 Union Tool
Union Tool
 Union Tool
Union Tool
User Role Requirements
User Role* | Tool/Feature Access |
|---|---|
Full User | ✓ |
Basic User | ✓ |
*Applies to Alteryx One Professional and Enterprise Edition customers on Designer versions 2025.1+.
Use Union to combine 2 or more datasets on column names or positions. In the output, each column contains the rows from each input. You can configure how the columns stack or match up in the output.
Go to Alteryx Community Tool Mastery series to learn more about the Union tool.
One Tool Example
This tool has a One Tool Example. Go to Sample Workflows to learn how to access this and many other examples directly in Designer.
Tool Components

The Union tool has 2 anchors:
Input anchor: The input anchor connects to the data streams you want to unify. The 2 angle brackets on the input anchor indicate that it accepts multiple inputs.
Output anchor: The output anchor displays the output dataset.
Union Tool Behavior with AMP Engine
Starting in the 2026.1 Designer release, when input tools are directly connected to the Union tool, and one of the inputs is invalid, the Union tool returns partial results (data and metadata) from valid input connections via AMP (matching original Engine behavior), so you can avoid workflow failure when some inputs are invalid.
Configure the Tool
Mode: Choose the configuration mode. The default setting is Auto configure by name.
Auto configure by name: Stack data by column name.
Auto configure by position: Stack data by the column order in the stream.
Manually configure columns: Allows you to manually specify how to stack data. When you choose this method, the columns in each input are displayed (indicated by row #1, #2, etc.).
Important
When the mode is set to Manually configure columns, Alteryx assumes the configuration will not change between the configuration of the tool and the time the workflow is run. If anything is missing, an error occurs and the workflow will stop. For this reason, do not use this configuration mode in analytic apps and macros.
Properties: Auto Config
When Columns Differ
For the auto-configuration modes, you must select how to handle columns that differ.
In the first dropdown, choose your error handling option...
Error - Stop Processing Records: Throw an error in the Results window and stop processing records.
Warning - Continue Processing Records: Throw a warning in the Results window, but continue processing records.
Ignore - Continue Processing Records: Ignore columns that differ and continue processing records.
In the second dropdown, choose your output option...
Output All Fields: Output includes all columns. Null values populate empty columns.
Output Common Subset of Fields: Output includes only the columns that each input has in common.
Properties: Manually Configure Fields
For the manually configure columns mode, you have to configure your Output Columns in the Properties section.
To begin, your data streams are staggered horizontally and vertically so that the data from each input dataset are in different cells.
(Optional) In the top-right dropdown, you can begin by selecting either By Position or By Name. Select Reset to reset the columns. Use this option if you know that your data streams have some columns that match by either position or name.
Next, use the arrows to begin stacking your data. Select a cell and select the left arrow or right arrow to stack it with the data field it matches.
Select Non Blocking - Metainfo Will Not Change to pass data rows downstream without waiting for all inputs to send data. Do not use this mode if the upstream metainfo will change between configuration time and runtime.
Output Order
Under Output Order, check Set a Specific Output Order to specify which input dataset's data displays first in the output dataset. Once checked, select one of the data streams and select the up arrow or down arrow to reorder.
Important
The Output Order option can cause slower performance.
Understanding the Output
Two aspects of the Union tool output are important to understand: the column names and the data order.
Understanding Output Data Column Names
The column names that are used in the output dataset are pulled from the input stream with the first alphabetical/numerical value.
By default, your input data streams are labeled #1 and #2 based on the order you connected them to the Union tool input anchor. So, if the column names differ, the output dataset will use the column names from the #1 input dataset.
If you prefer to use the column names from the #2 input dataset, you can change the Name for the input connections. To do so, select the input streams and enter new values in the Name field of the connections. The output column names are taken from the connection with the first alphabetical/numerical value in its Name.
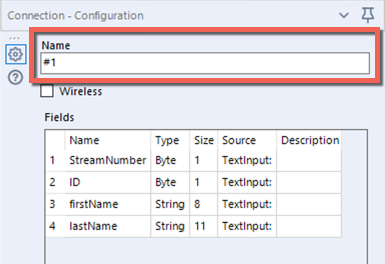
Understanding Output Data Order
The default output order often corresponds to the order you connected your input datasets to the Union tool input anchor but might vary. Go to the Output Order section to learn how to set the order of your output data.