Opzioni formato file
Le opzioni di configurazione variano a seconda del formato di file o della connessione al database utilizzati per l'input o l'output dei dati. È possibile selezionare le opzioni del formato file in questi strumenti:
Opzione | Descrizione | Formati di file |
|---|---|---|
Consenti l'estrazione di file >2GB | Seleziona per consentire ad Alteryx di estrarre un file di dimensioni superiori a 2 GB. Per ulteriori informazioni, consulta le sezioni Supporto per file zip e Supporto per file Gzip. | .zip, *.gz, *.tgz |
Consenti l'accesso condiviso alla scrittura | Seleziona per leggere un file aperto che potrebbe essere in fase di aggiornamento. Questa opzione è destinata alla lettura dei log web. | |
Allega alla tabella esistente | Seleziona per aggiungere record a una tabella esistente. | .dbase, .sdf |
Aggiungi la mappa campo | Seleziona per aggiungere i campi e impostare la modalità di mappatura dei campi di output ai campi nella tabella OLEDB. | .mdb, .xls, .accdb, ODBC, OLEDB |
Pagina codice | Seleziona una tabella dei codici per convertire il testo all'interno dei dati di input o output. Per ulteriori informazioni, consulta la sezione Tabelle di codici. | .csv, .dbf, .flat, .json, .mid, .mif, .tab, .shp |
Crea campi Int32 come Binari | Seleziona per creare tutti i campi Int32 come valori binari a 32 bit (4 byte) nel database invece del formato di testo predefinito a 11 caratteri. Questa opzione non è supportata da tutti i lettori DBF. | .dbase |
Delimitatore | Seleziona il delimitatore di campo nei dati. Utilizza \0 per leggere o scrivere un file di testo senza delimitatore. Utilizza 0 quando i dati contengono due o più delimitatori per forzare Designer a leggere i dati come testo semplice. Utilizza lo strumento RegEx in modalità Tokenizza per analizzare i dati. | .csv, .txt |
Descrizione o file dati | Definisci il nome di un file .flat utilizzato come file di layout. | flat |
Non mostrare % completi | Seleziona questa opzione per disabilitare un report sullo stato della lettura del file in corso; ciò accelera il tempo di lettura. | |
Abilita compressione (Deflate) | Seleziona per generare un file .avro compresso. Viene utilizzato l'algoritmo deflate (simile a gzip) e dovrebbe essere supportato da altri strumenti compatibili con Avro, come Hive. La compressione aumenta il tempo di output, ma con file di dimensioni maggiori riduce il tempo di rete. | .avro |
Attiva il supporto FileTable di SQL Server | Seleziona per scrivere un file Excel in una tabella FileTable di Microsoft SQL Server | .xlsx |
Espandi le etichette del valore | Leggi e applica le etichette dei valori (chiave) ai dati. Questa opzione è selezionata per impostazione predefinita per i file SPSS e SAS. Per ulteriori informazioni, consulta la sezione Formati di file supportati per il trasferimento delle statistiche. Quando questa opzione non è selezionata, viene visualizzato solo la chiave valore. | .spss, .sas |
Lunghezza campo | Definisci la lunghezza massima del campo nei dati di input. | |
Formato di file | Seleziona il formato file dei dati. | Tutti i formati di output |
File in archivio | Modifica il file (o i file) in input. Per ulteriori informazioni, consulta la sezione Supporto per file zip. | .zip |
La prima riga contiene dati | Seleziona se la prima riga deve essere trattata come dati e non come intestazione. | .xlsx |
La prima riga contiene nomi di campo | Seleziona se la prima riga deve essere trattata come intestazione. | .csv |
Supporto Force SQL WChar | Seleziona per consentire alle colonne di caratteri di essere trattate come SQL_WCHAR, SQL_WVARCHAR o SQL_WLONGVARCHAR. | .oci, unicode.txt |
ID del tenant Purview. | Da utilizzare in combinazione con l'opzione ID etichetta sensibilità. Immetti l'ID del tenant Purview in cui desideri selezionare le etichette di sensibilità. Per ottenere l'ID etichetta e l'ID associato del tenant Purview, puoi rivolgerti al team IT o all'amministratore di Azure. Le etichette che richiedono la crittografia non sono supportate. | .xlsx, .xlsm |
Se le righe lunghe sono consentite | Utilizza il file .flat selezionato (impostazione predefinita) o sovrascrivi l'impostazione. | flat |
Se le linee corte sono consentite | Utilizza il file .flat selezionato (impostazione predefinita) o sovrascrivi l'impostazione. | flat |
Ignora i delimitatori in | Seleziona un'opzione: Virgolette: ignora i delimitatori tra virgolette. Virgolette singole: ignora i delimitatori tra virgolette singole. Auto: ignora i delimitatori rilevati automaticamente. Nessuno: non ignorare i delimitatori. | |
Ignora gli errori XML e continua | Ignora la formattazione XML errata e continua a eseguire il flusso di lavoro. Per ulteriori informazioni, consulta la sezione Lettura di XML. | .xml |
Stile fine riga | Definisci il carattere o la sequenza di caratteri che indica la fine di una riga di testo. | .csv, .flat |
Record max per file | Definisci il numero di record da generare in un singolo file. Quando i dati contengono più record, vengono creati più file e denominati in sequenza. | tutti i formati |
Nessun indice spaziale | Seleziona per disattivare l'indice spaziale. Utilizza questa opzione solo quando scrivi file temporanei di grandi dimensioni che non verranno utilizzati nelle operazioni spaziali. Questa opzione consente di scrivere più velocemente file più piccoli. | .yxdb |
Output di tutti i campi come sequenze | Seleziona per convertire i campi in entrata in tipo di dati stringa; in questo modo si evitano gli errori di conversione quando il tipo di dati è errato nei file .dbf. | .dbf |
Nome del file di output come Campo | Seleziona per aggiungere un campo con il nome o il percorso del file a ciascun record. | |
Opzioni di output | Seleziona un'opzione di output: Crea nuovo foglio: consente di creare un nuovo foglio, ma non sovrascrive un foglio esistente. Aggiungi al foglio esistente: consente di aggiungere i dati a un foglio esistente in modo che l'output sia costituito da dati nuovi e precedenti. Sovrascrivi foglio o intervallo: consente di eliminare i dati nel foglio o nell'intervallo selezionato e scrive i dati nel foglio o nell'intervallo con il nome selezionato. Non utilizzare l'opzione precedente se il file Excel contiene formule, tabelle, grafici e immagini, poiché questi elementi possono essere danneggiati. Sovrascrivi file (rimuovi): consente di eliminare il file esistente e di creare un nuovo file. | .xlsx, .xlsm (tramite driver .xlsx di Alteryx) |
Opzioni di output | Seleziona un'opzione di output: Crea nuova tabella: consente di creare una nuova tabella, ma non sovrascrive una tabella. Aggiungi a esistente: consente di aggiungere i dati a una tabella esistente in modo che l'output sia costituito da record precedenti più record successivi. Elimina dati e aggiungi: consente di eliminare tutti i record originali dalla tabella e di aggiungere i dati alla tabella esistente. Sovrascrivi tabella (Rilascia): consente di rimuovere la tabella esistente e di crearne una nuova. | .accdb, .mdb, .tde, .xls, .xlsx (tramite driver .xlsx legacy), .oci, OLEDB, ODBC |
Opzioni di output | Seleziona un'opzione: Aggiornamento, avvisa in caso di errore: aggiorna i record esistenti utilizzando l'output e avverte se non è stato possibile aggiornare un record. Aggiornamento, errore in caso di fallimento: aggiorna i record esistenti utilizzando l'output e interrompe l'elaborazione se non è stato possibile aggiornare un record. Aggiornamento, inserisci se nuovo: aggiorna i record esistenti utilizzando l'output e inserisce nuovi record se non erano presenti nella tabella del database, oltre a interrompere l'elaborazione qualora non sia stato possibile aggiornare un record. Affinché l'aggiornamento funzioni, è necessario includere il campo della chiave primaria. Quando sono presenti più record con la stessa chiave primaria, e non si verificano altri errori SQL, il nuovo record aggiorna quello precedente nel database. Utilizza lo strumento Univoco per verificare la presenza di più chiavi primarie prima di scrivere nel database. | .oci, OLEDB, ODBC |
Sovrascrivi la tabella esistente | Selezionata per impostazione predefinita, questa opzione sovrascrive un tipo di file esistente con lo stesso nome. | .mdb* |
Analizza il file selezionato come | Modifica il formato di analisi del file. | .zip |
Analizza valore come stringa | Seleziona per analizzare i dati di output come stringa; se non è selezionata, i dati vengono analizzati in base al tipo. | |
Password | Seleziona la modalità di visualizzazione della password nella finestra Configurazione: Nascondi (impostazione predefinita), Crittografa per computer, Crittografa per l'utente. | |
Creazione successiva di istruzione SQL* | Definisci un'istruzione SQL da eseguire tramite il driver ODBC/OLEDB dopo la creazione della tabella di output. | .mdb, .mdb*, .oci, .accdb, ODBC, OLEDB |
Creazione preliminare istruzione SQL* | Definisci un'istruzione SQL da eseguire tramite il driver ODBC/OLEDB prima della creazione della tabella di output. | .mdb, .mdb*, .oci, .accdb, ODBC, OLEDB |
Mantieni la formattazione in Sovrascrivi (Intervallo richiesto) | Importante Per mantenere la formattazione quando si sovrascrive un foglio o un intervallo, la formattazione deve essere applicata a livello di cella in Excel. È possibile eseguire questa operazione per ogni singola cella o selezionando un intervallo di celle. Se si applica la formattazione a livello di riga o colonna, questa non verrà mantenuta durante la sovrascrittura. Mantieni la formattazione di Excel per l'intervallo che sovrascrivi. Non utilizzare questa opzione se il file Excel contiene formule, tabelle, grafici e immagini, poiché questi elementi possono essere danneggiati. Quando selezioni questa opzione, devi anche:
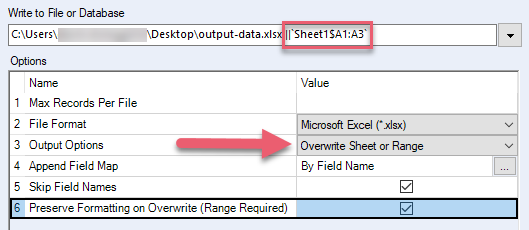 | .xlsx, .xlsm (tramite driver .xlsx di Alteryx) |
Proiezione | Definisci il progetto di output. Per impostazione predefinita, il campo Proiezione è vuoto e l'output viene generato in WGS 84. Per ulteriori informazioni, consulta la sezione Supporto delle proiezioni. | .mid, .mif, .tab, .shp, .oci, .mdb |
Virgolette nei campi di output | Scegli un'opzione per racchiudere tra virgolette i campi di output: Automatiche: consente di racchiudere tra virgolette i campi che hanno una virgoletta singola o doppia e i campi che contengono delimitatori. Sempre: consente di racchiudere tra virgolette ciascun campo. Mai: non inserisce virgolette. | |
Leggi oggetti spaziali come centroidi | Per i dati con oggetti poligono, seleziona questa opzione per utilizzare il centroide del poligono come oggetto spaziale. | .mdb*, .tab, .oci, .sdf, .shp, .geo, .kml, .mid, .mif |
Limite record | Seleziona per limitare i record letti dai dati di input. Se 0, vengono restituiti tutti i record. Se -1, vengono restituiti solo i metadati. | |
Restituisci valori figlio | Selezionata per impostazione predefinita per generare i valori figlio dell'elemento radice o di un Nome elemento figlio XML specificato. Per ulteriori informazioni, consulta la sezione Lettura di XML. | .xml |
Restituisci XML esterno | Seleziona per generare il formato del tag XML di un Nome elemento figlio XML specificato. Deseleziona per generare il formato dei figli dell'elemento radice. Per ulteriori informazioni, consulta la sezione Lettura di XML. | .xml |
Restituisci elemento radice | Seleziona per generare l'elemento padre che racchiude tutti gli altri elementi. Per ulteriori informazioni, consulta la sezione Lettura di XML. | .xml |
Esegui PreSQL alla configurazione dello strumento | Selezionata per impostazione predefinita, questa opzione esegue le istruzioni preSQL quando uno strumento viene inserito in un flusso di lavoro. Deseleziona la casella di controllo per eseguire istruzioni preSQL quando viene eseguito il flusso di lavoro. | |
Salva Origine e Descrizione | Questa opzione predefinita consente di includere i dati di origine e descrizione nelle metainformazioni. Deseleziona l'opzione per escludere i dati di origine e descrizione. | |
Cerca SubDirs | Usa questa opzione per inserire più input se i file di dati si trovano in una sottodirectory e contengono la stessa struttura, gli stessi nomi di campo, la stessa lunghezza e gli stessi tipi di dati. | |
ID etichetta sensibilità | Utilizza questa opzione per immettere l'ID dell'etichetta di sensibilità che desideri applicare al file di output. Per ottenere l'ID etichetta e l'ID associato del tenant Purview, puoi rivolgerti al team IT o all'amministratore di Azure. Le etichette che richiedono la crittografia non sono supportate. | .xlsx, .xlsm |
Set di caratteri della sessione | Per impostazione predefinita, Teradata Bulk Loader utilizza la codifica UTF8, che non si adatta al set di caratteri latini esteso utilizzato da Teradata per i caratteri diacritici. È stata aggiunta la nuova opzione Session Character Set (Set di caratteri sessione) allo strumento Output per consentire la modifica del set di caratteri. | Teradata ODBC |
Mostra messaggio di transazione | Seleziona per visualizzare nella finestra dei risultati un messaggio per ogni transazione. Ogni messaggio riporta la somma dei record scritti fino a quella transazione. | |
Dimensione dei blocchi di caricamento in blocco (da 1 MB a 102400 MB) | Le dimensioni delle sezioni di caricamento in blocco da scrivere. L'impostazione predefinita è 128 MB. | |
Salta nomi campo | Quando selezionata, questa opzione consente di scrivere i dati solo in un foglio o in un intervallo. | .xlsx, .xlsm |
Campo oggetto spaziale | Definisci l'oggetto spaziale da includere nell'output. I file spaziali possono contenere un solo oggetto spaziale per record. Alteryx non supporta la lettura o la scrittura di più tipi di geometria in un singolo file. | .mdb*, .tab, .oci, .sdf, .shp, .geo, .kml, .mid, .mif |
Avvia l'importazione di dati online | Definisci un numero di riga da cui iniziare a leggere i dati. Per impostazione predefinita, l'inizio è alla riga 1. | .csv, .xlsx |
Supporta valori nulli | Seleziona per generare un file .avro con valori Null. Questa opzione di output unisce i campi con un ramo null e un ramo valore. Se il valore Alteryx è Null, l'output utilizzerà il ramo null; in caso contrario, verrà utilizzato il ramo valore. Quando questa opzione non è selezionata, tutti i campi di output vengono scritti come i rispettivi tipi .avro nativi (nessuna unione). I campi Alteryx Null vengono scritti come il rispettivo valore predefinito. Utilizza lo strumento Formula per gestire i valori Null con valori "noti" in modo che i valori possano essere letti in Hadoop. | .avro |
Elimina output in caso di assenza di record | Seleziona questa opzione in modo che lo strumento Dati di output non generi un file in assenza di record. Ciò significa, ad esempio, che una scheda vuota con etichette di intestazione non viene riportata in Excel quando non vi sono record da scrivere. Questo messaggio informativo viene visualizzato quando il file di output non viene generato:
| Sono supportati i formati CSV, XLSX, XLSM e YXDB. |
Tipo di tabella | Utilizza questa opzione per selezionare la memorizzazione delle tabelle come predefinite del sistema, a colonne o a righe. Le posizioni di memorizzazione delle tabelle rappresentano il modo in cui vengono memorizzati i dati. L'impostazione predefinita del sistema rispetta la posizione di memorizzazione delle tabelle del database sottostante. Noterai un calo delle prestazioni quando crei una tabella di memorizzazione a colonne rispetto a una a righe. | SAP HANA ODBC |
Stile SQL di Tabella/Nome campo | SelezionaTra virgolette or Nessuno. L'opzione Tra virgolette utilizza l'identificatore delimitato per il tipo di database. | .oci, OLEDB, OBDC, |
Tabella o Query | Se i dati contengono più tabelle, definisci la tabella da immettere o selezionare per creare una query. Per ulteriori informazioni, accedi alla finestra Scegli tabella o Specifica query. | |
Acquisisci nome file da campo | Seleziona un'opzione per scrivere un file separato per ogni valore di un determinato campo: Aggiungi suffisso a nome file/tabella: aggiunge il nome del campo selezionato alla fine del nome della tabella. Anteponi prefisso al nome file/tabella: antepone il nome del campo selezionato all'inizio del nome della tabella. Cambia nome file: modifica il nome del file con il nome del campo selezionato. Modifica intero percorso del file: modifica il nome del file con il nome del campo selezionato che contiene un percorso completo. | Tutti i formati di output |
Grandezza transazione | Definisci il numero di record alla volta da scrivere in un database. I record vengono assegnati in batch inferiori a 655360 byte o grandezza della transazione * grandezza record. La grandezza del record viene calcolata in base alle dimensioni del campo specificate nell'output del flusso di lavoro. Se la grandezza del record è superiore a 655360 byte, la grandezza della transazione viene impostata automaticamente su 1. Per gli aggiornamenti, la grandezza della transazione è sempre 1. Per impostazione predefinita, la grandezza della transazione è 0, ovvero tutti i record. Imposta i record almeno su 1000, poiché il database crea un file di log temporaneo per ogni transazione che potrebbe riempire rapidamente lo spazio temporaneo. | .oci, OLEDB, ODBC |
Tratta gli errori come avvisi | Seleziona questa opzione per immettere dati di input con record non conformi alla struttura dei dati. In genere gli errori causano la mancata riuscita dell'input; questa opzione evita di incorrere in questo problema trattando gli errori come avvisi. | |
Frammenta gli spazi bianchi | Utilizza il file .flat selezionato (impostazione predefinita) o sovrascrivi l'impostazione. | flat |
Quale tipo di fine riga usare | Utilizza il file .flat selezionato (impostazione predefinita) o sovrascrivi l'impostazione. | flat |
Scrivi BOM | Seleziona per includere il byte order mark (BOM) nell'output o deseleziona per l'output senza un byte order mark. | .csv |