Im Artikel Alteryx AMP Engine behandeln wir die Alteryx Engine und die neue Alteryx Multi-threaded Processing (AMP). Hier gehen wir ausführlicher auf die Hauptunterschiede zwischen den beiden ein.
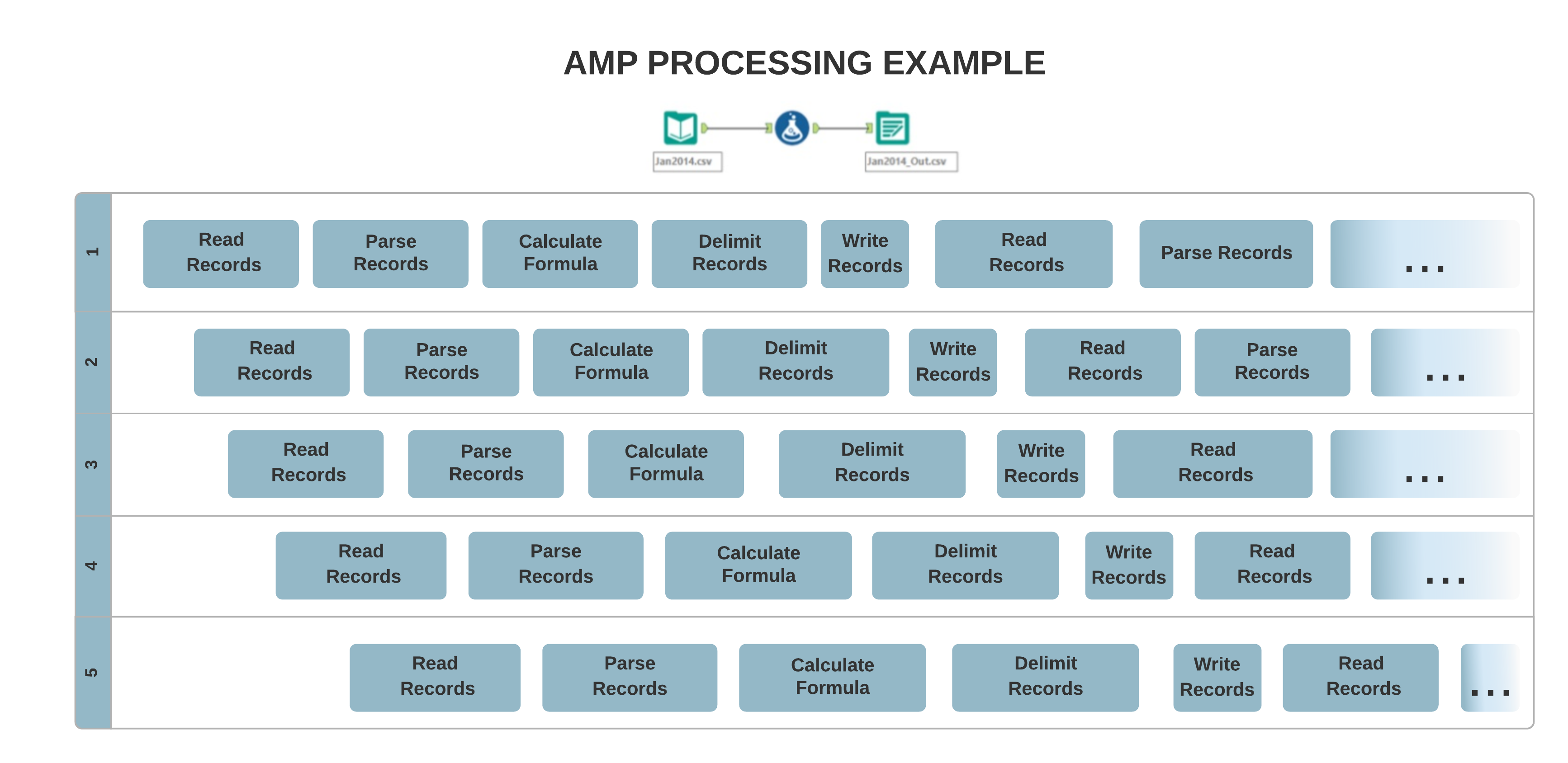
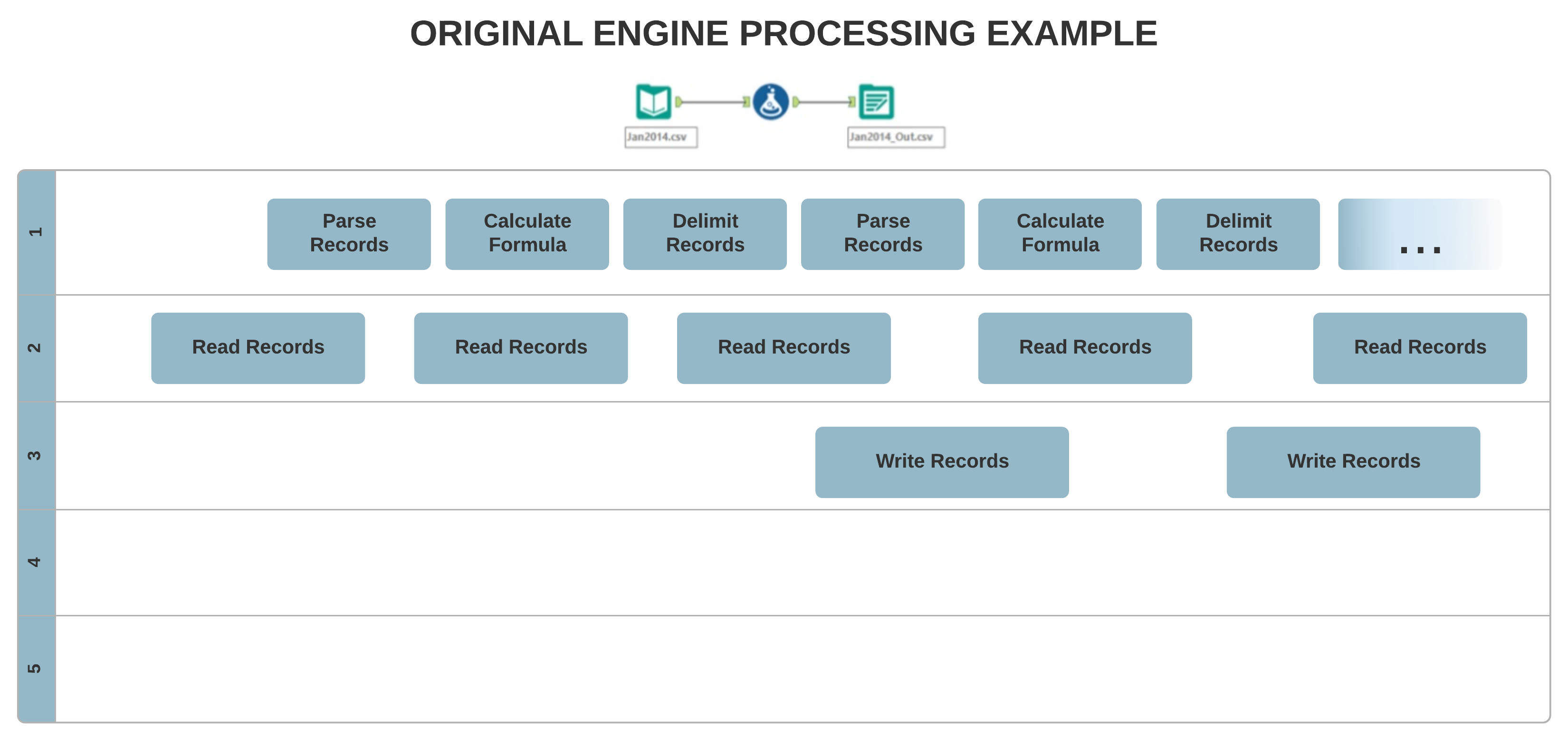
Die Original-Engine-Architektur ermöglicht meist eine Single-Threaded-Verarbeitung, bei der Ihre Daten Datensatz für Datensatz sequentiell verarbeitet werden. Im Gegensatz dazu ermöglicht das neue AMP-Konzept eine massive Multithreading-Verarbeitung. Die Datensätze werden in 4-MB-Paketen verarbeitet, um die Laufzeit zu verkürzen, und zwar parallel, wodurch die Reihenfolge der ausgegebenen Datensätze beeinflusst werden kann.
CSV-Dateien, die ein Feld mit Zeilenumbrüchen in Anführungszeichen enthalten, schlagen fehl, wenn Sie die zusätzliche Option Nur AMP: Felder in Anführungszeichen können Zeilenumbrüche enthalten nicht aktivieren.
Die Laufzeiteinstellung für die Workflow-Konfiguration Datensatzlimit für alle Eingaben ist bei AMP für die folgenden Tools aktiviert:
Eingabedaten
Texteingabe
Zeilen generieren
Makroeingabe
AMP-Unterstützung für das Datensatzlimit auf Tool-Ebene im Dynamische-Eingabe-Tool wurde bei 2021.1, Patch 2 und allen nachfolgenden Versionen hinzugefügt.
Wenn ein Workflow mit der AMP Engine ausgeführt wird, geben einige Tools Datensätze unter Umständen in einer anderen Reihenfolge aus als die Original-Engine. Zu diesen Tools gehören unter anderem:
Kreuztabelle
Datenbereinigung (beim Entfernen von Nullzeilen)
Verknüpfen
Mehrere verknüpfen
Mehrzeilige Formel
Poly-Erstellung
Laufende Summe
Sortieren (wenn Wörterbuchsortierung mit Sonderzeichen verwendet wird)
Zusammenfassen (bei Verwendung von „Gruppieren nach")
Kachel
Zusammenführung
Einmalig
Wenn in Ihrem Workflow Datensätze aus den oben genannten Tools für nachgeschaltete Vorgänge in einer spezifischen Reihenfolge vorliegen müssen, können Sie die Engine-Kompatibilitätsmodus-Einstellung nutzen, um dieselbe Reihenfolge wie bei der Original-Engine beizubehalten. Verwenden Sie diese nach sorgfältiger Prüfung des spezifischen Workflows, vor allem bei der Migration von Workflows, die mit der Original-Engine erstellt wurden, damit diese mit der AMP Engine ausgeführt werden können.
Bei spezifischen Funktionen oder Konfigurationen, die nicht in AMP konvertiert wurden, stellt Designer das Tool automatisch wieder so her, wie es in der Original-Engine war. Daher werden Workflows, die sowohl AMP-konvertierte als auch nicht konvertierte Tools enthalten, nahtlos mit AMP ausgeführt.
Wenn Sie Fragen dazu haben, welche Tools auf AMP umgestellt wurden, gehen Sie zu Tool-Verwendung mit AMP.
Mit der Original-Engine sind Tools stärker verbunden und halten die Ausführung an, sobald es nichts Nachgeschaltetes gibt. Beim AMP-Parallelbetrieb kann es vorkommen, dass die Tools nicht angehalten werden, wenn nichts nachgeschaltet ist. Es wird davon ausgegangen, dass der Datenstrom nicht berücksichtigt wird, wenn keine Tools nachgeschaltet sind. Die Protokollmeldung dient nur zur Information. Wenn Ihnen die Anzahl der Datensätze im Datenstrom wichtig ist, können Sie ein Test-Tool verwenden und eine Fehlermeldung ausgeben lassen, wenn die Anzahl der Datensätze nicht korrekt ist.
Eine mit der AMP Engine geschriebene YXDB-Datei wird schneller eingelesen als eine mit der Original-Engine geschriebene YXDB-Datei. Die mit der Original-Engine geschriebene YXDB-Datei wird bei aktivierter AMP Engine langsamer gelesen. Die Formate sind jedoch weiterhin kompatibel.
Verwenden Sie XLSX-, CSV-, YXDB- und SQLite-Dateiformate mit AMP – sie unterstützen eingelesene Multi-Threading-Daten.
Beim Lesen von Zip-Dateien entstehen Leistungskosten bei der Umwandlung von Datensätzen und der Verpackung zwischen der Original-Engine und AMP. Dies könnte dazu führen, dass größere Zip-Dateien mit AMP deutlich langsamer gelesen werden.
Hinweis
Wenn eine mit AMP geschriebene YXDB-Datei in einem Texteditor geöffnet wird, steht „Alteryx e2 Database file" ganz am Anfang des Dateiinhalts. Bei einer Datei, die mit der Original-Engine geschrieben wurde, ist an der gleichen Stelle „Alteryx Database File“ zu sehen.
Um die Leistung der Original-Engine zu verbessern (indem AMP eine YXDB-Datei schreibt, die mit der Original-Engine erstellt wurde), navigieren Sie zum Konfigurationsmenü des Datenausgabe-Tools. Dort finden Sie die Option, eine Version der YXDB-Datei zu erstellen, die mit Designer 18.1 und älter kompatibel ist.
Das Ausgabe-Tool verhält sich unterschiedlich bei Datensätzen, die SpatialObj-Daten enthalten, je nachdem, ob eine CSV-Datei mit der Original-Engine oder mit der AMP Engine gespeichert wird. Während AMP beim Speichern als CSV-Datei SpatialObj-Daten in die Datei schreibt, ist dies bei der Original-Engine nicht der Fall. Dieser Unterschied führt zu Unterschieden bei der Dateigröße und Sie stellen möglicherweise Leistungseinbußen fest.
Falls erforderlich, können Sie die Geodaten mithilfe des Datenfelder-auswählen-Tools aus den Datensätzen entfernen. Dadurch können beide Engines die Ausführung in einer ähnlichen Zeit abschließen.
Die Leistungsprofilerstellung pro Tool mit AMP ist ab Designer Version 2021.3 verfügbar.
AMP leitet Daten an und von R im Original-Engine-Format weiter. Diese doppelte Konvertierung nimmt Zeit in Anspruch. Die Ausführung eines einzelnen R-Tools kann mit AMP langsamer sein als mit der Original-Engine, ist jedoch schneller, wenn mehr als ein Zweig gleichzeitig ausgeführt wird.
AMP behebt ein historisches Problem, bei dem die Größe des Feldes bei der Verarbeitung durch ein nachgeschaltetes Tool möglicherweise nicht groß genug ist. Sie müssen keine Datenfelder-auswählen-Tools hinzufügen, um Datentypen zu ändern, wenn die resultierenden Daten die Länge des ursprünglichen Datentyps überschreiten. AMP erstellt das Feld für die maximale Größe von Zeichenfolgen und Ganzzahlen, damit nachfolgende Vorgänge den notwendigen Platz haben, um größere nachgeschaltete Werte aufzunehmen.
Obwohl das Drosselung-Tool nicht vollständig auf AMP umgestellt wurde, können Sie es in Kombination mit dem Herunterladen-Tool (Drosselung als Erstes) verwenden.
Fuzzy-Übereinstimmung kann zu unterschiedlichen Ergebnissen zwischen der Original- und der AMP Engine führen. AMP-Datensätze werden nach einer alternativen Methode abgeglichen. Die Reihenfolge der Übereinstimmung kann unterschiedlich sein und die Ausgabe kann auch in umgekehrter Reihenfolge erfolgen. Es gibt ein bekanntes Leistungsproblem, bei dem das Fuzzy-Übereinstimmung-Tool im Vergleich zur Original-Engine mit AMP eine geringere Leistung erbringt.
AMP verwendet Unicode- und Perl-Codierungsstandards, wobei die Zeichen $, +, <, =, >, ^, | und ~ nicht als Interpunktion gelten. Wenn Sie die Formelfunktion REGEX_Replace oder das RegEx-Tool verwenden, um Interpunktion mit dem RegEx-Satz [[:punct:]] zu filtern, müssen Sie mit AMP den Ausdruck ändern.
REGEX_REPLACE([_CurrentField_],'[[:punct:]]|[\$\+<=>\^`\|~]','')
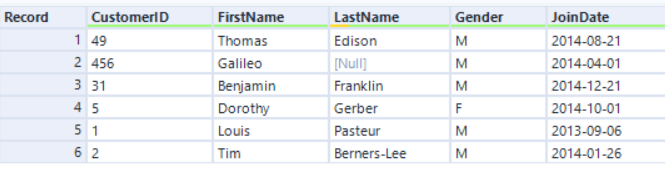
Der Join-Algorithmus mit der Original-Engine basiert auf einer Sortierungs-Zusammenführungs-Verknüpfungsmethode, bei der die Datensätze immer in einer sortierten Reihenfolge vorliegen. Der neue Join-Algorithmus von AMP basiert auf einer Hash-Join-Methode, wodurch die Reihenfolge der Datensätze ungeordnet ist. Zum Beispiel:

Linke Eingabe:
Rechte Eingabe:
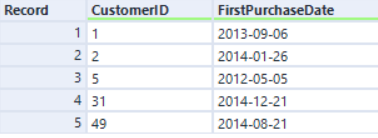
Wenn wir über die CustomerID mit der Original-Engine verknüpfen, wird die Reihenfolge der Datensätze nach dem CustomerID-Feld sortiert:

Mit AMP sind die Datensätze identisch, jedoch in einer anderen Reihenfolge:

Wenn Sie eine sortierte Reihenfolge in der Verknüpfungsausgabe benötigen, fügen Sie das Daten-sortieren-Tool nach dem Verknüpfen-Tool hinzu oder aktivieren Sie den Engine-Kompatibilitätsmodus. Diesen Modus finden Sie unter Workflow-Konfiguration > Laufzeit, unterhalb der Einstellung AMP Engine verwenden.
Der Unterschied zwischen der Original-Engine und AMP kann auftreten, wenn ein Tool innerhalb des Makros einen Fehler meldet. Da es sich um einen Single-Threaded-Prozess handelt, stoppt Original-Engine bei einem Fehler im Makro. AMP läuft so lange, bis die Iterationsausgabe leer ist oder die maximale Anzahl von Iterationen erreicht ist. Diese Situationen können aufgrund einer höheren Anzahl von Iterationen auftreten:
Die Anzahl der Fehler (falls vorhanden) kann mit AMP höher sein.
Die Anzahl der Datensätze kann mit AMP höher sein.
Das Ausgabeschema kann mit AMP anders sein.
Die Funktionen ConvertFromCodePage und ConvertToCodePage im Formel-Tool akzeptieren Strings als Parameter und geben Strings als Ergebnis zurück, sodass es nicht möglich ist, zu unterscheiden, wie der String codiert ist. Es gibt einen Unterschied in der Ausgabe des Formel-Tools, wenn diese Funktionen mit der Original-Engine und AMP verwendet werden.
Die unterschiedliche binäre Darstellung der Eingabedaten wird durch die AMP-interne Verwendung von UTF-8-codierten Zeichenfolgen verursacht. Wenn die Daten mit einer unterschiedlichen Codierung importiert werden, gibt es keine Möglichkeit, die ursprünglichen Daten wiederherzustellen. Die Original-Engine speichert Zeichenfolgen als Latin-1- oder UTF-16-codierte Zeichenfolgen, die als Puffer verwendet wurden und die korrekte Rückkonvertierung von Daten ermöglichen.
Formel-Add-Ins werden von AMP noch nicht unterstützt. Wenn Sie einen Workflow mit Formel-Add-In-Funktionalität ausführen müssen, führen Sie ihn mit der Original-Engine aus.
Apps, die das Karten-Tool zur Auswahl aus einer Geo-Referenzebene in einer Analyse-App verwenden, sollten weiterhin die Original-Engine verwenden.
Mit der Original-Engine bleibt „Expect Equal" ein CReW-Makro. Mit AMP läuft es als ein natives Tool.
Manche Workflows lesen aus einer Datei und schreiben dann in diese zurück. Dies erfordert eine Sequenzierung, um sicherzustellen, dass der Lesevorgang abgeschlossen ist, bevor der Schreibvorgang beginnen kann. In ähnlicher Weise muss ein Workflow, der mehrere Blätter in eine .xlsx-Datei schreiben möchte, die Blätter nacheinander schreiben. Alteryx Designer bietet ein Befehlsausführung-blockieren-Tool (Block Until Done, BUD) an, um die Arbeit in Phasen zu unterteilen, die sich nicht gegenseitig behindern.
Dieselbe Problemumgehung gilt für das E-Mail-Tool, wenn Sie (eine) Ausgabedatei/en aus (einer) vorherigen Verzweigung/en als Anhang verwenden. Sie müssen warten, bis die Datenverarbeitung abgeschlossen ist, und können dann den Anhang zum E-Mail-Tool hinzufügen.
Wenn Sie an einem Workflow mit mehreren Zweigen arbeiten (weitgehend getrennte Ströme von Eingaben zu Ausgaben), ordnen Sie das Befehlsausführung-blockieren-Tool (BUD) im Workflow-Zweig mit der niedrigsten nummerierten Eingabedaten-Tool-ID. Dadurch wird sichergestellt, dass jede nachfolgende Verzweigung erst dann ausgeführt wird, wenn die vorherige Verzweigung abgeschlossen ist und das Tool wie erwartet funktioniert.
Weitere Informationen zu spezifischen Tool-Funktionen finden Sie unter Tool-Nutzung mit AMP.