Nell'articolo Alteryx AMP Engine abbiamo spiegato cos'è Alteryx Engine e il nuovo Alteryx Multi-threaded Processing (AMP). Ora approfondiamo le principali differenze tra i due.
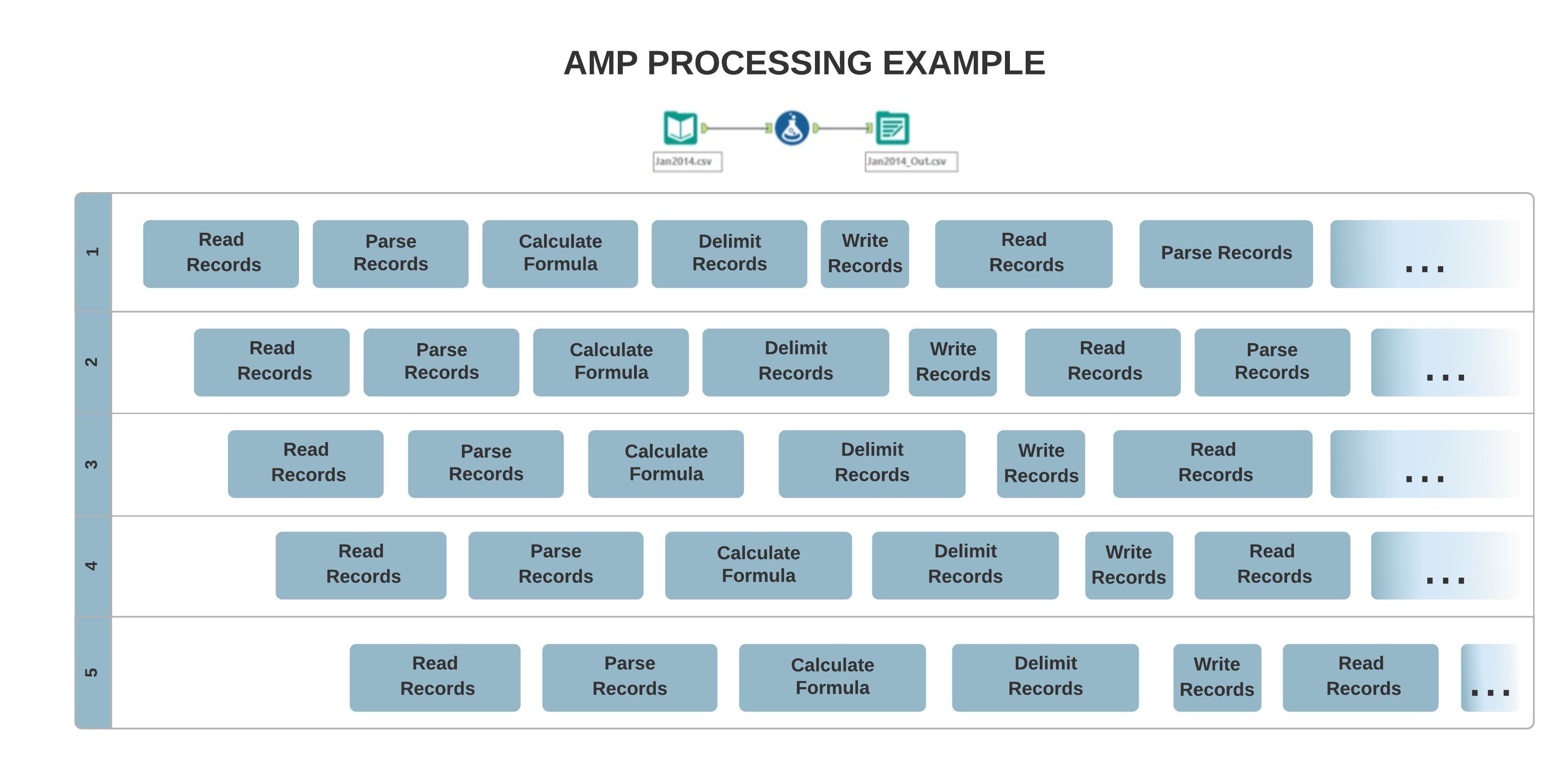
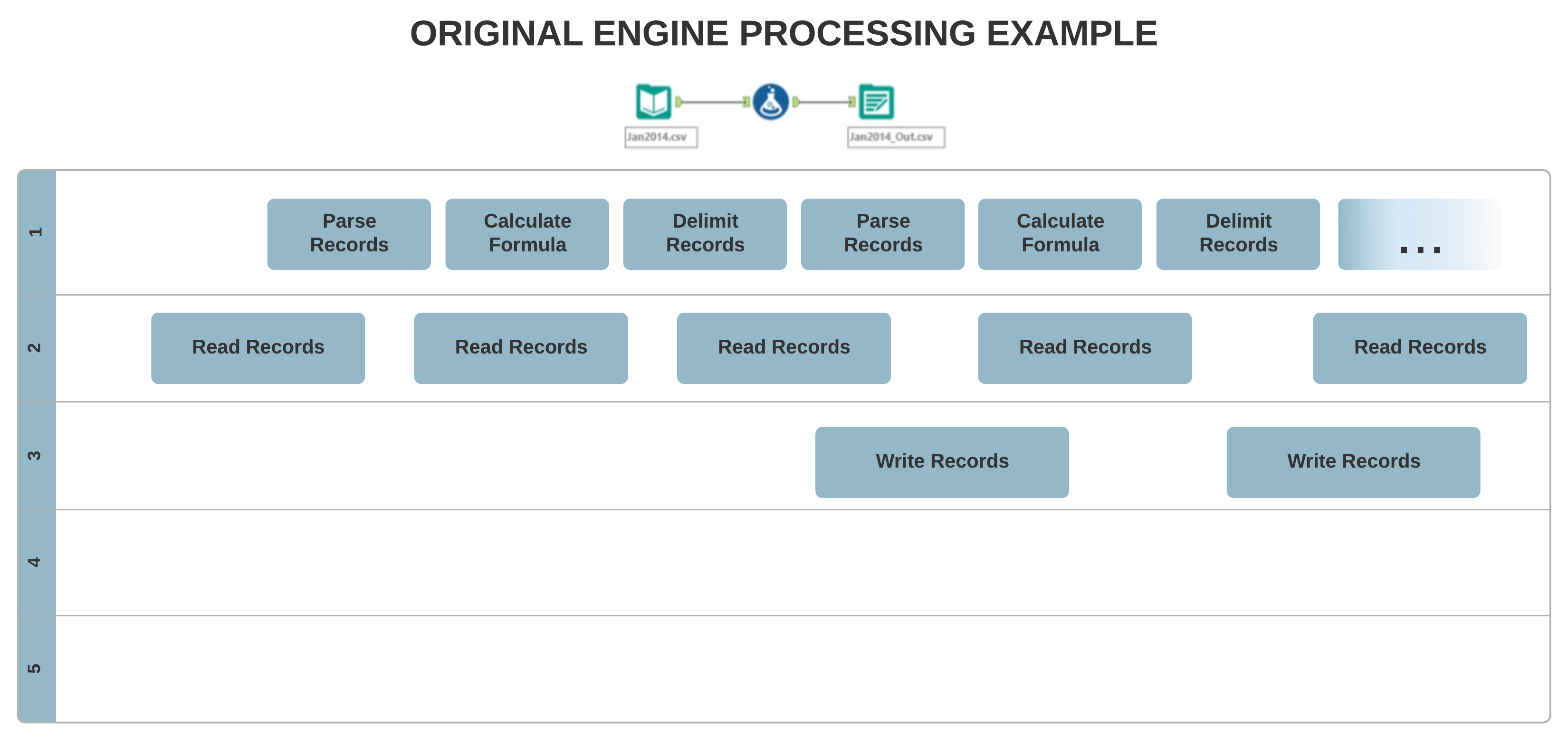
L'architettura dell'engine originale consente principalmente l'elaborazione a thread singolo, in cui i dati vengono elaborati record per record in sequenza. D'altra parte, il nuovo concetto AMP consente un'elaborazione massicciamente multi-thread. Registra il processo in pacchetti da 4 MB per un tempo di esecuzione più rapido e in parallelo, operazione che può influire sull'ordine dei record di output.
Il file CSV contenente un campo con le nuove righe tra virgolette restituisce un errore se non abiliti l'opzione aggiuntiva Solo AMP: i campi con le virgolette possono avere nuove righe al loro interno.
L'impostazione di runtime per la configurazione del flusso di lavoro Limite di record per tutti gli input è abilitata con AMP per i seguenti strumenti:
Dati di input
Input di testo
Genera righe
Input di Macro
Il supporto del limite di record nello strumento Input dinamico da parte di AMP è stato aggiunto a partire dalla patch 2 della release 2021.1.
Diversi strumenti potrebbero generare i record in un ordine diverso rispetto all'engine originale quando un flusso di lavoro viene eseguito con AMP Engine. Alcuni di questi strumenti sono:
Campi incrociati
Pulizia dei dati (durante la rimozione di righe nulle)
Collega
Combinazione multipla
Formula con più righe
Costruzione Poly
Somma cumulativa
Ordina (quando l'ordinamento del dizionario è utilizzato con caratteri speciali)
Riepiloga (quando utilizzi Raggruppa per)
Riquadro
Unione
Unico
Se il flusso di lavoro richiede che i record degli strumenti sopra indicati siano in un ordine specifico per le operazioni a valle, la modalità di compatibilità dell'engine è disponibile per mantenere lo stesso ordinamento dell'engine originale. Questa opzione deve essere utilizzata dopo un'attenta considerazione del flusso di lavoro specifico, principalmente durante la migrazione dei flussi di lavoro creati con l'engine originale per l'esecuzione con AMP Engine.
A tale scopo, la funzionalità o la configurazione specifica che non è stata convertita in AMP ripristina lo strumento Engine originale. Pertanto, i flussi di lavoro che contengono sia strumenti convertiti da AMP che strumenti non convertiti vengono eseguiti senza problemi con AMP.
Se hai domande su quali strumenti potrebbero essere stati convertiti in AMP, vedi: Utilizzo degli strumenti con AMP.
Con l'engine originale, gli strumenti sono più connessi con gli strumenti a valle e smetterebbero di funzionare in assenza di elementi a valle. Con l'AMP in esecuzione parallela, gli utensili potrebbero non arrestarsi con il vuoto a valle. Il presupposto è che se non sono presenti elementi a valle, il flusso di dati non viene preso in considerazione. I dati nel messaggio di log sono unicamente a scopo informativo. Se il numero di record è importante per te, puoi inserire uno strumento Test nel flusso e fare in modo che restituisca un messaggio di errore se non ottiene il numero giusto di record.
Un file YXDB scritto con AMP Engine viene letto più velocemente di un file YXDB scritto con l'engine originale.
Con AMP è possibile utilizzare i formati di file XLSX, CSV, YXDB e SQLite, che supportano dati di lettura multithread.
La conversione dei record e pacchetti tra l'engine originale e AMP influisce sulle prestazioni durante la lettura dei file zip. Ciò potrebbe causare una lettura molto più lenta dei file zip di grandi dimensioni con AMP.
Tip
Quando viene aperto in un editor di testo, un file YXDB scritto con AMP ha "Alteryx e2 Database file" all'inizio del contenuto del file. Un file scritto con l'engine originale mostrerà solo "Alteryx Database File" nella stessa posizione.
Per migliorare le prestazioni dell'engine originale, facendo in modo che AMP scriva un file YXDB creato con l'engine originale, vai nel menu Dati di output - Configurazione, dove puoi creare una versione del file YXDB compatibile con Designer 18.1 e versioni precedenti.
Lo strumento
SE necessario, una soluzione alternativa consiste nel rimuovere i dati spaziali dai record utilizzando lo strumento
La profilatura delle prestazioni per strumento con AMP è disponibile con Designer 2021.3 e versioni successive.
AMP passa i dati da e verso R nel formato dell'engine originale. Questa doppia conversione richiede tempo. L'esecuzione di un singolo strumento R può essere più lenta con AMP rispetto all'engine originale, ma avverrà più velocemente se si eseguono più rami contemporaneamente.
AMP affronta un problema storico in cui le dimensioni del campo potrebbero non essere sufficientemente grandi quando elaborate da uno strumento a valle. Non è necessario aggiungere gli strumenti Seleziona per modificare i tipi di dati quando i dati risultanti superano la lunghezza del tipo di dati originale. AMP crea il campo delle dimensioni massime per stringhe e numeri interi in modo che le operazioni successive dispongano dello spazio necessario per contenere valori a valle più grandi.
Anche se lo strumento Limita non è stato completamente convertito in AMP, è possibile utilizzarlo insieme allo strumento Download (prima strumento Limita).
Lo strumento Corrispondenza sfocata può avere risultati diversi tra l'engine originale e AMP. I record AMP vengono associati utilizzando un metodo alternativo. L'ordine di corrispondenza potrebbe essere diverso e anche l'output potrebbe essere in ordine inverso. Esiste un problema di prestazioni noto a causa del quale Corrispondenza sfocata risulta avere prestazioni inferiori con AMP rispetto all'engine originale.
AMP utilizza gli standard di codifica Unicode e Perl, dove i caratteri $, +, <, =, >, ^, | e ~ non sono riconosciuti come punteggiatura. Quando utilizzi la funzione REGEX_Replace o lo strumento RegEx per filtrare la punteggiatura con il set Regex [[:punct:]], con AMP è necessario modificare l'espressione.
REGEX_REPLACE([_CurrentField_],'[[:punct:]]|[\$\+<=>\^`\|~]','')
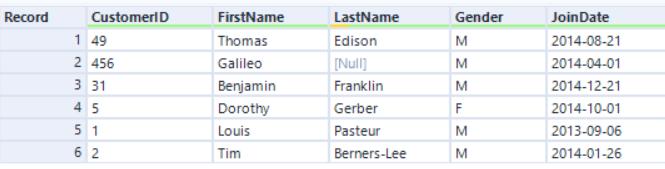
L'algoritmo

Input sinistro:
Ingresso destro:
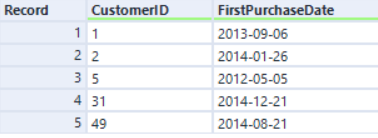
Se colleghiamo in base a CustomerID con l'engine originale, l'ordine dei record avviene in base al campo CustomerID:

Con AMP i record sono gli stessi ma in un ordine diverso:

Se è necessario un ordinamento nell'output di collegamento, aggiungi lo strumento Ordina dopo Collega o attiva l'impostazione Modalità di compatibilità dell'engine in Configurazione del flusso di lavoro > Runtime, sotto l'impostazione Usa AMP Engine.
La differenza tra engine originale e AMP può verificarsi quando uno strumento all'interno della macro segnala un errore. Essendo a thread singolo, l'engine originale si arresta se si verifica un errore nella macro. AMP funziona fino a quando l'output iterativo è vuoto o si verifica il numero massimo di iterazioni. È possibile riscontrare le seguenti situazioni a causa di un numero maggiore di iterazioni:
Il numero di errori (se presenti) può essere maggiore con AMP.
Il numero di record potrebbe essere maggiore con AMP.
Lo schema di output potrebbe essere diverso con AMP.
Le funzioni ConvertFromCodePage e ConvertToCodePage nello strumento Formula accettano una stringa come parametro e restituiscono una stringa come risultato. Pertanto, non è possibile capire come viene decodificata la stringa. C'è una differenza nell'output dello strumento Formula con queste funzioni utilizzate con l'engine originale e AMP.
Una diversa rappresentazione binaria dei dati di input è causata dall'uso interno di stringhe codificate UTF-8 da parte di AMP. Quando vengono importati i dati con una codifica diversa, non è possibile ripristinare i dati originali. L'engine originale memorizza le stringhe con codifica Latin-1 o UTF-16 che sono state utilizzate come buffer e consente di convertire correttamente i dati.
Gli ulteriori componenti di Formula non sono ancora supportati con AMP. Se è necessario eseguire un flusso di lavoro contenente la funzionalità del componente aggiuntivo Formula, eseguilo utilizzando l'engine originale.
Le app che usano lo strumento Mappa per selezionare da un livello di riferimento spaziale in App analitica devono continuare a usare l'engine originale.
Con l'engine originale, "Aspettarsi flussi uguali" rimane una macro CReW. Con AMP viene eseguito come strumento nativo.
Alcuni flussi di lavoro leggono da un file e poi ci riscrivono. Ciò richiede il sequenziamento per garantire che la lettura sia completa prima dell'inizio della scrittura. Analogamente, un flusso di lavoro che desidera scrivere più fogli in un file con estensione XLSX deve scrivere i fogli uno alla volta. Alteryx Designer fornisce uno strumento BUD (Blocca fino alla conclusione) che consente di partizionare il lavoro in fasi che non si intralceranno a vicenda.
La stessa soluzione alternativa è applicabile per lo strumento E-mail quando utilizzi file di output dei rami precedenti come allegati. Devi attendere la fine dell'elaborazione dei dati per aggiungere un allegato allo strumento E-mail.
Quando lavori su un flusso di lavoro con più rami (in gran parte flussi separati dagli input agli output), posiziona lo strumento BUD nel ramo del flusso di lavoro con l'ID dello strumento di input numerato più basso. In questo modo ogni ramo successivo attende di essere eseguito fino a quando non viene eseguito il ramo precedente e lo strumento funziona come previsto.
Per ulteriori informazioni sulla funzionalità specifica degli strumenti, vedi Utilizzo degli strumenti con AMP.