Format de fichier de base de données Alteryx
Le format de fichier de base de données Alteryx YXDB est un type de fichier pouvant contenir des champs de données, des valeurs et des objets spatiaux. Le format YXDB est le type de fichier le plus efficace pour la lecture et l'écriture dans Alteryx, car il n'est pas limité en taille, il est compressé à la vitesse maximum et inclut des métadonnées supplémentaires faisant référence à la source des données et à leur mode de création. Le nombre de lignes et la taille des fichiers ne sont pas limités. Toutefois, une limite de taille de 2 Go s'applique aux cellules uniques dans un environnement 64 bits. Tous les produits Alteryx prennent en charge les fichiers YXDB en lecture et écriture.
Pourquoi YXDB serait-il le type de fichier d'entrée/sortie le plus efficace ?
Un fichier YXDB utilise des types de colonnes, des structures et des formats exactement identiques à ceux employés en interne par Alteryx ; ils fonctionnent donc de manière optimale avec ce programme. Ce format n'étant soumis à aucune limite de lignes, vous pouvez alors utiliser plus de 2 milliards d'enregistrements. Aucun autre format de fichier (à part les fichiers texte) ne prend en charge autant de lignes.
Un fichier YXDB est-il compressé ?
Oui, il est légèrement compressé pour optimiser la vitesse au détriment de la compression. Si vous possédez un index géographique, la compression se remarque à peine. Sans index spatial, la compression peut être assez importante.
Si je veux transformer des données dans un fichier contenant un objet spatial, mais qui n'interagit pas avec l'objet spatial, est-il toujours plus efficace d'utiliser un fichier YXDB ?
Oui, mais dans ce cas vous avez intérêt à désactiver l'index spatial dans les options avancées pour ne pas perdre de temps et d'espace à le créer inutilement.
Quelles sont les autres informations stockées dans un fichier YXDB ?
Lorsqu'Alteryx écrit dans un fichier YXDB, les données contenues dans les colonnes Source et Description sont enregistrées dans le fichier afin que vous sachiez toujours à l'avenir comment un champ a été créé ou que vous connaissiez la version des valeurs de données sous-jacentes. Pour consulter un exemple de ces métadonnées, voir l' outil Informations du champ .
Source : contient l'outil, le fichier ou le processus d'origine du champ. Elle peut également contenir des méta-informations supplémentaires, par exemple un jeu de données spécifique tiré d'un plug-in. Les outils rapportant des méta-informations sont les suivants : outil Entrée d'Allocate et outil Ajouter des données Allocate , outil CASS , outil Formule , outil Géocodeur de rue , et les outils utilisant des outils plus gourmands comme l' outil Zone de chalandise , l' outil Distance et l' outil Trouver le plus proche .
Description : peut contenir ou non des informations. Si les données sont ajoutées à partir d'un outil Allocate, le nom de champ descriptif, plus long, est indiqué ici. En outre, vous pouvez ajouter votre propre description de champ via l' outil Sélectionner . Ces informations restent associées au champ.
Exemple de cas d’utilisation
Problématique
J'ai 2 requêtes SQL et quelques workflows où le deuxième jeu de données reste le même et contient 3 millions d'enregistrements. Existe-t-il un moyen de réutiliser le deuxième jeu de données dans le même ou dans différents workflows afin qu'il n'ait pas à exécuter l'instruction Sélectionner sans cesse ?
Solution
Si vous avez besoin d'un stockage intermédiaire des données dans votre workflow, utilisez un outil Sortie de données et écrivez au format YXDB. Vous pouvez faire écrire votre premier workflow dans le fichier YXDB qui stocke toutes les données de votre requête. Ensuite, utilisez cet YXDB comme entrée de données pour vos autres workflows. De cette façon, vous pouvez travailler à partir du jeu de données statique pour le développement. Si jamais vous voulez passer le workflow à une connexion aux données en direct, vous pouvez simplement copier l' outil Entrée de données de l'autre workflow.
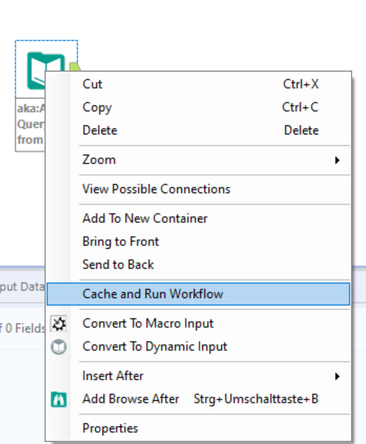
Sinon, si vous devez réutiliser des données dans un seul workflow, envisagez la fonctionnalité Mettre en cache et exécuter le workflow.