
集計プロセス
次の一覧は、 集計ツール で実行できる集計プロセスまたはアクションの種類について説明します。
グループ化 : 指定したフィールドの値が同一のデータベースレコードを単一のレコードに結合します。次に、グループ内のレコードから得られたすべてのデータが集計されます。BLOB 型または空間オブジェクト型以外には、このオプションがあります。グループ化するフィールドが指定されていない場合、ファイル全体が集計されます。
合計 : グループの合計値を返します。合計は、グループのすべての値を加算することで計算されます。
カウント : グループ内のレコードの数を返します。
非 Null のカウント : 「カウント」と同じですが、この場合、Null 以外 のレコードのみをカウントします。Null は、レコードに値が設定されていないことを意味します。これはゼロまたは空の文字列とは異なります。
重複を除いてカウント : グループ内のユニークなレコードの数を返します。
非 Null を重複を除いてカウント : 「重複を除いてカウント」と同じですが、Null ではないレコードの数のみをカウントします。Null は、レコードに値が設定されていないこと (ゼロまたは空の文字列とは異なる) を意味します。
Null のカウント : 「カウント」と同じですが、この場合、null のレコードのみをカウントします。Null は、レコードに値が設定されていないことを意味します。これはゼロまたは空の文字列とは異なります。
最小 : 最小値を返します。
最大 : 最大値を返します。
最初 : レコード位置に基づいて、グループ内の最初のレコードを返します。
最後 : レコード位置に基づいて、グループ内の最後のレコードを返します。
以下に、集計用に選択したフィールドタイプに基づいて、カテゴリにグループ化された追加の集計プロセスを示します。
ファイナンス
正味現在価値 (NPV) : グループの正味現在価値を計算します。資金調達費用がが満たされた時点で、現在の価値でキャッシュフローの超過または不足を測定します。 NPVプロパティ には、次のものが含まれます。
割引率 (期間ごと) : 割引率 (パーセント)既定値は 8% です。
定期的でない投資の正味現在価値 (XNPV) : 一連の日付のグループの正味現在価値を計算します。 XNPVプロパティ には、次のものが含まれます。
融資利率 : 融資利率をパーセンテージで表示します。既定値は 8% です。
日付フィールド : 関連付けられた日付を含むフィールド。
内部収益率 (IRR) : グループの内部収益率を計算します。投資の内部収益率は、投資額が将来得られる投資の利益につながる収益率を指します。これは、投資から得られるすべての利益は金銭の時間的価値に固有であり、投資がこの利益でゼロの正味現在価値を持つことを意味します。
定期的でない投資の内部収益率 (XIRR) : 一連の日付のグループの内部収益率を計算します。XIRR プロパティ には、次のものが含まれます。
日付フィールド : 関連付けられた日付を含むフィールド。
修正内部収益率 (MIRR) : 内部収益率の修正と、IRR に関するいくつかの問題を解決することを目的としています。MIRRは、投資の魅力度の金融尺度です。MIRR プロパティ には、次のものが含まれます。
融資利率 : 融資率をパーセンテージで表示します。既定値は 8% です。
再投資率 : 再投資率をパーセンテージで表示します。既定値は 8% です。
定期的でない投資の修正内部収益率 (MXIRR) : 一連の日付のグループに対する修正内部収益率を計算します。MXIRR プロパティ には次のものが含まれます。
融資利率 : 融資率をパーセンテージで表示します。既定値は 8% です。
再投資率 : 再投資率をパーセンテージで表示します。既定値は 8% です。
日付フィールド : 関連付けられた日付を含むフィールド。
数値
平均 : グループの平均値を計算します。平均は、すべての値の合計を値の総数で割って計算されます。
総乗(Product) : グループの積を計算します。この総乗(Product)は、指定されたグループ内のすべての数値を乗算して計算されます。
パーセンタイル : グループの指定したパーセンタイル値を計算します。パーセンタイルは、データをソートし、指定されたパーセンタイルとソートされた配列内のその位置に関連した行の値を返して計算されます。最大値は 100 パーセンタイル、最小値は 0 パーセンタイルで、中央値は 50 パーセンタイル、 25 パーセンタイルは中央値と最小値の中間の値です。パーセンタイル プロパティには、次のものが含まれます。
返すパーセンタイルを指定します。既定値は 50%です。
中央値 : グループの中央値を計算します。グループの中央値は、値が順番にソートされるときの「中央の数字」です。偶数のスコアリングがある場合は中央に数字がないので、中央の 2 つの数字が平均されます。
最頻値 : グループの最頻値を計算します。一連の数の最頻値は、値のグループで最も頻繁に発生する最小の数値です。すべての値がユニークな場合、最小の数字が返されます。
標準偏差 : グループの標準偏差を計算します。標準偏差は、統計で使用されるデータの散らばり具合 (ばらつき) の大きさを表す指標です。
分散 : グループのバリエンス (分散) を計算します。分散は、標準偏差を取り込み、それ自体に時間 (StdDev ^ 2) を掛けることによって計算されます。
0 を無視 : 値が 0 のレコードを無視して、上で説明した数値プロセスを計算します。
文字列
空白をカウント : 空白または空の値を持つグループ内のレコード数をカウントします。
空白以外をカウント : 空白または空の値を持たないグループ内のレコード数をカウントします。
連結 : グループ内のすべてのレコードを取得し、文字列の連結を行います。連結プロパティ には、次のものがあります。
開始 : 指定された文字は、連結された文字列の先頭に表示されます。既定では空白のままです。
区切り記号 : 指定された文字は、連結文字列の各値の間に表示されます。既定はコンマです。
終了 : 指定された文字は、連結された文字列の末尾に表示されます。既定では空白のままです。
注記
開始要素、区切り記号要素、終了要素は、アクションが適用される各フィールドに対して指定する必要があります。任意の文字または文字列を入力することも、空白のままにすることもできます。サポートされるエスケープ文字は次のとおりです。
\n (新しい行)
\t (タブ)
\r (キャリッジリターン)
\s (空白文字)
最長 : グループの最長文字列値を返します。
最頻値 : 文字列値の最頻値を返します。一連の文字列値の最頻値は、値のグループで最も頻繁に発生する最小の文字列です。すべての値が固有である場合は、最小の文字列が返されます。最小文字列は、昇順のソート順で最初の文字列です。
最短 : グループの最短文字列値を返します。
空間
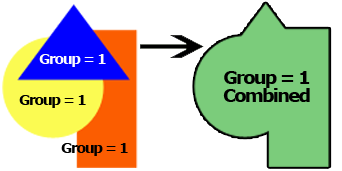
結合 : グループ内のすべての空間オブジェクトの面積を結合します。
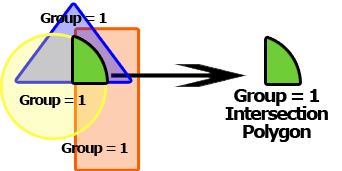
交差を作成 : グループの空間オブジェクトの重なり合うすべてのエリアを識別し、そのオーバーラップのみで構成されるポリゴンを作成します。これは、集計されているグループに重なり合うポリゴンが含まれていない場合は、何も返されないことを意味します。
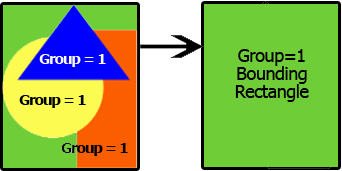
境界矩形を作成 : グループ内のすべての空間オブジェクトの地理的範囲を識別し、それらの範囲に外接する四角形を描画します。
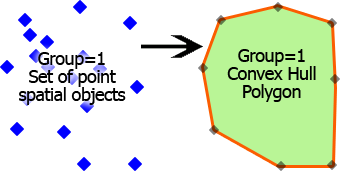
凸包を作成 : ポイントのグループの凸包を識別します。凸包のポリゴンは、一群の点を含むように描くことができる最小の凸多角形です。ポリゴンには凹角が含まれていないので、決して回転しません。
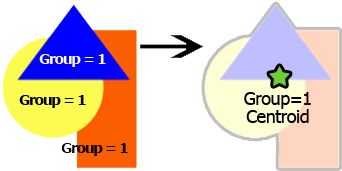
中心点を作成 : 空間オブジェクトのグループの地理的中心を識別します。
レポート
水平結合 : グループ内のすべてのレポートスニペットを、水平方向にレイアウトされたグループの単一のスニペットに結合します。
垂直結合 : グループ内のすべてのレポートスニペットを、垂直方向にレイアウトされたグループの単一のスニペットに結合します。