Breaking Changes
The Python SDK v2.0.0 includes breaking changes. Please read on to learn more.
As part of the update, data transferred via RecordTransfer is expected to be sent and received in pyarrow stream format. While a plugin can still receive Designer-based metadata, records come in n msgs with a data field that contains all or part of an arrows data stream and a end_of_chunk boolean to denote when a stream is complete and ready to be converted to a RecordBatch.
The callbacks that you must implement in the V1 Python SDK are described in the Plugin Tool Execution Framework section of the v1 documentation.
With the changes to the way that data is transported in V2 (from synchronous to asynchronous streaming), plugin callbacks and other provider methods have also been changed.
Previously, metadata was explicitly set. It is now optional to set the metadata, and it should be set in the __init__ method instead of when the connection or anchor is received in the on_incoming_connection_complete callback.
Additionally, we now pass Anchor objects around instead of just the connection. We also updated the AMPProvider (now AMPProviderV2) and AMPEnvironment (now AMPEnvironmentV2).
In the V2 SDK, writing to anchors is now a call to the provider instead of on the anchor itself.
self.output_anchor.write(packet)
self.provider.write_to_anchor("Output", table)
The anchors that are supplied as part of the tool config are now a property of the provider itself.
self.provider.get_input_anchor(name) or self.provider.get_output_anchor(name)
self.provider.incoming_anchors[name] or self.provider.outgoing_anchors[name]
The new callback on_incoming_connection_complete receives an anchor of type Anchor, which is a named tuple that contains the anchor.name and anchor.connection, instead of the input connection.
on_input_connection_opened(self, input_connection: AMPInputConnection)
on_incoming_connection_complete(self, anchor
This method now receives a pyarrows.Table (pyarrow.Table) instead of an input connection. The data is directly passed in instead of having to read the data from the connection. It's also in a different form to improve performance.
on_record_packet(self, input_connection: AMPInputConnection)
on_record_batch(table: pa.Table, anchor: Anchor)
translate_msg() was previously a synchronous blocking call. It still behaves synchronously but now you have an option to call translate_msg_use_callback() with an extra parameter that is the callback function. This method is a non-blocking method.
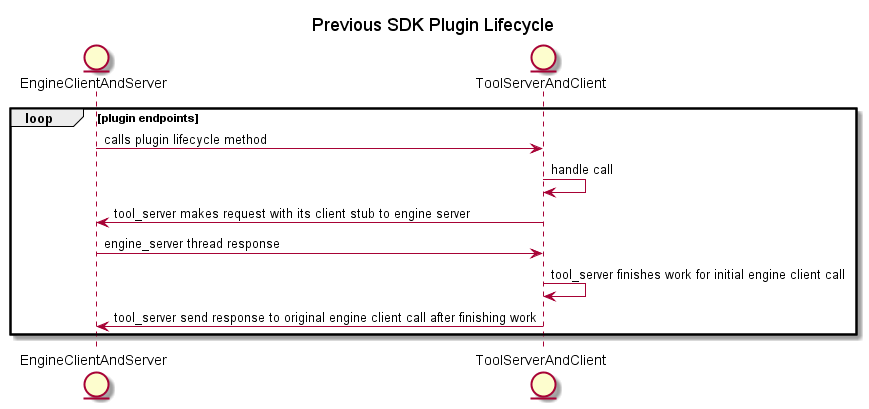
Before the transport updates, RPC calls were via synchronous call and response messages. As of v2.0.0, messages are now sent using bidi streaming. This essentially creates the same double client-server relationship but over 1 comms channel with 1 server. In addition, where each call was previously blocked until a response was given, this is no longer the case. Each end of the stream can be freely written to or read from without blocking, and a write does not need a response to be "complete".
engine_client_calls_lifecyle_rpc_event → tool_server handles call → tool_server makes request with its client stub to engine server → engine server thread responds → tool_server finishes work for initial engine client call → send response to engine_client_call → engine ready to make another lifecycle client call.
engine_client_opens_stream → engine and plugin send messages over stream → stream closes when both stop writing.

The new control stream defines messages for non-record-related rpcs. ControlIn/ControlOut wraps the same messages for Designer IO and runtime management that currently exist, to provide the same functionality (translate_message, outgoing_message, initialize_plugin) over the Control stream.
RecordIn/RecordOut are used to send records over the stream in n chunks.