Anforderungen an die Treiberkonfiguration | Für den In-DB-Prozess und um Fehler beim Schreiben von Daten mit dem Datenausgabe-Tool zu vermeiden, müssen Sie ein Warehouse, ein Schema und eine Datenbank im Treiber angeben. |
Typ der Unterstützung | Lesen und Schreiben; In-DB |
Validiert am | Datenbankversion: 6.8.1 ODBC-Client-Version: 3.0.0.1001 64 Bit |
Datenausgabe-Tool (Standard-Workflow-Verarbeitung)
Tool „In-DB verbinden“ und Tool „Eingehender Datenstrom“ (In-Database-Workflow-Verarbeitung).


Wählen Sie das Eingabedaten-Tool aus, und navigieren Sie zum Bereich Eingabedaten (1) – Konfiguration > Wählen Sie das Dropdown-Symbol unter Datei oder Datenbank verbinden aus.
Navigieren Sie im Fenster Datenverbindungen zu > Alle Datenquellen > Snowflake > ODBC.
Geben Sie im Popup-Fenster Snowflake ODBC-Verbindung Ihren Benutzernamen und Ihr Kennwort ein.
Navigieren Sie im Fenster Tabelle auswählen oder Abfrage eingeben zur Tabellen-Registerkarte > Wählen Sie eine Tabelle aus > Wählen Sie OK aus.
Wenn Sie im KlassischenModus arbeiten möchten, navigieren Sie zu Optionen > Benutzereinstellungen > Benutzereinstellungen bearbeiten > Aktivieren Sie das Kontrollkästchen Klassischen Modus für Menüoptionen der Eingabe-/Ausgabe-Tools verwenden.
Um eine Abfrage einzugeben, wählen Sie die Registerkarte SQL-Editor aus > Geben Sie die Abfrage in den vorhandenen Bereich ein > Wählen Sie die Schaltfläche Testabfrage aus > Wählen Sie OK aus.
Wählen Sie das Datenausgabe-Tool aus, und navigieren Sie zu Menü > Optionen.
Wählen Sie Benutzereinstellungen > Benutzereinstellungen bearbeiten > Aktivieren Sie das Kontrollkästchen Klassischen Modus für Menüoptionen der Eingabe-/Ausgabe-Tools verwenden.
Navigieren Sie zum Bereich Ausgabedaten (1) – Konfiguration > Wählen Sie unter In Datei oder Datenbank schreiben > das Dropdown-Symbol aus.
Wählen Sie Andere Datenbanken > und Snowflake Bulk... aus.
Sie können auch das Eingabedaten-Tool (Klassischer Modus) verwenden, um Ihre Dateien und Datenquellen auszuwählen.
Wenn Sie in den klassischen Modus wechseln möchten, ersetzen Sie Ihr Datenausgabe-Tool mit einem neuen Tool > Wählen Sie den Canvas aus, oder drücken Sie F5 zum Aktualisieren.
Damit das Lesen und Schreiben von Tabellen und Spalten vollständig unterstützt wird, setzen Sie die Alteryx Designer-Option Tabellen-/Feldname im SQL-Stil auf in Anführungszeichen. Mit „in Anführungszeichen“ wird gezielt die Tabelle in der Datenbank ausgewählt, während bei der Auswahl von Kein(e) die Ergebnisse in Großbuchstaben angezeigt werden.
Beachten Sie die folgenden Hinweise, bevor Sie eine Snowflake Bulk-Verbindung konfigurieren:
Daten können nur mit dem Snowflake Bulk Loader geschrieben werden.
Nach dem Schreiben der Daten in die neue Ausgabe entfernt Snowflake Bulk Loader die geschriebenen Daten aus dem S3-Bucket.
Die maximal zulässige Länge für Textfelder beträgt 16.777.216 Byte.
Weitere Informationen finden Sie in der Snowflake-Dokumentation.
Anmerkung
Ab Version 2023 bricht Designer alle nicht abgeschlossenen In-DB-Ausführungen ab, wenn der Workflow lokal abgebrochen wird. Auf diese Weise können Sie die Sperre Ihrer Daten-Pipelines aufheben. Die Funktion verbessert die Datenbankinteraktion insgesamt.
Wählen Sie im ODBC-Datenquellen-Administrator den Snowflake-Treiber aus, und wählen Sie Konfigurieren aus.
Geben Sie Ihre Verbindungseinstellungen und Anmeldedaten ein.
Wählen Sie OK aus, um die Verbindung zu speichern.
Anmerkung
Damit das Lesen und Schreiben von Camel-Case-Tabellen und -Spalten vollständig unterstützt wird, müssen Sie die Alteryx Designer-Option Tabellen-/Feldname im SQL-Stil auf in Anführungszeichen setzen.
So konfigurieren Sie Snowflake-JWT über den ODBC-Treiber:
Erstellen Sie das Token gemäß den Anweisungen aus Snowflake: https://docs.snowflake.com/en/user-guide/key-pair-auth.html.
Setzen Sie den Authentifikator im ODBC-DSN auf SNOWFLAKE_JWT.
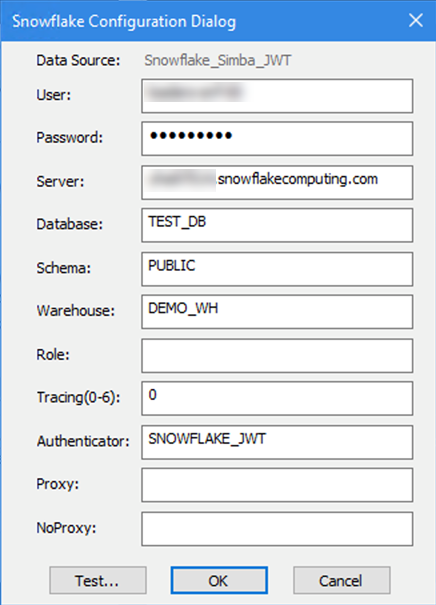
In Alteryx muss die Verbindungszeichenfolge auf den Dateispeicherort weisen, z. B.:
odbc:DSN=Simba_Snowflake_JWT;UID=user;PRIV_KEY_FILE=G:\AlteryxDataConnectorsTeam\OAuth project\PEMkey\rsa_key.p8;PRIV_KEY_FILE_PWD=__EncPwd1__;JWT_TIMEOUT=120Weitere Anweisungen finden Sie in der Snowflake-Dokumentation.
Bulk Loading wird sowohl für Verbindungen mit DSN als auch für DSN-lose Verbindungen unterstützt.
Um den Bulk-Loader mit einer DSN-losen Verbindungszeichenfolge zu konfigurieren, erstellen Sie die Verbindungszeichenfolge manuell. Die Zeichenfolge muss Parameter enthalten, die für das Schreiben in Snowflake und für das Staging erforderlich sind. Die für Snowflake benötigten sind in der Snowflake-Dokumentation zu finden. Die für das Staging erforderlichen Informationen finden Sie unten.
Beispiel für eine Verbindungszeichenfolge:
snowbl:Driver= {SnowflakeDSIIDriver};Server=customerinstance.snowflakecomputing.com;Database=TEST_DB; Warehouse=TEST_WAREHOUSE;schema=PUBLIC;UID=user;PWD=password;Bucket=S3Bucket; Access=IAMAccessKey;Secret=IAMSecretKey;URL=s3.amazonaws.com;Region=us-east-1
Um den Bulk-Loader mit einem DSN zu konfigurieren, verwenden Sie die Benutzeroberfläche, und führen Sie die folgenden Schritte aus:
Wählen Sie das Datenausgabe-Tool aus, und navigieren Sie zum Bereich Datenausgabe (1) – Konfiguration.
Wählen Sie unter In Datei oder Datenbank schreiben das Dropdown-Symbol aus > Navigieren Sie zum Fenster Datenverbindungen, und wählen Sie die Registerkarte Datenquellen > Alle Datenquellen > Snowflake aus > Wählen Sie Bulk aus.
Wählen Sie im Fenster Snowflake Bulk-Verbindung die Registerkarte Lokal aus > Geben Sie Ihre Anmeldedaten in den Flächen für Benutzername (optional) und Kennwort (optional) ein > Wählen Sie OK, um das Popup-Fenster Ausgabetabelle anzuzeigen.
Geben Sie den Namen der Tabelle (oder des Arbeitsblatts) für die angegebene Ausgabedatei ein, entweder mit dem Tabellennamen oder in Form von db.schema.tablename. Dies ist Ihre voll qualifizierte Tabelle.
Wählen Sie unter Optionen im Bereich Ausgabedaten (1) – Konfiguration aus dem Auswahlmenü Tabellen-/Feldname im SQL-Stil entweder in Anführungszeichen oder Kein(e) aus.
Bestimmen Sie unter Datei-/Tabellennamen aus Feld entnehmen, ob Sie das Kontrollkästchen für das Auswahlmenü Suffix an Datei-/Tabellenname anhängen aktivieren möchten. Wenn Sie das Kontrollkästchen aktivieren, wählen Sie in der Dropdown-Auswahl die Option ...
Suffix an Datei-/Tabellenname anhängen
Präfix dem Datei-/Tabellennamen voranstellen
Datei-/Tabellenname ändern.
Gesamten Dateipfad ändern
Wenn Sie das Kontrollkästchen Suffix an Datei-/Tabellennamen anhängen aktivieren, wählen Sie unter Feld enthält Dateiname oder Teil des Dateinamens eine der folgenden Optionen aus:
SEQUENCE_CATALOG
SEQUENCE_SCHEMA
SEQUENCE_NAME
SEQUENCE_OWNER
DATA_TYPE
NUMERIC_PRECISION
NUMERIC_PRECISION_RADIX
NUMERIC_SCALE
START_VALUE
MINIMUM_VALUE
MAXIMUM_VALUE
NEXT_VALUE
INCREMENT
CYCLE_OPTION
CREATED
LAST_ALTERED
KOMMENTAR
Entscheiden Sie, ob Sie das Kontrollkästchen Feld in Ausgabe behalten für die Option aktivieren möchten, die Sie aus dem Auswahlmenü zur Verwendung mit den Daten Ihrer Tabelle ausgewählt haben.
Wählen Sie im Fenster Ausgabedaten – KonfigurationIn Datei oder Datenbank schreiben aus, und wählen Sie Andere Datenbanken > Snowflake Bulk, um das Fenster Snowflake Bulk-Verbindung anzuzeigen.
Wählen Sie einen Datenquellennamen aus, oder wählen Sie ODBC-Administrator, um einen zu erstellen. Siehe ODBC- und OLEDB-Datenbankverbindungen.
Geben Sie bei Bedarf Benutzernamen und Kennwort ein.
Geben Sie in Amazon S3 Ihren AWS-Zugangsschlüssel und Ihren Geheimen AWS-Schlüssel ein.
Wählen Sie unter Verschlüsselung mit geheimem Schlüssel eine Verschlüsselungsoption aus:
Ausblenden: Blendet das Kennwort mit minimaler Verschlüsselung aus.
Für Rechner verschlüsseln: Jeder Benutzer des Rechners hat vollen Zugriff auf die Verbindung.
Für Benutzer verschlüsseln: Der angemeldete Benutzer hat vollen Zugang zu der Verbindung auf einem beliebigen Computer.
Wählen Sie unter Endpunkt eine der folgenden Optionen aus:
Standard: Amazon bestimmt den Endpunkt auf Grundlage des ausgewählten Buckets.
Spezifischer Endpunkt: Geben Sie einen benutzerdefinierten Endpunkt an oder wählen Sie zwischen zuvor eingegebenen Endpunkten aus, um eine S3-Region anzugeben, in der sich der Bucket befindet.
Der S3-Bucket muss sich in der angegebenen S3-Region befinden. Andernfalls wird die folgende Fehlermeldung angezeigt: Der Bucket, auf den Sie zugreifen möchten, muss über den spezifizierten Endpunkt aufgerufen werden. Senden Sie alle künftigen Anfragen an diesen Endpunkt.
Wählen Sie Standard, um die Fehlermeldung zu schließen.
(Optional) Wählen Sie Signature V4 für Authentifizierung verwenden aus, um die Sicherheit über die standardmäßige Signaturversion 2 hinaus zu erhöhen. Diese Option ist für Regionen, in denen die Signaturversion 4 erforderlich ist, automatisch aktiviert. Nach dem 30. Januar 2014 erstellte Regionen unterstützen nur die Signaturversion 4. Für die folgenden Regionen ist eine Authentifizierung nach Signaturversion 4 erforderlich:
USA-Ost (Ohio)
Kanada (zentral)
Asien/Pazifik (Mumbai)
Asien/Pazifik (Seoul)
Europe (Frankfurt)
Europa (London)
China (Peking)
Wählen Sie eine serverseitige Verschlüsselungsmethode zum Hochladen in einen verschlüsselten Amazon S3-Bucket aus. Siehe Entwicklerleitfaden für den Amazon Simple Storage Service.
None (Standard): Es wird keine Verschlüsselungsmethode verwendet.
SSE-KMS: Verwenden Sie serverseitige Verschlüsselung mit von AWS KMS verwalteten Schlüsseln. Sie können auch eine KMS-Schlüssel-ID angeben. Wenn Sie diese Methode auswählen, ist die Option Signatur V4 für Authentifizierung verwenden standardmäßig aktiviert.
Geben Sie Bucket-Name vom AWS-Bucket ein, in dem die Datenobjekte gespeichert sind.
Konfigurieren Sie zusätzliche Dateiformatoptionen im Bereich Ausgabedaten (1) – Konfiguration. Weitere Informationen finden Sie unter Dateiformatoptionen.
Sie haben jetzt drei erweiterte Optionen zur Auswahl, wenn Sie Daten auf Ihrem lokalen Laufwerk bereitstellen!
Wählen Sie das Datenausgabe-Tool aus, und navigieren Sie zum Bereich Datenausgabe (1) – Konfiguration > Navigieren Sie unter In Datei oder Datenbank schreiben zum Fenster Datenverbindungen, und wählen Sie die Registerkarte Datenquellen > Alle Datenquellen > Snowflake > und Bulk aus. Wählen Sie im Fenster Snowflake Bulk-Verbindung > die Registerkarte Lokal aus >
Benutzer-Bereitstellung: die interne Bereitstellung durch Snowflake, die dem Benutzer zugeordnet ist.
Wählen Sie Benutzer aus > Wählen Sie OK aus. Geben Sie im Popup-Fenster Ausgabetabelle den Namen der Tabelle (oder des Arbeitsblatts) für das Ausgabedateiformat ein, der entweder mit dem Tabellennamen oder in Form von db.schema.tablename angegeben wurde. Dies ist Ihre voll qualifizierte Tabelle. Wählen Sie OK aus. Wählen Sie unter Optionen im Bereich Ausgabedaten (1) – Konfiguration aus dem Auswahlmenü Tabellen-/Feldname im SQL-Stil entweder in Anführungszeichen oder Kein(e) aus.
Tabellen-Bereitstellung: interne Bereitstellung durch Snowflake, die der Tabelle zugeordnet ist.
Wählen Sie Tabellen-Bereitstellung aus > Wählen Sie OK aus. Geben Sie im Popup-Fenster Ausgabetabelle den Namen der Tabelle (oder des Arbeitsblatts) für das Ausgabedateiformat ein, der entweder mit dem Tabellennamen oder in Form von db.schema.tablename angegeben wurde. Dies ist Ihre voll qualifizierte Tabelle. Wählen Sie OK aus. Wählen Sie unter Optionen im Bereich Ausgabedaten (1) – Konfiguration aus dem Auswahlmenü Tabellen-/Feldname im SQL-Stil entweder in Anführungszeichen oder Kein(e) aus.
Interne Namen-Bereitstellung: Erstellen Sie in der Snowflake-Datenbank einen CREATE STAGE-Befehl, und führen Sie ihn aus. Geben Sie außerdem den Bereitstellungsnamen in der Tool-Konfiguration an.
Anmerkung
Die maximale Feldgröße beträgt 16 MB. Wenn der Schwellenwert für die Feldgröße überschritten wird, wird ein Fehler ausgegeben, und es werden keine Daten geschrieben.
Komprimierungstyp: Optionen sind entweder „Keine Komprimierung“ oder „Mit GZip komprimieren“.
Keine Komprimierung – Dateien werden als CSV-Datei bereitgestellt und hochgeladen
Mit GZip komprimieren – CSV-Dateien werden mit GZip komprimiert
Blockgröße in MB (1–999): Mit dieser Option können Sie die Größe jeder lokal bereitgestellten CSV-Datei auswählen.
Anmerkung
Die tatsächliche Dateigröße kann aufgrund der unterliegenden Formatierung und Komprimierung von der gewählten Blockgröße abweichen.
Anzahl der Threads (1–99): Diese Option gibt die Anzahl der Threads an, die zum Hochladen von Dateien auf Snowflake verwendet werden. Bei größeren Dateien kann sich die Leistung verbessern, wenn dieser Wert erhöht wird. Wenn 0 eingegeben wird, wird der Snowflake-Standard verwendet (4).
Ab Stage kann jede Kopie in die Tabelle bis zu 1000 Dateien enthalten. Wenn sich mehr als 1000 Dateien in Stage befinden, werden möglicherweise mehrere Kopie-in-Anweisungen angezeigt. Dies ist eine Snowflake-Anforderung für Kopie-in-Anweisungen unter Verwendung von Dateien. Weitere Informationen finden Sie unter Snowflake-Portal.
Weitere Informationen zu Komprimierungstyp, Blockgröße in MB und Optionen zur Anzahl der Threads finden Sie im Snowflake-Portal.