 specificata. In caso contrario, viene visualizzato il seguente errore: Il contenitore a cui stai tentando di accedere deve essere gestito utilizzando l'endpoint specificato. Invia tutte le richieste future a questo endpoint.
Seleziona Predefinito per chiudere la finestra di errore.
(Facoltativo) Seleziona Usa Signature V4 per l'autenticazione per aumentare il livello di sicurezza fornito dalla versione Signature 2 predefinita. Questa opzione è abilitata automaticamente per le aree che richiedono Signature Version 4. Le aree create dopo il 30 gennaio 2014 supportano solo Signature Version 4. Le aree seguenti richiedono l'autenticazione Signature Version 4:
Regione degli Stati Uniti orientali (Ohio)
Regione Canada (centrale)
Regione Asia-Pacifico (Mumbai)
Regione Asia-Pacifico (Seul)
Regione UE (Francoforte)
Regione UE (Londra)
Regione Cina (Pechino)
Seleziona un metodo di crittografia lato server per il caricamento in un contenitore Amazon S3 crittografato. Consulta la Guida per gli sviluppatori di Amazon Simple Storage Service.
Nessuno (opzione predefinita) : non viene utilizzato alcun metodo di crittografia.
SSE-KMS : utilizza la crittografia lato server con le chiavi gestite da AWS KMS. Puoi fornire anche un ID chiave KMS . Quando selezioni questo metodo, l'opzione Usa Signature V4 per l'autenticazione è abilitata per impostazione predefinita.
Immetti il nome contenitore del contenitore AWS in cui sono archiviati gli oggetti dati.
Configura ulteriori opzioni di formato file nel riquadro Dati di output (1) - Configurazione . Consulta Opzioni formato file .
Ora hai tre opzioni avanzate tra cui scegliere quando esegui lo staging dei dati nell'archivio locale.
Seleziona lo strumento Dati di output e accedi al riquadro Dati di output (1) - Configurazione > in Scrivi nel file o nel database , accedi alla finestra Connessioni dati e seleziona la scheda Origini dati > Tutte le origini dati > Snowflake > seleziona Bulk . Nella finestra Connessione di Snowflake Bulk > seleziona la scheda Locale >
Fase utente : la fase interna fornita da Snowflake, associata all'utente.
Seleziona Utente > seleziona OK . Nella finestra pop-up Tabella di output , immetti il nome della tabella (o del foglio di lavoro) per il formato del file di output specificato con il nome della tabella o nel formato db.schema.tablename : si tratta del nome completo della tabella. Seleziona OK . In Opzioni , nel riquadro Dati di output (1) - Configurazione , seleziona dal menu a discesa Stile SQL di Tabella/Nome campo Tra virgolette o Nessuno .
Fase tabella : la fase interna fornita da Snowflake, associata alla tabella.
Seleziona Fase tabella > seleziona OK . Nella finestra pop-up Tabella di output , immetti il nome della tabella (o del foglio di lavoro) per il formato del file di output specificato con il nome della tabella o nel formato db.schema.tablename : si tratta del nome completo della tabella. Seleziona OK . In Opzioni , nel riquadro Dati di output (1) - Configurazione , seleziona dal menu a discesa Stile SQL di Tabella/Nome campo Tra virgolette o Nessuno .
Fase nome interno : nel database Snowflake , crea ed esegui un comando CREATE STAGE , quindi fornisci il nome della fase alla configurazione dello strumento.
Nota
La dimensione massima del campo è di 16 MB. Se la soglia delle dimensioni del campo viene superata, viene generato un errore e non vengono scritti dati.
Tipo di compressione : le opzioni sono "Nessuna compressione" o "Comprimi con GZip".
Nessuna compressione: viene eseguito lo staging dei file e questi vengono caricati come CSV
Compressione con GZIP: i file CSV sono compressi con GZIP
Dimensione blocco in MB (1-999) : questa opzione consente di selezionare le dimensioni di ogni CSV per cui viene eseguito lo staging localmente.
Nota
Le dimensioni effettive del file possono variare rispetto alle dimensioni del blocco selezionato a causa della formattazione e della compressione sottostanti.
Numero di thread (1-99) : questa opzione specifica il numero di thread da utilizzare per caricare i file su Snowflake. Le prestazioni possono migliorare per i file più grandi quando questo valore aumenta. Se immetti 0, viene utilizzata l'impostazione predefinita di Snowflake (4).
Dalla fase, ogni copia nella tabella può contenere fino a 1000 file. Se sono presenti più di 1000 file nella fase, è possibile che vengano visualizzate più istruzioni Copy into. Questo è un requisito Snowflake per le istruzioni Copy into utilizzando i file. Per ulteriori informazioni, consulta il portale Snowflake .
Ulteriori informazioni sulle opzioni per tipo di compressione, dimensione del blocco in MB e numero di thread sono disponibili nel portale Snowflake .